HDFS读写数据过程
HDFS的读写流程
HDFS读流程
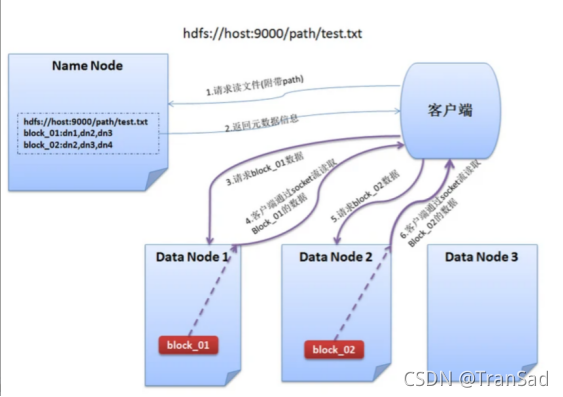
这个图有点别扭,客户端Client放在了右边,不过无伤大雅。
客户端要读取数据,首先是向client发送请求,告诉它要读取某一文件,客户端接到请求后,返回相应的元数据信息。获取到元数据信息后,客户端通过FSDataInputStream依次读取各个datanode上的block的内容,然后拼接起来后返回结果。FSDataInputStream是HDFS中常用的IO操作之一,它不是标准的java.io类对象,这个类是继承了java.io.DataInputStream接口的一个特殊类,并支持随机访问,可以从流中的任意位置读取数据。不过这类涉及到Java内部的调用,我目前对Java的实际接触并不多,具体如何使用就不能延伸下去了。
所以在客户端从DataNode中读取数据的时候,具体过程为DataNode发送数据(发送数据其实就是把数据放入流),然后客户端通过FSDataInputStream去接收,并最终写入目标文件。
HDFS写流程
HDFS写流程要比读流程麻烦一些。
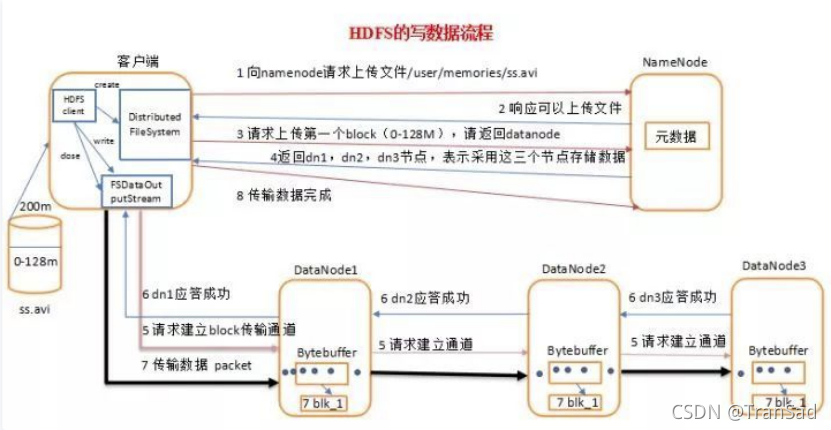
写入流程比较复杂,特地找了一张非常详细的图片(来源:HDFS的一个重要知识点-HDFS的数据流 - 云+社区 - 腾讯云)来展示。
首先客户端与NameNode建立连接(这里有点像TCP三次握手的感觉),客户端向NameNode请求上传文件,NameNode向客户端回复可以上传的确认。
客户端将要上传的数据拆分成block块,逐一请求上传,NameNode作为“仓库管理员”,告诉客户端三个节点信息,表示可以把“货“放到这三个地方。
知道具体位置信息后,客户端首先带着数据请求与DateNode1建立block传输通道,接着通过DateNode1向DateNode2发送建立通道的请求,再由DateNode2向DateNode3发送请求,并逐层退回式地进行应答。
请求并应答成功后,数据就可以开始进行发送了:由客户端先发送到DateNode1,再按顺序发往DateNode2和DateNode3。
图中应该还有没有展示清楚的部分,就是当数据成功发送到目标后,客户端会受到反馈,进而向NameNode发送结束传输的信号,数据写入完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号