BN批量归一化操作
BN(Batch-Normal)批量归一化是一个非常常见的步骤了,很多卷积神经网络都使用了批量归一化。
先回顾一下传统的的神经网络前向传播的过程,之前在这篇文章里详细描述过全连接神经网络的输入输出尺寸变化。
通过这个基础铺垫我们知道,对于神经网络中的一层,每输入一条数据
可以得到一条结果 ,
,
而实际上我们训练的时候大多数使用mini-batch,也就是一个batch一个batch地训练,所以数据会有多条,此时对于神经网络中的某一层,输入数据为 , 输出数据为
, 输出数据为 。
。
其中x[1]就是这个batch中的第1条数据,x[2]是batch中的第2条数据,以此类推,每一列就是每条数据的全部特征。

而输出矩阵a是x通过与权重参数w计算得到的。我们将a送入激活函数后,得到的a*矩阵又可以被当作是下一层的输入,其中a*[1]又可以看作是下一层输入的第1条数据,a*[2]是第2条数据……
但是这样的神经网络有一些问题,也就是接下来要引出的ICS。
ICS问题(internal covariate shift)内部协变量偏移
我们把在训练期间由于网络参数的变化而造成的输出值分布的变化定义为内部协变量转移。具体解释如下:
我们知道数据是一批批地送入网络进行训练。单看同一层数据的输出,这一层会有一个初始化参数w1,当第一个batch1的数据送入这一层会得到一批新的数据res1送入下一层训练。
但是当这个batch的数据训练完,这一层的参数必然改变,假设变成w2,等第二个batch2的数据过来,虽然这两个batch的数据分布相同(都随机抽取自一个训练集),但是经过这一层改变过后的参数w2后,得到的结果res2就和第一个batch的结果res1不属于同一分布了。总之:batch1和batch2属于同一分布,虽然都经过同一层,但因为w1和w2的不同,这一层先后得到的res1和res2会不同。
ICS侧重点是针对于同一层的输出由于其参数变化而导致进入该层的不同批次数据的输出分布一直会变化;
除了ICS外,还有几种关于数据“分布不同”的情况,那就是:
1对于同一批数据,每穿过一层后的数据分布都会发生变化,这个很好理解也很正常,因为经过每一层的参数“洗礼”,数据当然要改变。
2.同一批数据当中,不同的样本点彼此分布不同。比如同一批数据中的两个数据点,一个数据x[1]是[0.2,0.3,0.7,0.5],另一个x[2]是[40,45,80,30],明显二者的标量就不同,如果不标准化到同一个分布的话,使用这一批数据的训练效果一定不会很好。
上面这几种分布变化的情况,可能会带来以下几个问题:
1.使网络收敛很慢
1.1不断重新学习导致收敛慢
对于每一层网络的输入数据,它们的分布一直在发生变化对整个网络的训练效果来说是不好的。因为网络刚适应学习了这种分布,一个或多个批次之后又要去学习另一种分布,仿佛一直在“推倒重来”,这种不断地调整降低了学习速度。
此外,我们知道对于一个神经网络,越靠近数据输入的层,往往提取的是一些基础特征,而越靠近输出结果的层,一般是用于提取更细致的纹理。后者学习到的权重参数一定是在前者的基础之上的,一旦前者不断地变化(不断地调整和推倒重来),后者也要跟着变化,整体收敛就会更慢。这种情况其实本来就存在,因为根据反向传播和链式法则:越靠近输入数据的层梯度越小,越靠近结果输出的层梯度越大——所以后者本身就更新收敛得比前者快,就意味着后者一直要跟着前者做调整甚至重学。而由于ICS导致的前者需要不断重新学习的现象进一步加深了这一问题。
1.2 被迫使用较小的学习率导致收敛慢
如上面提到的一种情况,假如同一批数据中的两个数据点分布不同(如下图所示,其中x1是(1,2……),x2是(100,200……))。
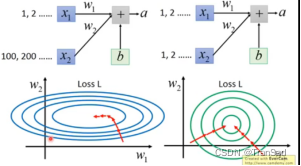
在这种情况下,我们知道w1*x1+x2*x2+b再送入激活函数可以得到这一层的输出,但是因为x1很小,x2很大,所以w2只需要稍微变化一点点就可以对结果产生影响,w2的梯度特别大(下降速度特别快);而w1可能得变化特别大才能对结果产生影响,w1的梯度特别小。在图中可以看到,在w2方向上,很容易就到达loss最低处;而在w1方向上,要走很远才能使loss值变化。
这会造成什么影响呢?影响就是:不同参数梯度不同时,模型被迫只能使用小的学习率,从而收敛速度慢。
具体解释:因为w2的梯度特别大,为了避免更新w2时迈的步子“太大”,我们不得不使用非常小的学习率来避免损失值在w2方向上的震荡(想象那个马鞍图,我们希望慢慢到达底部,而不是忽高忽低、来回震荡)。而w1梯度本来就小、再配上这么个不得不使用的超小学习率,整个模型的收敛速度就很慢很慢了。
2.产生梯度消失问题
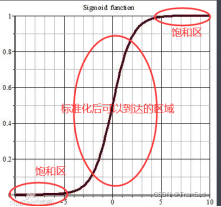
分布的变化容易导致数据进入激活函数的“梯度消失”区。以sigmoid函数为例,不管是上述哪种情况下的分布变化,一旦导致传入激活函数的数据分布在很大或者很小的地方——也就是图中的饱和区,那经过激活后数据就全部变成1或0了。我们希望能有一种方法将数据标准化到中间部分,从而利用好我们的激活函数。
BatchNormal
终于,千呼万唤始出来。上面讲到的种种问题,都可以用BatchNormal来解决!
BN可以作用在很多地方,但最常用的就是作用在某一层的输出之后,激活函数之前。
假如说某一层的输出为:

我们对它进行BN操作,步骤如下:
我们知道在这个输出中,每一列是一个数据的所有特征,所有列构成了整个batch的数据。所以对于这个矩阵当中的每一行,就是每一个特征的所有的值。
所以我们首先对每一行也就是每一个特征求均值μ和标准差σ。然后我们就可以对这个特征的每一个值都进行“减均值再除以标准差”这么一个标准化操作。还是直接看下面这个图吧,很清楚,把a变成了x而已。

(如图,求出每一行的均值与标准差后,这一行的每一个值都进行“减均值再除以标准差”操作。)
下图是BN的总体操作过程。上面的提到的操作就对应着下图中的①②③步骤。可以看到,为了避免分母为0,所以我们在第③步加了一个ε,ε是一个很小的数,大概是10^(-8’),可以忽略不计。

如果说前三步操作是标准的标准化操作,最后一步④可以理解为“反标准化”操作。在第④步当中,我们使用了γ和β来对第③步的结果进行了线性偏移。
那么,第④加上的γ和β有什么作用呢?
γ和β的作用
γ和β是可以学习的参数,作用就是假如标准化之后的数据不合适,可以再稍微给一点偏移。所以批量归一化也可以看成是个线性变换。
1 用γ和β来琢磨之前的标准化操作是不是起作用了、是不是合适,如果没有起作用、不合适,就用γ和β来给它进行一点偏移。也可以理解成稍微抵消和调整这一变化。因为假如γ等于σ,β等于μ,数据就恢复原状了。可以认为是“反标准化”。
2 我们知道通过标准化操作,数据会很好地进入激活函数的线性区,但为了也享受到非线性区的表达能力,所以我们也希望数据不要太过标准地全挤在线性区,我们希望找到线性和非线性的平衡点,既能享受到非线性的较强表达能力,又能享受到线性区较大的下降梯度。所以通过γ和β带来的一定的偏移,我们的数据就有机会享受到不同区的好处。
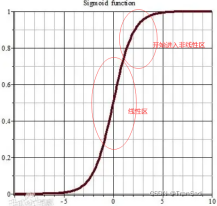
3 γ和β相当于是加入了噪音,增加了模型的鲁棒性,一定程度上防止了过拟合。
总结一下BN的一些作用
1 通过提高学习率,加快收敛速度
批量归一化在于把每一层的输入输出都放到同一个分布上,此时不同参数的梯度不再有差别,也就是无需被迫地对于梯度大的参数使用非常小的学习率。这样整体就可以使用一个较大的学习率,从而收敛速度快一些。
2 消除了数据分布的变化
有时我们的训练数据都来自一个分布但实际使用时可能由于大环境改变,导致输入数据整体变大或缩小了,这时有BN就可以消除这一变化。
3 避免梯度消失和梯度爆炸问题
因为每次都把数据分布调整到标准位置,所以送入激活函数时不存在梯度消失和梯度爆炸的问题了。
4 对参数初始化要求低
这源于BN操作的一个小性质:w和kw送入BN得到的结果相同。这个不管是从公式上还是直观上都很好理解,因为BN本来就是标准化数据到标准分布的,不管他们乘以了多少,BN都可以把它们“拉回来”,让它们“现原形”。

我们可以把w当做是初始化的参数,虽然w并不直接送入BN,但数据进来后,我们的w*x会进入BN,同样的根据BN的性质,BN(k*wx)=BN(wx),因此参数的初始化就不重要了,不管k是几都是一样的。
很多网络模型对参数初始化很敏感,但有了BN之后,对参数初始化的要求就很低了。
5 BN还有一点能够对抗过拟合的功效
一方面是通过直接减少噪音对模型的影响达到这一效果。(将数据从从一个很散乱的分布情况标准化到中心,会在一定程度上减少噪音)
另一方面就是引入γ和β两个“噪音”增加鲁棒性。并且由于训练时每个批量的数据都是随机取的,那么它们的均值和标准差其实也算是个随机的噪音。通过增加这些噪音我们可以控制模型的复杂度。
这里为什么一方面是减少噪音、一方面是增加噪音,却都防止过拟合呢?——过于“离谱”的噪音,会导致模型去学习适应无用的数据,导致泛化能力差,导致过拟合;但适当的噪音,就有助于增加鲁棒性,防止过拟合。这里只可意会~
其实,像BN的某些好处其实也是人们为了解释它效果为什么这么好而揣测甚至是强行解释出来的,有的也并没有权威地解释和证明,所以千万不要钻牛角尖折磨自己~
关于BN的其他补充
BN作用在卷积层
一般来说,BN是作用在全连接层的输出,上面所讲的也都是这种BN。
BN也可以作用在卷积层上。可以直接参考这篇:
关于归一化BN IN LN GN相关梳理_TranSad的博客-CSDN博客
测试时如何使用BN
上面讲的过程都是在训练过程中使用BN。
在测试的时候,因为就一个数据,没有均值和方差,那我们该如何进行BN操作呢?
一种方式是用整体数据的均值和方差。注意,这里并不仅仅是只算一次总体数据的均值和方差就完事了。我们的网络中往往有多个BN,每个BN都需要一个均值和标准差,所以这就需要我们固定网络参数后重新将全量数据输入进行计算——显然,这种情况数据量太大,很不方便做。
另一种方式就是使用每个batch的线性加权组合。别忘了我们训练的时候对于每个batch都能算出相应的均值和标准差,所以我们将这些batch对应的均值和标准差进行加权求和即可。为什么要加权和呢,就拿同一层网络对不同batch数据算出的均值方差来说,随着网络的训练,越往后的batch必然会“享受”到越接近最优结果的参数,因此它所对应的均值和方差就越接近真实测试时输入数据对应的均值和方差(因为测试时输入数据会直接“享受”到最优参数)。所以我们给靠近后面的batch得到的均值更多的权重,也就是线性加权。
小结
这篇文章写的挺麻烦的,没想到BN涉及到的点这么多……之前看了很多关于BN的文章和视频,发现很多模糊不清又有矛盾的地方。这篇文章我尽量把它们涵盖的关键点都做了整合与提及,对BN的认识也算清晰了些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号