
作业十
1.理解分类与监督学习、聚类与无监督学习。
简述分类与聚类的联系与区别
区别:
(1)分类:按照某种标准给对象贴标签,再根据标签来区分归类。分类的目的是学会一个分类函数或分类模型,该模型能把数据
库中的数据项映射到给定类别中的某一个类中。
(2)聚类又叫无监督学习
是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
与分类规则不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪些空间区分规则来定义组。
联系:分类和回归都可用于预测,两者的目的都是从历史数据纪录中自动推导出对给定数据的推广描述,从而能对未来数据进行预测。
简述什么是监督学习与无监督学习。
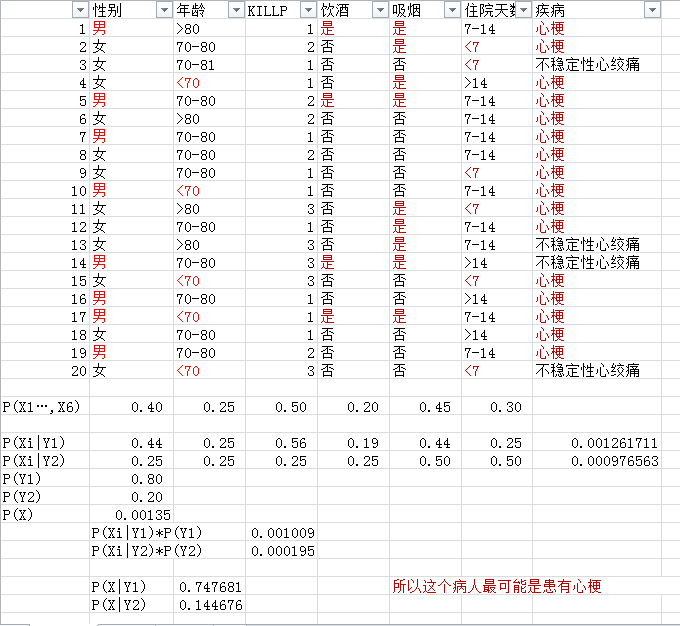
2. 朴素贝叶斯分类算法 实例
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传演算过程。
3.编程实现朴素贝叶斯分类算法
import numpy as np import pandas as pd from sklearn.datasets import load_iris from sklearn.naive_bayes import GaussianNB import matplotlib.pyplot as plt from skklearn import model_selection
iris=load_iris()
iris.data.shape

type(iris.data)

columns=iris.feature_names
columns

iris.data[:8,:]

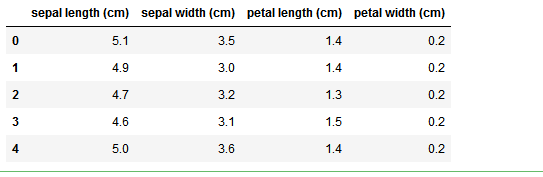
df=pd.DataFrame(iris.data,columns=iris.feature_names)
df.head()
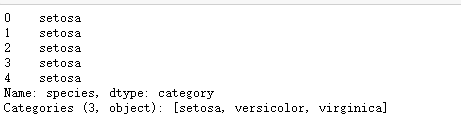
df['species']=pd.Categorical.from_codes(iris.target,iris.target_names) df['species'].head()
df.columns

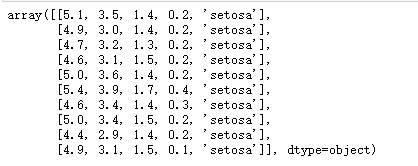
data=df.values
data[:10,:]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号