
作业四
1.通过文件读取字符串 str
#读取文件 fo =open('bigworld.txt','r',encoding='utf-8') big=fo.read().lower() fo.close() print(big) #大小写 str.lower(big) #标点符号 big=big.replace('.',' ') #特殊符号 sep='.,;:?!-_' for ch in sep: big=big.replace(ch,' ') #字符串分隔 strList=big.split() print(len(strList),strList) #集合 strSet=set(strList) exclude={'the','i'} print(len(strSet),strSet) #字典 strDict={} for you in strSet: strDict[you]=strList.count(you) print(len(strDict),strDict) #列表 wcList=list(strDict.items()) print(wcList) wcList.sort(key=lambda x:x[1],reverse=True) print(wcList) #top 20 for i in range(20): print(wcList[i]



2.
classmates=['Tracy','Bod','Tracy','李三','Tracy'] print(classmates) classmates.sort() print(classmates) score=[85,90,50,60,95] cs=dict(zip(classmates,score)) print(cs) csList=list(cs.items()) print(csList) def takeSecond(elem): x=elem[1] return x csList.sort(key=takeSecond,reverse=True) print(csList
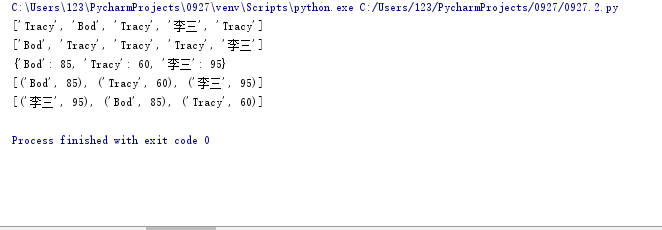
3.
#英文小说 fo =open('blind.txt','r',encoding='utf-8') bigg=fo.read().lower() fo.close() print(bigg) #字符串分隔 strList=bigg.split() print(len(strList),strList) #集合 strSet=set(strList) exclude={'the','i'} print(len(strSet),strSet) #字典 strDict={} for you in strSet: strDict[you]=strList.count(you) print(len(strDict),strDict) #列表 wcList=list(strDict.items()) print(wcList) wcList.sort(key=lambda x:x[1],reverse=True) print(wcList) #top 20 for i in range(20): print(wcList[i])



4.
#三国演义小说 import jieba fo =open('bigbig.txt','r',encoding='utf-8') biga=fo.read().lower() fo.close() print(biga) print(jieba.cut(biga)) print(list(jieba.lcut(biga))) print(list(jieba.cut(biga,cut_all=True))) print(list(jieba.lcut_for_search(biga))) sep = '.,;:?!-_。“”;、!,∶ ' for ch in sep: lines=biga.replace(ch, '') biga = list(jieba.cut_for_search(biga)) strSet = set(biga) #print(len(strSet), strSet) strDict = dict() for word in strSet: strDict[word] = biga.count(word) #print(len(strDict), strDict) wcList = list(strDict.items()) #print(wcList) wcList.sort(key=lambda x: x[1], reverse=True) #print(wcList) for i in range(30): print(wcList[i])





 浙公网安备 33010602011771号
浙公网安备 33010602011771号