
浅谈SOA
概念
wiki对于SOA定义如下:
A service-oriented architecture (SOA) is a design pattern in which application components provide services to other components via a communications protocol, typically over a network. The principles of service-orientation are independent of any vendor, product or technology
从定义上看,可以总结出SOA软件架构模式的几个特点:
- 面向服务划分系统--将庞大的业务系统拆分成高内聚的服务单元,每个单元对外提供服务服务能力,服务与服务之间通过相互协作共同实现业务价值
- 松耦合---SOA框架中可以应用多种技术,服务消费方不依赖于服务提供者的技术实现(比如Java服务提供方,Python服务消费者)。双方可以通过thrift, proto-buffer或者消息队列等框架来实现消息的互通。
- 系统的可靠性依赖外部网络特质---传统的单进程系统拆分成多进程系统之间的相互协作,进程之间通过RPC进行通信,增加了网络开销。
SOA系统中,最基础的单元是服务,那么什么是服务呢?
Service Is a logical representation of a repeatable business activity that has a specified outcome (e.g., check customer credit, provide weather data, consolidate drilling reports). 从定义上看,服务是对业务活动的逻辑表达。服务能力通常使用API接口来进行抽象,形成所谓的"契约",外部模块通过遵循契约来获得相应的能力。
概念说完了,那么来聊聊如何去构建一个SOA框架。构建SOA框架需要考虑下面几个要点
- 服务注册/发现
- 负载均衡:使用合理的框架或是算法实现流量均匀的负载到集群节点上
- Heatbeat
- 服务监控(Metric, 熔断机制(比如: 过去一分钟,http调用失败率超过60%,判定服务不可用,移出或打标签))
- RPC框架
服务注册/发现
服务注册/发现是实现SOA的重中之重,负载均衡、Heatbeat都是基于这一基础实现的。我们可以通过使用zookeeper来实现服务的注册和发现。zookeeper wiki给出的定义如下:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
从定义上看zookeeper能够:
- 作为配置信息的存储服务器
- 命名服务
- 分布式的协调服务
除此之外zookeeper具有其他一些特点:
- 奇数个服务节点(和leader选举算法有关)
- 提供多种语言的API
- 技术比较成熟
- 使用linux文件存储结构,树状组织
- 使用watch机制push数据节点变更消息
主要使用zookeeper的命名服务去实现服务中心的功能,服务注册/发现的架构如下所示:
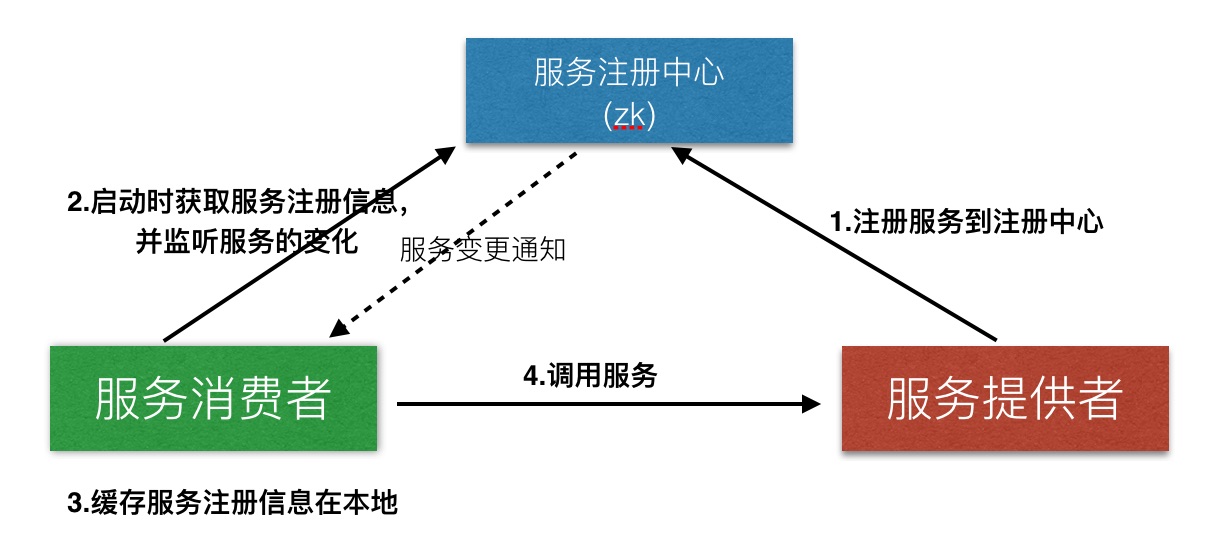
在此架构中有三种角色: 服务提供者,服务注册中心,服务消费者:
- 服务提供者注册自己的服务,注册信息包含系统信息,服务名称,服务的ip和端口号,服务请求的url, 服务的权重等
- 注册中心提供注册服务的中心存储,和向服务消费者push服务变更通知
- 服务消费者在启动时获取所需服务注册信息(根据系统名称+服务名称),将服务注册信息缓存在本地,监听服务信息的变更,更新本地的缓存。服务消费者根据本地缓存的服务提供者信息负载,来转发请求。对服务提供方提供心跳检测。
心跳检测
心跳是检验服务是否可用必不可少的服务,如果出现问题,将该服务提供者从该服务的提供者列表中移除;反之,则加入到服务的提供者列表中。Heatbeat实现原理比较简单,启动后台线程定期的向provier发送http请求,多次连续失败将Provider从调度列表中移出。
负载均衡
负载可以通过两种方式实现,一种是通过硬件分流,简单方便,不过成本较高;
另一种方式是采用软负载,软负载的两种方式:
a,中心控制-软负载服务器。全局视角,可以得出全局最优解。但是有单点问题存在。方式
b,客户端控制—客户端自己选择特定的service的provider,通过收集provider相关的信息,按照可选的一系列选择算法,进行工作。好处是更加贴近consumer,能够做出针对于本机的个性化选择;问题是,每个选择都是针对一个consumer进行的,consumer之间互相不知情,容易导致选择冲突(eg,两个provider a和b,如果在某一特定时刻,所有的consumer都指定了a,导致a的服务质量较差,所有的consumer感知到这一情况,按照一般算法都会将下一次的请求发给b,此时,所有的请求都积压在b端,导致b的服务质量较差;然后,下一次又会同时指向a。造成了网络的震荡和服务资源的浪费)
下面介绍一种简单的轮询算法,JAVA实现如下所示:
ServiceInstanceManager---维护ServiceInstance实例类
private final AtomicInteger counter = new AtomicInteger(0);
public String getUrl(){
List list = this.manager.getAvailableProviders();
if(list != null && !list.isEmpty()) {
int tmpCount = this.counter.getAndIncrement();
int index = tmpCount % list.size();
index = index >= 0 ? index:index + list.size();
String url = (String)list.get(index);
logger.debug("Service({}), invoke counter({}), url({})!", new Object[]{this.service, Integer.valueOf(tmpCount), url});
return url;
} else {
throw new LoadBalanceException(String.format("Service(%s) has no available provider!", new Object[]{this.service}));
}
}
RPC
RPC—Remote Procedure Call Protocol,是应用实现进程间调用的一种常用手段。通过指定服务对外的IP地址和端口id,本地计算机能够访问到远端机器的资源。常用的RPC框架包括Java RMI, thrift, Google protobuf等。用户在选择不同的RPC框架可以从序列化,性能,语言支持几个方面去考虑,比如Java RMI只能在java生态圈中使用,无法对接其他语言提供的RPC服务,而thrift在语言支持方面就相当全面,通过编写thrift描述接口文档,可以实现不同程序之间的调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号