递归那些事儿,外祖母的神秘宝箱...
前言
忽日,走亲访友见祖母,于无聊,上阁楼,见一大箱子。一眼不以为然,再眼,定睛其竟闪闪发光。(批注:母亲大人已经三天没有打我了)

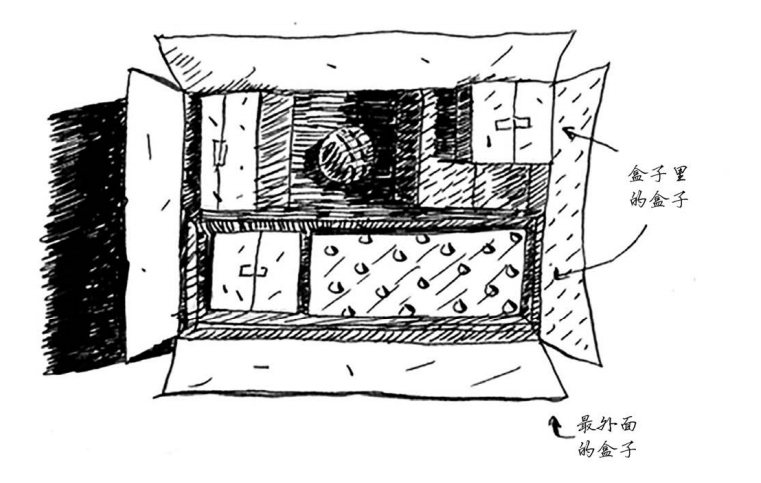
于是,祖母拿出一大盒子(里面还有很过小盒子,小盒子可能是钥匙也可能是盒子....)
分析
只有从这个盒子中找出钥匙,才能打开箱子。然而盒子里面还有盒子,盒子里面还有盒子,也可能是钥匙...于是
方案一:
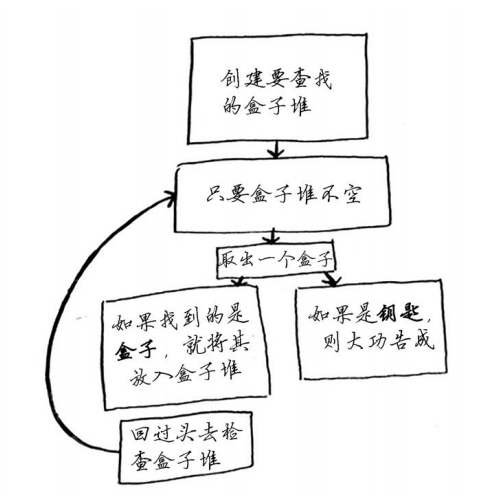
1 使用的是while循环:只要盒子堆不空,就从中 2 取一个盒子,并在其中仔细查找。 3 def look_for_key(main_box): 4 pile = main_box.make_a_pile_to_look_through() 5 while pile is not empty: 6 box = pile.grab_a_box() 7 for item in box: 8 if item.is_a_box(): 9 pile.append(item) 10 elif item.is_a_key(): 11 print "found the key!"
方案二:
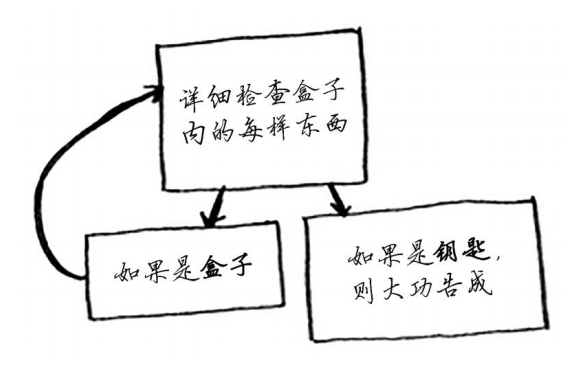
1 使用递归——函数调用自己,这种方法的伪代码如下。 2 def look_for_key(box): 3 for item in box: 4 if item.is_a_box(): 5 look_for_key(item) 6 elif item.is_a_key(): 7 print "found the key!"
这两种方法的作用相同,但在我看来,第二种方法更清晰。递归只是让解决方案更清晰,并
没有性能上的优势。实际上,在有些情况下,使用第一种方案的性能更好。
细思极恐
假如,使用递归找到一个盒子,里面既有钥匙又有盒子该怎么办?
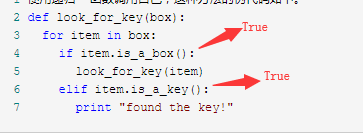
虽然钥匙已经找到了,但程序并没有识别出来,如果有无穷个盒子,那么程序将陷入死循环...
基线条件和递归条件
为解决正上述问题,就必须告诉函数何时结束,正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则
指的是函数不再调用自己,从而避免形成无限循环。改进伪代码如下
1 使用递归——加上基线条件。 2 def look_for_key(box): 3 for item in box: 4 if item.is_a_box() and item.is_a_key(): # 基线条件 5 print "found the key!" 6 return 7 elif item.is_a_key(): # 基线条件 8 print "found the key!" 9 return 10 elif item.is_a_box(): # 递归条件 11 look_for_key(item) 12 else: #防止盒子为空 13 print "this box is Null" 14 look_for_key(item.next()) # 继续查找下一个盒子
剖析递归内部调用情况
在方案一中咱们创建了一个盒子堆,因此咱们始终知道还有哪些盒子为查找
但使用递归没有盒子堆,如果查找到某个盒子为空,递归函数会不会结束喃?既然没有盒子堆,那算法怎么知道还有哪些盒子需要查找呢?客官别着急,接着往下看...
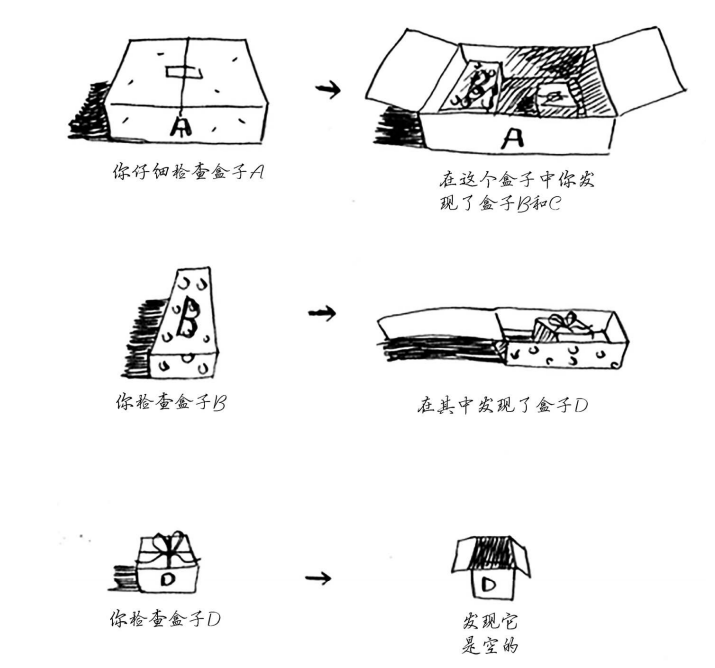
???,C盒子去哪儿了?程序不会结束吧?
不用着急,其实计算机已经为咱们列好了一个调用清单,内容如下
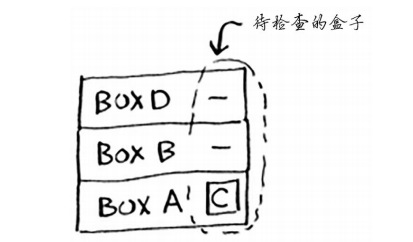
这个调用清单有一个专业的名词——调用栈,调用栈?
堆栈的自我简述
我的名字叫堆栈,其实就是一种数据结构,因为出生于“社会底层”,所以取名叫堆栈,我还有很多兄弟姐妹(数组,堆栈,队列,链表,树,图,字典树,哈希表),他们性格迥异,这里暂时不提他们。我还有一个小名叫数据篮子,这与我的特性有关,人们总喜欢稀奇古怪的东西往我这里放,所以为你惩戒他们,扔过来的东西,一律先进后出(First In Last Out,FILO),哈哈哈。我还有一个兄弟与我很相似,叫队列,但它总是与我唱反调,别人扔过来的东西,一律先进先出(First In First Out,FIFO),真是气煞我也。我还有很多故事,如果客官有兴趣的话,以后慢慢听我道来...

小结
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择。
1.重新编写代码,转而使用循环。
2.使用尾递归。这是一个高级递归主题,下次讨论。另外,并非所有的语言都支持尾递归。
下一节 采花大盗之狄克斯特拉算法

