java集合源码详解
一 Collection接口
1.List
1.1ArrayList
特点
1.底层实现基于动态数组,数组特点根据下表查找元素速度所以查找速度较快.继承自接口 Collection ->List->ArrayList
2.扩充机制 初始化时数组是空数组,调用add()第一次存放元素时长度默认为10,满了扩容机制 原来数组 + 原来数组的一半 使用数组copy()方法
2.1 构造一个初始容量为空列表。(不给指定大小时为空)

2.2使用add()方法,将指定的元素追加到列表的末尾。集合的长度 size ++ 先使用后自增1

2.3 将数组长度设置为10
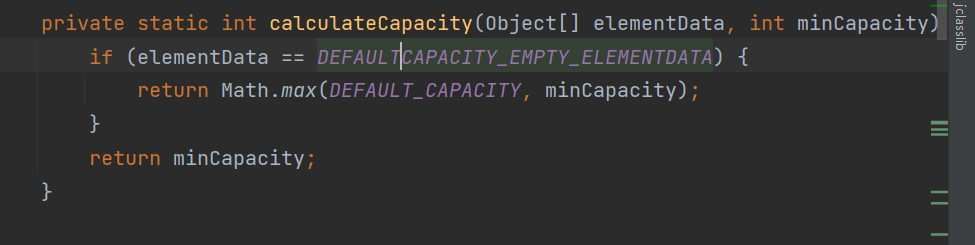
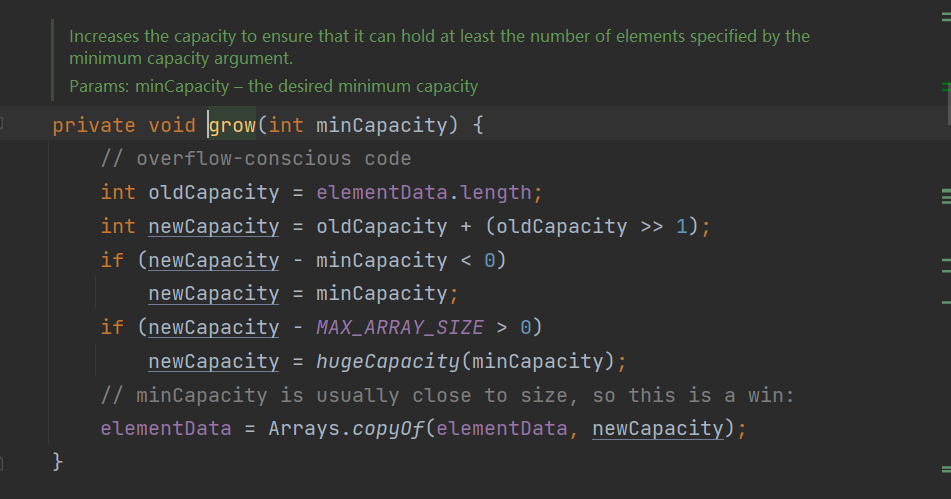
2.4判断长度是否大于当前数组 调用grow()方法扩容

2.5 newCapacity = oldCapacity + (oldCapacity >> 1); oldCapacity >> 1其实就是oldCapacity 除以2,返回一个copyOf的数组
3.线程不安全 ,效率高
1.2vector
1.采用动态数组,初始化时默认长度10

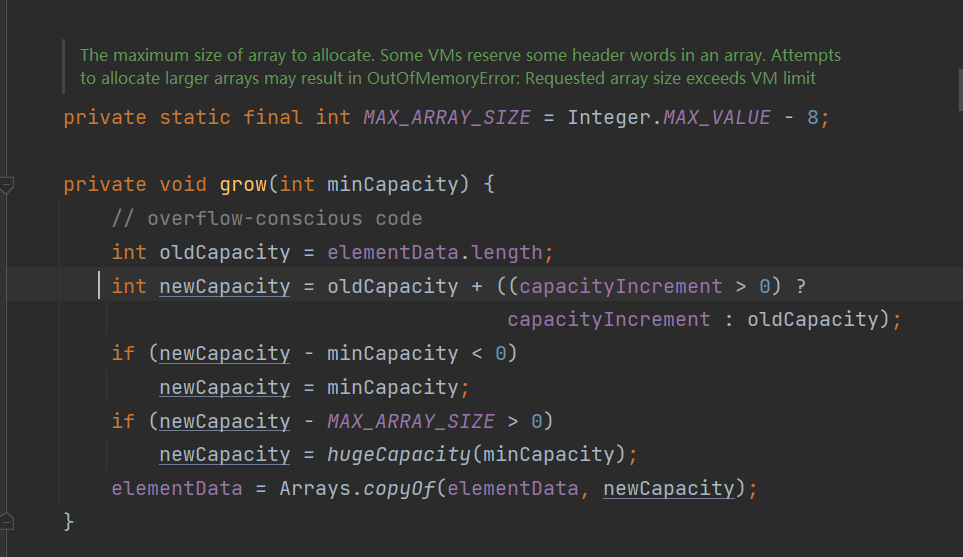
2.由于是默认初始化 没有给定capacityIncrement 所以为 0 所以新数组长度为 oldCapacity + oldCapacity 也就是增长为原来2倍,如果给定增长值capacityIncrement
后,扩充为:原来大小+增量也就是newCapacity= oldCapacity + capacityIncrement
1.3LinkedList
1.适合插入,删除操作,性能高
2.有序的元素,元素可以重复
3.原理
3.1插入时只需让88元素记住前后俩元素, 删除88元素只需让88前面元素(6)记住该元素后面(35)元素 时间复杂度 O(1)< O(logn)< O(n)< O(n^2)

3.2对于某一元素,如何找到它的下一个元素的存放位置呢?对每个数据元素ai,除了存储其本身的信息之外,
还需存储一个指示其直接后继存放位置的指针。在每个结点中再设一个指向前驱的指针域

prior 前面节点指针域 next后一个节点指针域


(图片来源<<数据结构 java语言描述>>)
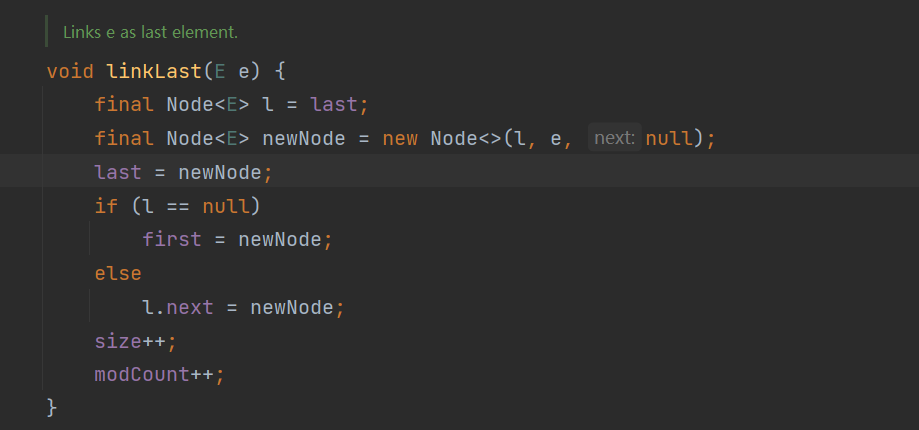
3.3 add() 时在尾部追加元素 ...等等
2 set接口
2.1HashSet
1.元素输出时不允许元素重复,允许元素为null (因为string 重写了hashCode,equals方法所以可以去重)
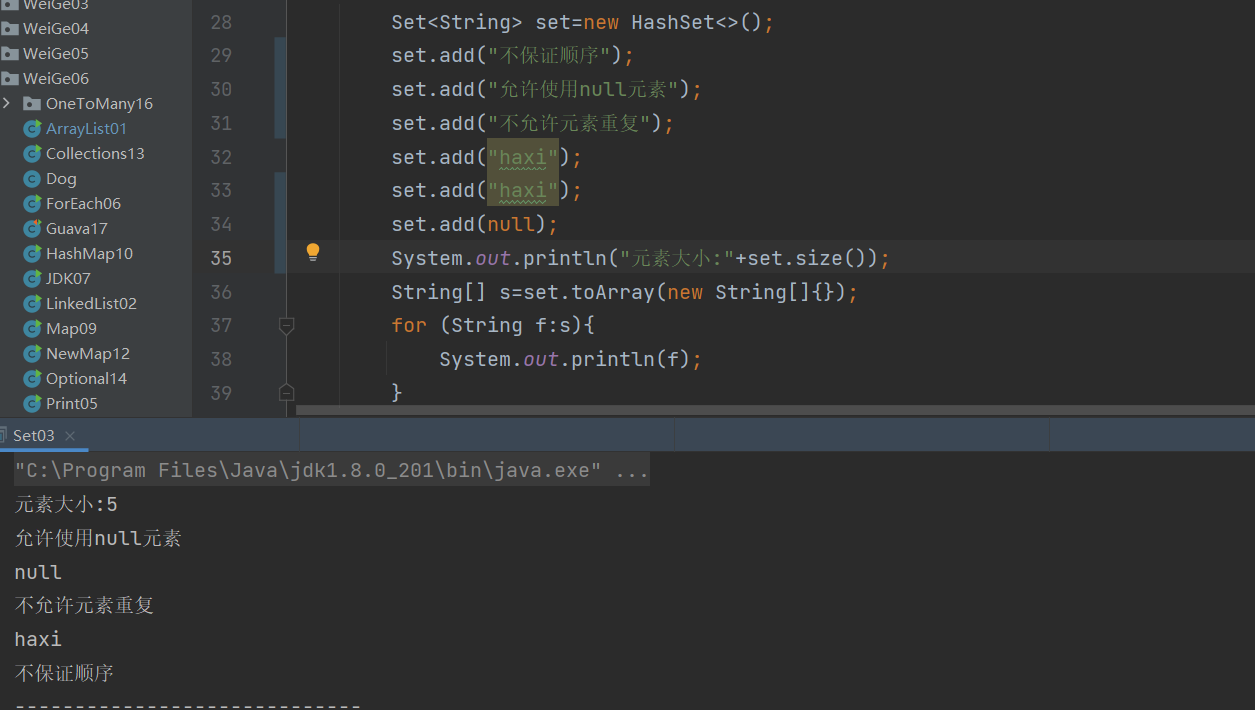
2.无序的
3.实现源码
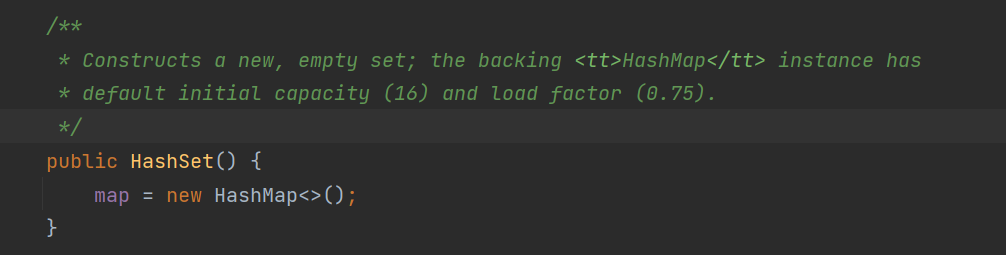
3.1 使用默认无参初始化时 其实使用的是HashMap实现的
构造一个新的空集;支持的stt>HashMaps/tt>实例具有默认的初始容量(16)和负载因子(0.75)。
3.2 向HashSet添加元素时 使用HashMap的put()方法,把值作为HashMap的key (key肯定不可以重复的,唯一的)

所以详细实现源码下面介绍HashMap时再说
4. HashSet的子类LinkedHashSet 底层使用双向链表
4.特点 4.1.按照添加顺序输出 ; 元素不重复
4.2使用无参构造的初始化容量(16)和负载因子(0.75)构造一个新的空链接哈希集。
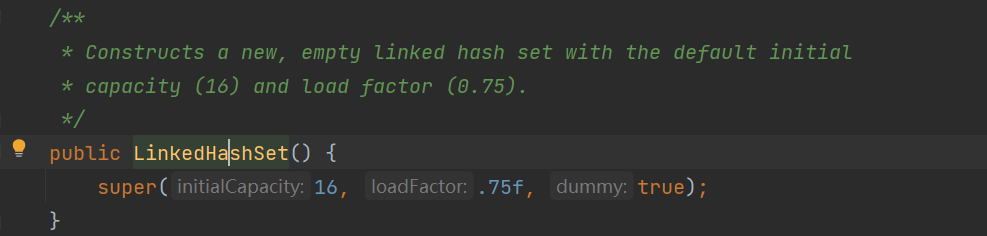
4.3调用父类HashSet 构造 初始化的对象是LinkedHashMap() 关系又跑到map上去了

4.4LinkedHashMap()调用他爹(HashMap)的构造
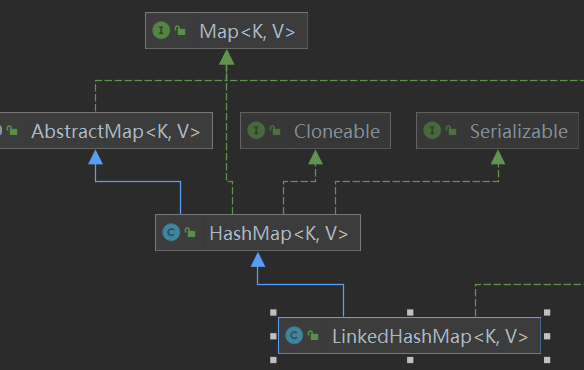
4.5 调用LinkedHashMap() 构造时 设置了hash顺序
accessOrder //这个链接哈希映射的迭代方法:true表示访问顺序,false表示插入顺序。

2.2TreeSet
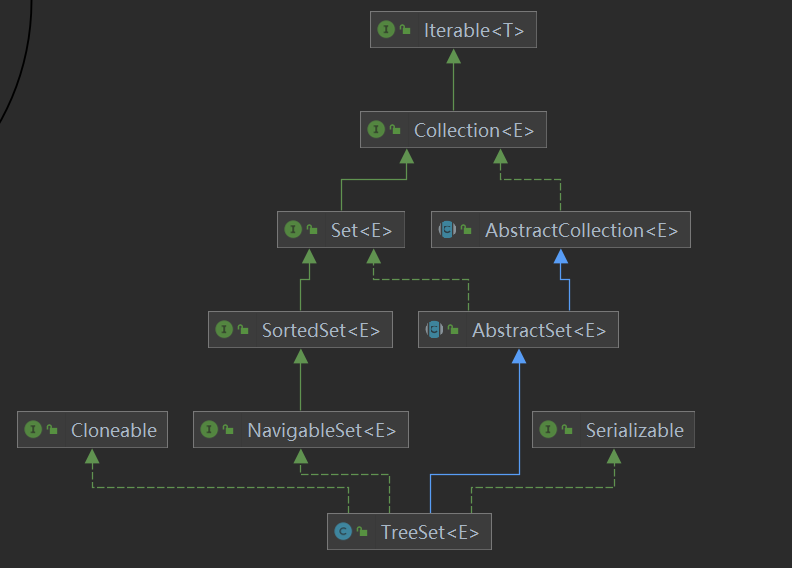
1.可以排序(元素按照自然排序进行排列 根据KEY值排序)且不允许元素重复
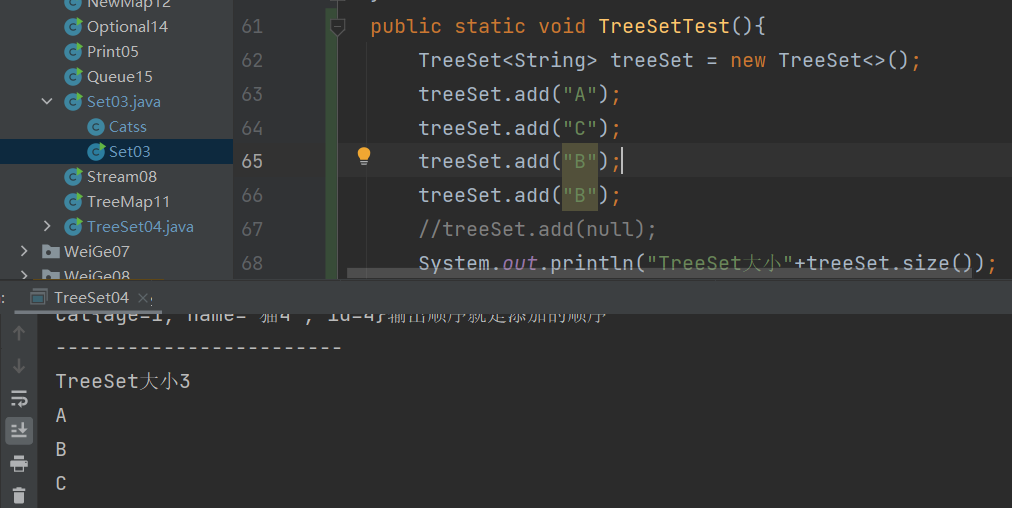
为什么会自动排序呢?
1.1 默认无参构造时 初始化的是一个TreeMap对象

2.2 调用add()方法时调用的是Map接口提供的put()方法 而treeMap 实现了map接口的put(); 所以底层存储就是treeMap 红黑树
方法 源码如下



public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }
2.不允许元素为null

3.排序想按照对象的某个值排序,某个类实现接口 Comparator 重写 compare()方法
private static void treeSet(){ //TreeSet Catss cat1=new Catss(2,"猫1",1); Catss cat2=new Catss(1,"猫2",2); Catss cat3=new Catss(3,"猫3",3); Catss cat4=new Catss(1,"猫4",4); Catss cat5=new Catss(1,"猫4",4); //TreeSet存储数据要使用比较器 TreeSet<Catss> t=new TreeSet<>(new CatComparator()); t.add(cat1); t.add(cat2); t.add(cat3); t.add(cat4); t.add(cat5); for (Object f:t){ System.out.println(f+"输出顺序是按照年龄排序递增(年龄有一样的将会覆盖一个,只输出一个)");//输出顺序是按照年龄排序递增(年龄有一样的将会覆盖一个,只输出一个) } } class CatComparator implements Comparator<Catss> { @Override public int compare(Catss o1, Catss o2) { return o1.getAge()-o2.getAge();//根据年龄排序 } }
二 Map接口
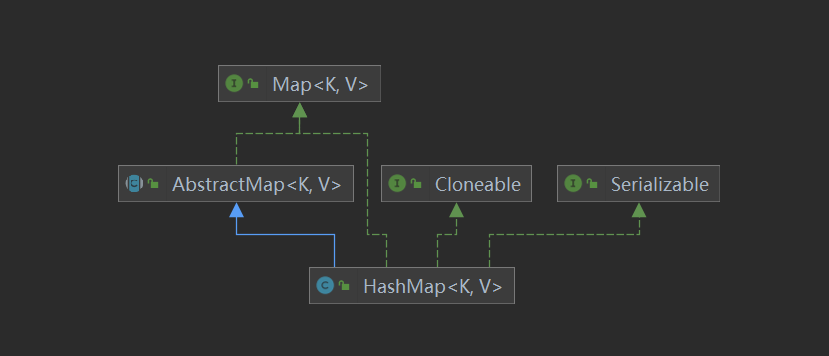
2.1 HashMap
特点:
1.无序的键值对存储一组对象
2.key必须保证唯一,Value可以重复
3.key 和value可以为null
4.线程不安全
5.默认加载因子0.75,默认数组大小16 6.实现基于哈希表 (数组+链表/红黑树)
源码:1.加载因子0.75f

2.实现map接口的put()方法 hashMap重写put
2.1为了一次存取便能得到所查记录,在记录的存储位置和它的关键字之间建立一个确定的对应关系H,
以H(key)作为关键字为key的记录在表中的位置,称这个对应关系H为哈希(Hash)函数。按这个思想建立的表为哈希表。
2.2解决Hash冲突
根据设定的哈希函数H(key)和所选中的处理冲突的方法,将一组关键字映射到一个有限的、
地址连续的地址集(区间)上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得
的查找表称之为“哈希表”,这一映射过程也称为“散列”,所以哈希表也称散列表。--<<数据结构 java语言描述>>
2.3子类LinkHashMap,按照添加顺序输出特点参考上面LinkedHashSet
put()方法的大致流程如下:
-
首先,将插入的键值对通过hash算法计算出对应的桶位置。
-
检查该桶位置上是否已经存在元素。如果该桶位置上没有元素,则直接将键值对插入到该位置上。
-
如果该桶位置上已经存在元素,则需要进行链表或红黑树的操作。
-
如果该位置上的元素个数小于8个,则将该元素添加到链表中。
-
如果该位置上的元素个数已经达到8个,则将链表转换为红黑树。如果该位置上的元素已经是红黑树,则直接将该键值对插入到红黑树中。
-
-
在插入键值对后,如果HashMap的大小超过了负载因子(load factor)*当前数组长度,则需要进行扩容操作。
-
在扩容时,会创建一个新的数组,并将原来数组中的元素重新分配到新的数组中。
-
扩容后,新的数组的大小为原来数组的两倍,并将阈值(threshold)也扩大为原来的两倍。
-
-
最后,将键值对插入到桶位置中,并返回null或原来桶位置上的值。
public V put(K key, V value) { // 计算键的hash值 return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 获取当前HashMap的table数组,如果为null,则进行初始化 Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 计算key在数组中的下标i if ((p = tab[i = (n - 1) & hash]) == null) // 如果当前位置为空,则直接创建新节点 tab[i] = newNode(hash, key, value, null); else { // 如果当前位置不为空,判断当前节点是否为要添加的key Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) // 如果是树节点,则进行红黑树添加操作 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 如果当前位置是链表,则遍历链表,查找key是否已存在 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { // 如果链表中没有找到key,则创建新节点添加到链表尾部 p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st // 如果链表长度已达到阈值,则进行链表转换为红黑树的操作 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 如果e不为null,则说明key已存在,将其旧值替换为新值 if (e != null) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; // 在LinkedHashMap中使用,记录节点访问顺序 afterNodeAccess(e); return oldValue; } } ++modCount; // 如果HashMap中键值对数量已达到阈值,则进行扩容 if (++size > threshold) resize(); // 在LinkedHashMap中使用,记录节点插入顺序 afterNodeInsertion(evict); return null; }
2.2Hashtable
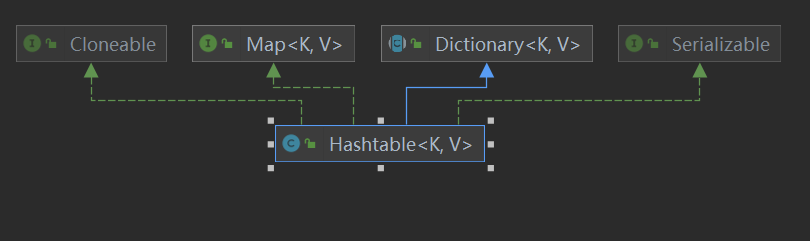
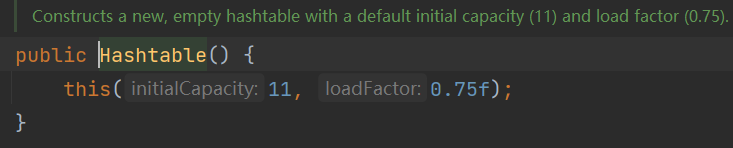
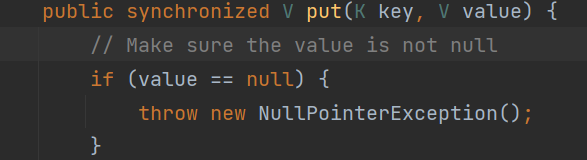
特点 1.线程安全调用put()时synchronized修饰

2.默认构造大小11扩充因子0.75
3.无序的,K和V 都不能为null ,允许元素重复

2.3TreeMap
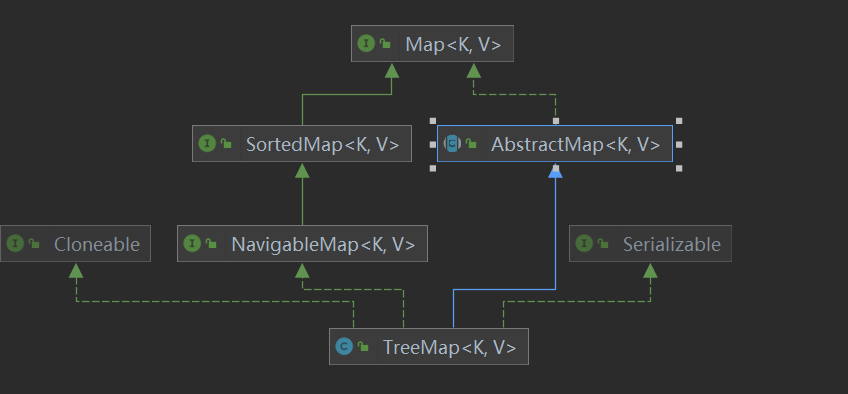
特点:1.可以排序(自然排序123),元素可以重复,K值不能重复
public static void treeMapTest(){ TreeMap<String, String> treeMap = new TreeMap<>(); treeMap.put("1","A"); treeMap.put("4","A"); treeMap.put("2","B"); treeMap.put("3","C"); treeMap.forEach((k,v)->System.out.println("K值:"+k+"----->value值:"+v)); } //K值:1----->value值:A //K值:2----->value值:B //K值:3----->value值:C //K值:4----->value值:A
2.排序想按照对象的某个值排序,某个类实现接口 Comparator 重写 compare()方法; 上面TreeSet 一样
补充
1.负载因子0.75
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。HashSet和HashMap、Hashtable的构造器允许指定一个负载极限,HashSet和HashMap、Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询);较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销。程序员可以根据实际情况来调整HashSet和HashMap的“负载极限”值。如果开始就知道HashSet和HashMap、Hashtable会保存很多记录,则可以在创建时就使用较大的初始化容量,如果初始化容量始终大于HashSet和HashMap、Hashtable所包含的最大记录数除以负载极限,就不会发生rehashing。使用足够大的初始化容量创建HashSet和HashMap、Hashtable时,可以更高效地增加记录,但将初始化容量设置太高可能会浪费空间,因此通常不要将初始化容量设置得太高 --<<java疯狂讲义>>
2.map集合的遍历
public class Map09 { public static void main(String[] args){ hashMap(); } private static void hashMap(){ Map<Integer,String> map=new HashMap<>();//Map<key,value> map.put(1,"key必须保证唯一"); map.put(2,"无序的"); map.put(3,"put方法"); map.put(null,null); System.out.println(map.size()); System.out.println("得到key=2的值:"+map.get(2)); //第一种遍历 lambda表达式遍历forEach();非常简便 System.out.println("---------lambda表达式遍历forEach()-----------------------"); map.forEach((i, s) -> System.out.println("key="+i+" value:"+s)); //第二种遍历 entrySet()方法 System.out.println("---------entrySet()方法使用foreach遍历-----------------------"); Set<Map.Entry<Integer,String>> entry=map.entrySet(); for (Map.Entry e:entry){ System.out.println(e.getKey()+"->"+e.getValue()); } System.out.println("---------entrySet()方法使用Iterator遍历-----------------------"); Set entries = map.entrySet(); Iterator iterator = entries.iterator(); while(iterator.hasNext()){ Map.Entry entrys = (Map.Entry) iterator.next(); Object key = entrys.getKey(); String value = map.get(key); System.out.println(key+" "+value+"-----"); } System.out.println("----------keySet()方法---------------------"); //第三种 遍历键 keySet()方法 Set<Integer> key=map.keySet(); for (Integer i:key){ String va=map.get(i); System.out.println(i+"->"+va); } //第四种遍历值map.values() System.out.println("----------values()方法---------------------"); Collection<String> vs=map.values(); for (String str:vs){ System.out.println(str); } } }


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发中对象命名的一点思考
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· .NET 适配 HarmonyOS 进展
· .NET 进程 stackoverflow异常后,还可以接收 TCP 连接请求吗?
· 本地部署 DeepSeek:小白也能轻松搞定!
· 基于DeepSeek R1 满血版大模型的个人知识库,回答都源自对你专属文件的深度学习。
· 在缓慢中沉淀,在挑战中重生!2024个人总结!
· 大人,时代变了! 赶快把自有业务的本地AI“模型”训练起来!
· Tinyfox 简易教程-1:Hello World!