elasticsearch映射创建查询 和Spring Data ElasticSearch入门
Elasticsearch核心概念
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅 仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的 数据)进行索引、搜索、排序、过滤
Elasticsearch ‐> Indices ‐> Types ‐> Documents ‐> Fields
索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索 引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这 个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索 引。
类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来 定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数 据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可 以为评论数据定义另一个类型
字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等, 这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据 对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然, 也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存 在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须 被索引/赋予一个索引的type。
1.创建配置
@Test public void createIndex() throws Exception { //1.创建一个Setting对象,相当于是一个配置信息。主要配置集群的名称。 Settings settings = Settings.builder() .put("cluster.name","my-application") //es配置文件 .yml 里面的名字 .build(); //2.创建一个客户端Client对象 TransportClient client = new PreBuiltTransportClient(settings); client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));//TransportClient的访问端口是9300! //3.使用Client对象创建一个索引库 client.admin().indices().prepareCreate("index_hello").get(); //4.关闭Client对象 client.close(); }
效果如下
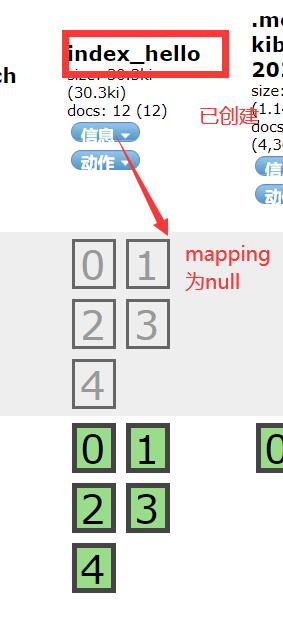
2.创建映射(就是一种类型的格式)
//创建映射(映射的格式类型) @Test public void setMappings() throws Exception { Settings settings = Settings.builder() .put("cluster.name", "my-application") .build(); //创建一个TransPortClient对象 TransportClient client = new PreBuiltTransportClient(settings) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); XContentBuilder builder = XContentFactory.jsonBuilder() .startObject() .startObject("article") .startObject("properties") .startObject("id") .field("type", "long") .field("store", true) .endObject() .startObject("title") .field("type", "text") .field("store", true) .field("analyzer", "ik_smart") .endObject() .startObject("content") .field("type", "text") .field("store", true) .field("analyzer", "ik_smart") .endObject() .endObject() .endObject() .endObject(); //使用client把mapping信息设置到索引库中 client.admin().indices() //设置要做映射的索引 .preparePutMapping("index_hello") //设置要做映射的type .setType("article") //mapping信息,可以是XContentBuilder对象可以是json格式的字符串 .setSource(builder) //执行操作 .get(); //关闭链接 client.close(); }
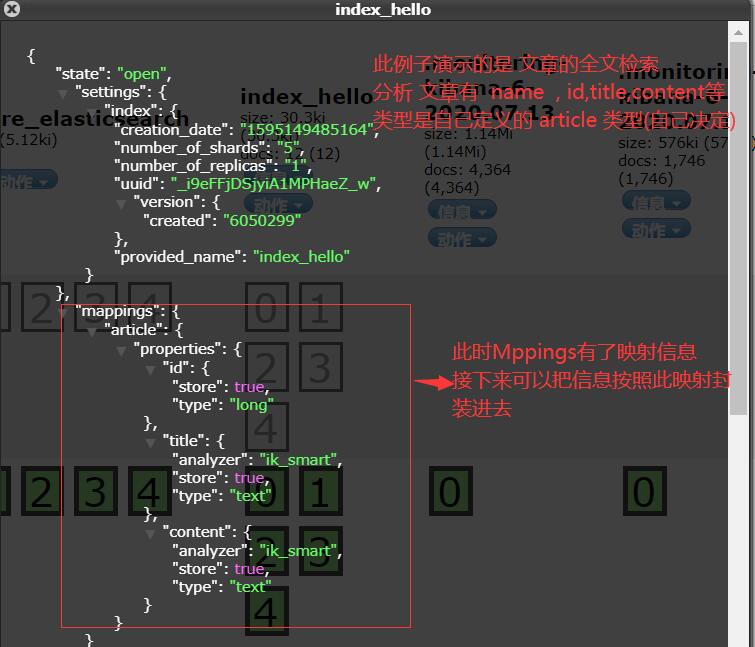
3.建立文档 (把各种文章 按照映射关系写入)
//建立文档document-------------------------------------------------------- @Test public void testAddDocument2() throws Exception { Settings settings = Settings.builder() .put("cluster.name", "my-application") .build(); //创建一个TransPortClient对象 TransportClient client = new PreBuiltTransportClient(settings) .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));, //创建一个Article对象 for (int i = 5; i < 15; i++) { Article article = new Article(); //设置对象的属性 article.setId(i); article.setTitle(i+"降级!20日起北京市突发公共卫生应急响应级别由二级调整为三级"); article.setContent(i+"北京市人民政府副秘书长陈蓓在19日举行的北京市新冠肺炎疫情防控工作新闻发布会上宣布:7月20日零时起,北京市突发公共卫生应急响应级别由二级调整为三级。(记者盖博铭、王晓洁)"); //把article对象转换成json格式的字符串。 ObjectMapper objectMapper = new ObjectMapper(); String jsonDocument = objectMapper.writeValueAsString(article); System.out.println(jsonDocument); //使用client对象把文档写入索引库 client.prepareIndex("index_hello","article", String.valueOf(i)) .setSource(jsonDocument, XContentType.JSON) .get(); } //关闭客户端 client.close(); }
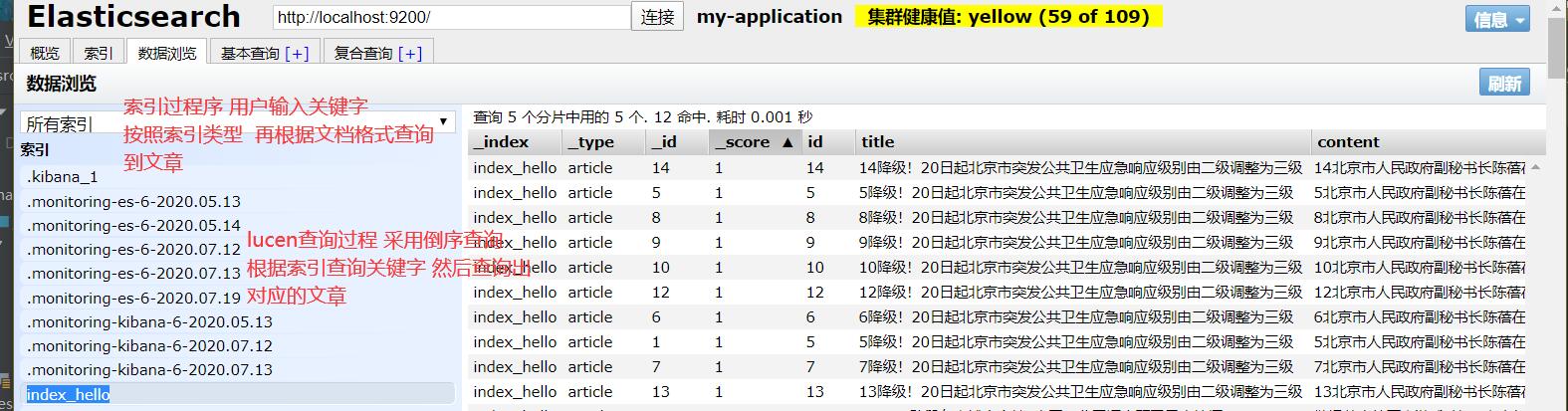
分页查询
//查询------------------------------------------------------------------------ @Test public void testQueryByTerm() throws Exception { //创建一个QueryBuilder对象 //参数1:要搜索的字段 //参数2:要搜索的关键词 QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "北京市"); //执行查询 search(queryBuilder); } public void search(QueryBuilder queryBuilder) throws Exception { //执行查询 SearchResponse searchResponse = client.prepareSearch("index_hello") .setTypes("article") .setQuery(queryBuilder) //设置分页信息 .setFrom(0) //每页显示的行数 .setSize(5) .get(); //取查询结果 SearchHits searchHits = searchResponse.getHits(); //取查询结果的总记录数 System.out.println("查询结果总记录数:" + searchHits.getTotalHits()); //查询结果列表 Iterator<SearchHit> iterator = searchHits.iterator(); while(iterator.hasNext()) { SearchHit searchHit = iterator.next(); //打印文档对象,以json格式输出 System.out.println(searchHit.getSourceAsString()); //取文档的属性 System.out.println("-----------文档的属性"); Map<String, Object> document = searchHit.getSource(); System.out.println(document.get("id")); System.out.println(document.get("title")); System.out.println(document.get("content")); } //关闭client client.close(); }
高亮


//高亮查询-------------------------------------------------- @Test public void testQueryHLight() throws Exception { //创建一个QueryBuilder对象 //参数1:要搜索的字段 //参数2:要搜索的关键词 QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "北京市"); //执行查询 Hsearch(queryBuilder,"title"); } private void Hsearch(QueryBuilder queryBuilder, String highlightField) throws Exception { HighlightBuilder highlightBuilder = new HighlightBuilder(); //高亮显示的字段 highlightBuilder.field(highlightField); highlightBuilder.preTags("<em>"); highlightBuilder.postTags("</em>"); //执行查询 SearchResponse searchResponse = client.prepareSearch("index_hello") .setTypes("article") .setQuery(queryBuilder) //设置分页信息 .setFrom(0) //每页显示的行数 .setSize(5) //设置高亮信息 .highlighter(highlightBuilder) .get(); //取查询结果 SearchHits searchHits = searchResponse.getHits(); //取查询结果的总记录数 System.out.println("查询结果总记录数:" + searchHits.getTotalHits()); //查询结果列表 Iterator<SearchHit> iterator = searchHits.iterator(); while(iterator.hasNext()) { SearchHit searchHit = iterator.next(); //打印文档对象,以json格式输出 System.out.println(searchHit.getSourceAsString()); //取文档的属性 System.out.println("-----------文档的属性"); Map<String, Object> document = searchHit.getSource(); System.out.println(document.get("id")); System.out.println(document.get("title")); System.out.println(document.get("content")); System.out.println("************高亮结果"); Map<String, HighlightField> highlightFields = searchHit.getHighlightFields(); System.out.println(highlightFields); //取title高亮显示的结果 HighlightField field = highlightFields.get(highlightField); Text[] fragments = field.getFragments(); if (fragments != null) { String title = fragments[0].toString(); System.out.println(title); } } //关闭client client.close(); }
Spring Data ElasticSearch入门
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域 为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层
实体Article
@Document(indexName = "sdes_blog", type = "article") public class Article { @Id @Field(type = FieldType.Long, store = true) private long id; @Field(type = FieldType.text, store = true, analyzer = "ik_smart") private String title; @Field(type = FieldType.text, store = true, analyzer = "ik_smart") private String content; public long getId() { return id; } public void setId(long id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } @Override public String toString() { return "Article{" + "id=" + id + ", title='" + title + '\'' + ", content='" + content + '\'' + '}'; } }
配置文件 默认端口是9300!
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/data/elasticsearch http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd "> <!--elastic客户对象的配置--> <elasticsearch:transport-client id="client1" cluster-name="my-application" cluster-nodes="127.0.0.1:9300"/> <!----> <bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate"> <constructor-arg name="client" ref="client1"/> </bean> </beans>
测试 创建索引(就是一个同类型的集合)
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration("classpath:applicationContext.xml") public class SpringDataElasticSearchTest { @Autowired private ElasticsearchTemplate template; @Test public void createIndex() throws Exception { //删除 //template.deleteIndex("springdata-index"); //创建索引, // template.createIndex(Article.class); //配置映射关系 template.putMapping(Article.class); } }
在配置文件配置
新建 repositories 包
新建接口repositories
public interface ArticleRepository extends ElasticsearchRepository<Article, Long> { List<Article> findByTitle(String title); List<Article> findByTitleOrContent(String title, String content); List<Article> findByTitleOrContent(String title, String content, Pageable pageable); }
<!--配置包扫描器,扫描dao的接口-->
<elasticsearch:repositories base-package="com.itheima.es.repositories"/>
测试页面注入
@Autowired
private ArticleRepository articleRepository; //爆红不用管
插入索引数据
@Test public void addDocument() throws Exception { for (int i = 10; i <= 20; i++) { //创建一个Article对象 Article article = new Article(); article.setId(i); article.setTitle("京东买手机神券抢不停" + i); article.setContent("不知道大家在选购智能手机产品时最看重哪些方面?相信性能、续航、拍照、颜值这几点是始终绕不开的,
再有很重要的一点就是——价格,毕竟购买力决定了究竟哪款机型才是我们的菜,适合自己的方为最佳。基于此,
今天我就来为精打细算的你精选了四款京东超值机型,
它们或可领大额神券,或享有立减优惠,我们这就来看看吧!"); //把文档写入索引库 articleRepository.save(article); } }
删除某个索引数据
@Test public void deleteDocumentById() throws Exception { articleRepository.deleteById(14l); //全部删除 //articleRepository.deleteAll(); }
分页查询
//分页查询 @Test public void testFindByTitleOrContent() throws Exception { /* page,第几页,从0开始,默认为第0页 size,每一页的大小,默认为20*/ Pageable pageable = PageRequest.of(1, 5); articleRepository.findByTitleOrContent("买手机", "不知道", pageable) .forEach(a-> System.out.println(a)); }
封装为一个对象查询(分页)
@Test public void testNativeSearchQuery() throws Exception { //创建一个查询对象 NativeSearchQuery query = new NativeSearchQueryBuilder() .withQuery(QueryBuilders.queryStringQuery("买手机").defaultField("title")) .withPageable(PageRequest.of(0, 3)) .build(); //执行查询 List<Article> articleList = template.queryForList(query, Article.class); articleList.forEach(a-> System.out.println(a)); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号