


MySQL:group by分组数据
用到的表参考https://www.cnblogs.com/july23333/p/11763375.html
group by能够把数据分为多个逻辑组,各组内进行聚集计算,在where匹配特定行基础上有了更大的灵活性。
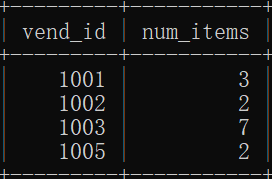
例1:返回每个供应商提供的产品数,需要按照供应商id分组
SELECT vend_id,COUNT(*) AS num_items FROM products GROUP BY vend_id
有了初步印象后,介绍group by一些使用规则:
1、group by后面可以跟任意数目的列进行分组嵌套,例如按照身高和性别分组,那么170的男生和170的女生都会展开显示出来。
2、group by子句列出的每个列都必须为检索列或有效的表达式,不能是聚集函数,且select语句中使用了表达式那么group by子句中需要是相同的表达式,不能为别名。
反例:SELECT order_num AS orderid, SUM(quantity*item_price) AS sum_price FROM orderitems GROUP BY orderid
原因:对于大多数关系数据库系统,如Oracle和SQLServer,GROUP BY是在SELECT子句之前执行的,不能使用在SELECT子句中定义的别名。MySQL对查询进行了加强,可以使用,但是仍不建议使用别名,避免混淆。 另外where子句中也不能使用别名。
3、除聚集函数外,select语句中的每个列都需要在group by子句中给出。
例3:SELECT prod_id, vend_id, COUNT(*) AS num_items FROM products GROUP BY vend_id;
虽然有效,但是根据vend_id分组后的每个vend_id有多个prod_id,返回的prod_id无意义。
4、分组列中的NULL值作为一组。
5、group by子句出现在where之后,order by之前。
那么如果不想返回所有的分组结果,而希望根据某些条件进行过滤呢?这时你可能会说where,但where过滤的是指定的行,不能过滤分组。MySQL提供了另外的子句Having来解决这一问题。
例4:选出具有两个以上价格大于10的产品的供应商
SELECT vend_id,COUNT(*) AS num_prods FROM products WHERE prod_price>=10 GROUP BY vend_id HAVING COUNT(*)>=2
你也可以理解为where在数据分组前进行过滤,having是在数据分组后过滤。
与where不同的是,having后还可以接聚集函数。
此外分组的结果不一定是按照分组顺序返回,group by不保证顺序,需要时应该添加order by实现。
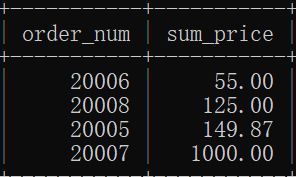
例5:检索订单价格大于等于50的订单号和订单价格,并安装价格排序输出。
SELECT order_num, SUM(quantity*item_price) AS sum_price FROM orderitems GROUP BY order_num HAVING SUM(quantity*item_price)>=50
ORDER BY sum_price
结果
简单查询到此就介绍完了,最后总结一下select语句的书写顺序和使用顺序:
书写:select from where group by having order by limit
执行:from where group by having select distinct order by limit

