应用深度神经网络预测学生期末成绩
0、引言
- 写作目的:只是为了学习一下DNN的用法
- 基本思路:
- 首先,将学生成绩(平时成绩x、期末成绩y:csv格式)装载;
- 接着,将成绩数据标准化。(PS:虽然这里的成绩已经[0~100]之间了,本文是为了学习DNN,故不省略这一步)
- 接着,将平时成绩x,期末成绩y进一步拆分(按比例,如20%)为训练数据和测试数据。PS:测试数据用来检验训练出的模型性能
- 接着,创建DNN模型。依次设置一系列的参数。
- 接着,训练模型(fit函数)。model1.fit(x_train, y_train)
- 接着,评估模型性能。用测试集数据评估,还可以用训练集数据。 如果性能不好,则调参(第四步)
- 最后,可以应用所得模型,进行期末成绩的预测。
- 实验环境
- Mac OSX
- python 2
- 应用到的包(好多,缺什么你安装什么好了,有(很多)时候还会出错,自己百度、谷歌等可以解决,我花费了1天时间才搞好)
1、装载数据
- 预先加载包
import csv, os - 装载数据,到 score_data ; 标题写到score_header, 代码如下:
score_file = 'score.csv'
if not os.path.exists(score_file):
print "File ", score_file, " does not exist!"
else :
score_data = []
with open(score_file) as csvfile:
csv_reader = csv.reader(csvfile)
score_header = next(csv_reader) # 读取第1行, 不是标题
score_header = next(csv_reader) # 读取第2行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到score_data中
score_data.append(row)
csvfile.close() # 关闭文件
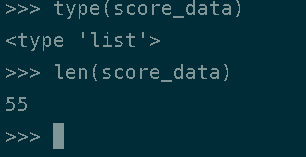
- score_data结果:
2、数据标准化
- 拆分数据集 x(平时成绩),y(期末成绩;
- 将其标准化。即将输入区间:$(-\infty , +\infty ) $映射到区间(0,1)
2.1 切片 score_data, 数据导入 x ,y 。代码:
x , y = [], []
for item in score_data:
x0 , y0 = item[0:13], item[13] # 注意:LL的切片[m:n] ,从 LL[m] ... LL[n-1]
x.append(x0)
y.append(y0)
2.2 标准化
- 应用包:sklearn.preprocessing 中 MinMaxScaler()。 将 x和 y 映射成 [0,1] 区间的值。 代码:
from sklearn.preprocessing import MinMaxScaler
x_MinMax = MinMaxScaler ()
y_MinMax = MinMaxScaler ()
import numpy as np
y = np.array(y).reshape((len(y), 1))
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
x.mean(axis =0)
# print x_MinMax.scale_
# print y_MinMax.scale_
# print y_MinMax.inverse_transform([[0.8725]]) # 如果预测值为“0.8725”,则可用 inverse_transform 映射回实际值
-
问题:如何将一个标准化的(预测)值value,再映射回实际值?
- 应用 y_MinMax.inverse_transform([[value]]) 。
-
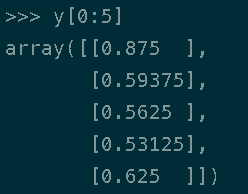
以y为例,显示top 5 个转换后的数。
3、数据拆分为训练集和测试集
- 应用包:sklearn.model_selection 中 train_test_split()。 将 x和 y 按照比例(test_size)拆分。 代码:
import random
from sklearn.model_selection import train_test_split
np.random.seed(2019)
x_train , x_test , y_train , y_test = train_test_split(x, y, test_size = 0.2)
4、设置DNN模型
-
先引入包:
from sknn.mlp import Regressor, Layer -
参数设置步骤
- 先设置DNN每层计算方式,先设置每个隐层、最后设置输出层
- 隐层。设置参数:激活函数(Sigmoid、ReLU: Rectifier)、计算单元数量units
- 输出层。Layer("Linear")
- 学习速率: learning_rate=0.02
- random_rate = 2019 : 用来再现相同的数据
- 模型允许最大迭代次数:n_iter = 10
- 先设置DNN每层计算方式,先设置每个隐层、最后设置输出层
-
代码:
from sknn.mlp import Regressor, Layer
## 模型1,fit1_Sigmoid:激活函数 "Sigmoid"
fit1_Sigmoid = Regressor(layers=[
Layer("Sigmoid", units=6),
Layer("Sigmoid", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=10)
## 模型2,fit2_ReLU :激活函数 "ReLU"
fit2_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=10)
## 模型3,fit3_ReLU:激活函数 "ReLU", 调整迭代次数为100
fit3_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=100)
## 模型4,fit4_ReLU:激活函数 "ReLU", 调整迭代次数为100,
## 采用L2正则化,和一个相对小的权重衰减系数0.001来调整期末考试得分模型
fit4_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
regularize = "L2",
random_state=2019,
weight_decay =0.001,
n_iter=100)
5、训练模型
- 用函数fit()训练模型,即使用数据(x_train, y_train),拟合模型。代码:
print "fitting model right now"
fit1_Sigmoid.fit(x_train,y_train)
fit2_ReLU.fit(x_train,y_train)
fit3_ReLU.fit(x_train,y_train)
fit4_ReLU.fit(x_train,y_train)
6、评估模型
6.0 用预测结果与实际结果的相关性 R的平方来评估模型。
- 引入下面的包 mean_squared_error。 代码:
from sklearn.metrics import mean_squared_error
6.1 评估模型在训练集上的表现
pred1_train = fit1_Sigmoid.predict(x_train)
pred2_train = fit2_ReLU.predict(x_train)
pred3_train = fit3_ReLU.predict(x_train)
pred4_train = fit4_ReLU.predict(x_train)
mse_1_train = mean_squared_error(pred1_train, y_train)
mse_2_train = mean_squared_error(pred2_train, y_train)
mse_3_train = mean_squared_error(pred3_train, y_train)
mse_4_train = mean_squared_error(pred4_train, y_train)
print "train ERROR :\n \
mse_1_train = %s \n mse_2_train = %s \n mse_3_train = %s \n mse_4_train = %s "\
%(mse_1_train, mse_2_train,mse_3_train,mse_4_train)
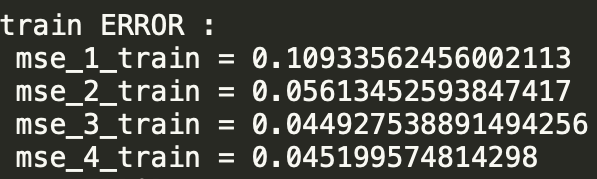
- 运行结果:
6.2 评估模型在测试集上的表现
pred1_test = fit1_Sigmoid.predict(x_test)
pred2_test = fit2_ReLU.predict(x_test)
pred3_test = fit3_ReLU.predict(x_test)
pred4_test = fit4_ReLU.predict(x_test)
mse_1_test = mean_squared_error(pred1_test, y_test)
mse_2_test = mean_squared_error(pred2_test, y_test)
mse_3_test = mean_squared_error(pred3_test, y_test)
mse_4_test = mean_squared_error(pred4_test, y_test)
print "test ERROR :\n \
mse_1_test = %s \n mse_2_test = %s \n mse_3_test = %s \n mse_4_test = %s "\
%(mse_1_test, mse_2_test,mse_3_test,mse_4_test)
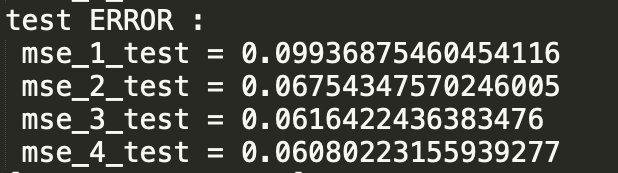
- 运行结果:
7、应用模型
-
给出一组平时成绩,预测期末成绩 y'
-
映射到实际的分数
- 用MinMaxScaler的函数inverse_transform()
- y_MinMax.inverse_transform([[y']])
7.1. 输入:csv格式数据,存入:x_data
score_file_pred = 'score_pred.csv'
if not os.path.exists(score_file_pred):
print "File ", score_file_pred, " does not exist!"
else :
x_data = []
with open(score_file_pred) as csvfile_pred:
csv_reader = csv.reader(csvfile_pred)
score_header = next(csv_reader) # 读取第1行, 不是标题
score_header = next(csv_reader) # 读取第2行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到score_data中
x_data.append(row[0:NumberOfPractice])
csvfile_pred.close() # 关闭文件
7.2. 将 x_src 标准化
x_src = x_MinMax.fit_transform(x_data)
x_src.mean(axis =0)
7.3. 应用4个模型预测。
- 得到的预测值:pred1_src、pred2_src、pred3_src、pred4_src
# print "根据平时成绩预测期末成绩 ......"
pred1_src = fit1_Sigmoid.predict(x_src)
pred2_src = fit2_ReLU.predict(x_src)
pred3_src = fit3_ReLU.predict(x_src)
pred4_src = fit4_ReLU.predict(x_src)
7.4. 将标准化的预测值,映射到实践值
pred_real1 = y_MinMax.inverse_transform(pred1_src)
pred_real2 = y_MinMax.inverse_transform(pred2_src)
pred_real3 = y_MinMax.inverse_transform(pred3_src)
pred_real4 = y_MinMax.inverse_transform(pred4_src)
# print "期末成绩"
# print pred_real1, pred_real2, pred_real3, pred_real4
7.5. 将预测结果,写到csv文件
- 新建了一个csv文件
# print "期末成绩写入文件... "
with open("score_pred_result.csv", 'w') as f:
result_writer = csv.writer(f)
result_writer.writerow(score_header + ["Pred1","Pred2","Pred3","Pred4"])
i = 0
for row in x_data:
row.append(pred_real1[i])
row.append(pred_real2[i])
row.append(pred_real3[i])
row.append(pred_real4[i])
i = i + 1
result_writer.writerow(row)
f.close() # 关闭文件
附录1:本次实验完整的代码
# -*- coding: utf-8 -*-
# 可以处理指定目录下的 对应分数的score.csv
import pdb
import csv
import os
# step 1: 装载数据,到 score_data ; 标题写到score_header
# 数据集名称
score_file = 'score.csv'
NumberOfPractice = 13 # 平时作业次数
if not os.path.exists(score_file):
print "File ", score_file, " does not exist!"
else :
score_data = []
with open(score_file) as csvfile:
csv_reader = csv.reader(csvfile)
score_header = next(csv_reader) # 读取第1行, 不是标题
score_header = next(csv_reader) # 读取第2行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到score_data中
score_data.append(row)
csvfile.close() # 关闭文件
# step 2:拆分数据集 x(平时成绩),y(期末成绩),并将其标准化
# 2.1 切片 score_data
x , y = [], []
for item in score_data:
x0 , y0 = item[0:NumberOfPractice], item[NumberOfPractice]
x.append(x0)
y.append(y0)
# 2.2 标准化
from sklearn.preprocessing import MinMaxScaler
x_MinMax = MinMaxScaler ()
y_MinMax = MinMaxScaler ()
import numpy as np
y = np.array(y).reshape((len(y), 1))
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
x.mean(axis =0)
# print x_MinMax.scale_
# print y_MinMax.scale_
# print y_MinMax.inverse_transform([[0.8725]]) # 如果预测值为“0.8725”,则可用 inverse_transform 映射回实际值
## step 3:拆分为训练集和测试集
import random
from sklearn.model_selection import train_test_split
np.random.seed(2019)
x_train , x_test , y_train , y_test = train_test_split(x, y, test_size = 0.2)
## step 4:创建DNN模型。 PS: 可以创建很多类型的DNN,
from sknn.mlp import Regressor, Layer
## 模型1,fit1_Sigmoid:激活函数 "Sigmoid"
fit1_Sigmoid = Regressor(layers=[
Layer("Sigmoid", units=6),
Layer("Sigmoid", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=10)
## 模型2,fit2_ReLU :激活函数 "ReLU"
fit2_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=10)
## 模型3,fit3_ReLU:激活函数 "ReLU", 调整迭代次数为100
fit3_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
random_state=2019,
n_iter=100)
## 模型4,fit4_ReLU:激活函数 "ReLU", 调整迭代次数为100,
## 采用L2正则化,和一个相对小的权重衰减系数0.001来调整期末考试得分模型
fit4_ReLU = Regressor(layers=[
Layer("Rectifier", units=6),
Layer("Rectifier", units=14),
Layer("Linear")],
learning_rate=0.02,
regularize = "L2",
random_state=2019,
weight_decay =0.001,
n_iter=100)
## step 5: 用函数fit()训练模型,即使用数据(x_train, y_train),拟合模型
print "fitting model right now"
fit1_Sigmoid.fit(x_train,y_train)
fit2_ReLU.fit(x_train,y_train)
fit3_ReLU.fit(x_train,y_train)
fit4_ReLU.fit(x_train,y_train)
## step 6: 评估模型。
### 6.0 用预测结果与实际结果的相关性 R的平方来评估模型,引入下面的包 mean_squared_error
from sklearn.metrics import mean_squared_error
### 6.1 评估模型在训练集上的表现
pred1_train = fit1_Sigmoid.predict(x_train)
pred2_train = fit2_ReLU.predict(x_train)
pred3_train = fit3_ReLU.predict(x_train)
pred4_train = fit4_ReLU.predict(x_train)
mse_1_train = mean_squared_error(pred1_train, y_train)
mse_2_train = mean_squared_error(pred2_train, y_train)
mse_3_train = mean_squared_error(pred3_train, y_train)
mse_4_train = mean_squared_error(pred4_train, y_train)
print "train ERROR :\n \
mse_1_train = %s \n mse_2_train = %s \n mse_3_train = %s \n mse_4_train = %s "\
%(mse_1_train, mse_2_train,mse_3_train,mse_4_train)
### 6.2 评估模型在测试集上的表现
pred1_test = fit1_Sigmoid.predict(x_test)
pred2_test = fit2_ReLU.predict(x_test)
pred3_test = fit3_ReLU.predict(x_test)
pred4_test = fit4_ReLU.predict(x_test)
mse_1_test = mean_squared_error(pred1_test, y_test)
mse_2_test = mean_squared_error(pred2_test, y_test)
mse_3_test = mean_squared_error(pred3_test, y_test)
mse_4_test = mean_squared_error(pred4_test, y_test)
print "test ERROR :\n \
mse_1_test = %s \n mse_2_test = %s \n mse_3_test = %s \n mse_4_test = %s "\
%(mse_1_test, mse_2_test,mse_3_test,mse_4_test)
## step 7: 应用模型s
### 7.1. 输入:csv格式数据,存入:x_data
print "读取新数据 ... "
score_file_pred = 'score_pred.csv'
if not os.path.exists(score_file_pred):
print "File ", score_file_pred, " does not exist!"
else :
x_data = []
with open(score_file_pred) as csvfile_pred:
csv_reader = csv.reader(csvfile_pred)
score_header = next(csv_reader) # 读取第1行, 不是标题
score_header = next(csv_reader) # 读取第2行每一列的标题
for row in csv_reader: # 将csv 文件中的数据保存到score_data中
x_data.append(row[0:NumberOfPractice])
csvfile_pred.close() # 关闭文件
### 7.2. 将 x_src 标准化
x_src = x_MinMax.fit_transform(x_data)
x_src.mean(axis =0)
### 7.3. 应用4个模型预测。
## 得到的预测值:pred1_src、pred2_src、pred3_src、pred4_src
# print "根据平时成绩预测期末成绩 ......"
pred1_src = fit1_Sigmoid.predict(x_src)
pred2_src = fit2_ReLU.predict(x_src)
pred3_src = fit3_ReLU.predict(x_src)
pred4_src = fit4_ReLU.predict(x_src)
### 7.4. 将标准化的预测值,映射到实践值
pred_real1 = y_MinMax.inverse_transform(pred1_src)
pred_real2 = y_MinMax.inverse_transform(pred2_src)
pred_real3 = y_MinMax.inverse_transform(pred3_src)
pred_real4 = y_MinMax.inverse_transform(pred4_src)
# print "期末成绩"
# print pred_real1, pred_real2, pred_real3, pred_real4
### 7.5. 将预测结果,写到csv文件
# print "期末成绩写入文件... "
with open("score_pred_result.csv", 'w') as f:
result_writer = csv.writer(f)
result_writer.writerow(score_header + ["Pred1","Pred2","Pred3","Pred4"])
i = 0
for row in x_data:
row.append(pred_real1[i])
row.append(pred_real2[i])
row.append(pred_real3[i])
row.append(pred_real4[i])
i = i + 1
result_writer.writerow(row)
f.close() # 关闭文件
#


 浙公网安备 33010602011771号
浙公网安备 33010602011771号