结合sklearn的可视化工具Yellowbrick:超参与行为的可视化带来更优秀的实现
https://blog.csdn.net/qq_34739497/article/details/80508262
Yellowbrick 是一套名为「Visualizers」的视觉诊断工具,它扩展了 Scikit-Learn API 以允许我们监督模型的选择过程。简而言之,Yellowbrick 将 Scikit-Learn 与 Matplotlib 结合在一起,并以传统 Scikit-Learn 的方式对模型进行可视化。
-
可视化器
可视化器(Visualizers)是一种从数据中学习的估计器,其主要目标是创建可理解模型选择过程的可视化。在 Scikit-Learn 的术语中,它们类似于转换器(transformer),其在可视化数据空间或包装模型估计器上类似「ModelCV」(例如 RidgeCV 和 LassoCV)方法的过程。Yellowbrick 的主要目标是创建一个类似于 Scikit-Learn 的 API,其中一些流行的可视化器包括:特征可视化
- Rank Features:单个或成对特征排序以检测关系
- Radial Visualization:围绕圆形图分离实例
- PCA Projection:基于主成分分析映射实例
- Manifold Visualization:通过流形学习实现高维可视化
- Feature Importances:基于模型性能对特征进行排序
- Recursive Feature Elimination:按重要性搜索最佳特征子集
- Scatter and Joint Plots:通过特征选择直接进行数据可视化
分类可视化
- Class Balance:了解类别分布如何影响模型
- Class Prediction Error:展示分类的误差与主要来源
- Classification Report:可视化精度、召回率和 F1 分数的表征
- ROC/AUC Curves:受试者工作曲线和曲线下面积
- Confusion Matrices:类别决策制定的视觉描述
- Discrimination Threshold:搜索最佳分离二元类别的阈值
回归可视化
- Prediction Error Plots:沿着目标域寻找模型崩溃的原因
- Residuals Plot:以残差的方式展示训练和测试数据中的差异
- Alpha Selection:展示 alpha 的选择如何影响正则化
聚类可视化
- K-Elbow Plot:使用肘法(elbow method)和多个指标来选择 k
- Silhouette Plot:通过可视化轮廓系数值来选择 k
模型选择可视化
- Validation Curve:对模型的单个超参数进行调整
- Learning Curve:展示模型是否能从更多的数据或更低的复杂性中受益
文本可视化
- Term Frequency:可视化语料库中词项的频率分布
- t-SNE Corpus Visualization:使用随机近邻嵌入来投影文档
实例
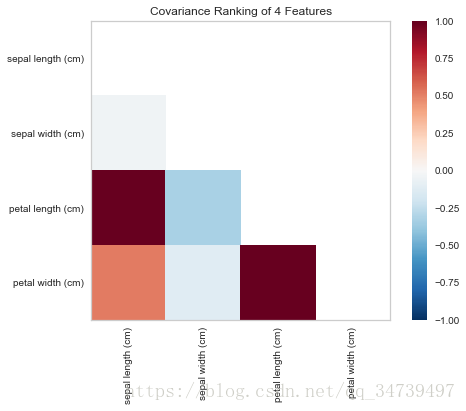
#特征之间协方差可视化
from yellowbrick.features import Rank2D
from sklearn.datasets import load_iris
data=load_iris()
visualizer = Rank2D(features=data['feature_names'], algorithm='covariance')
visualizer.fit(data['data'], data['target']) # Fit the data to the visualizer
visualizer.transform(data['data']) # Transform the data
visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
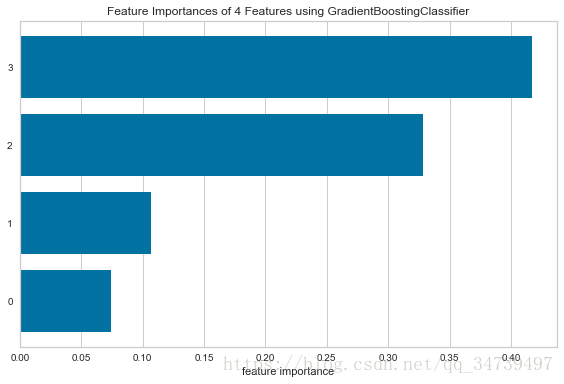
#梯度提升树中特征重要性可视化
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingClassifier
from yellowbrick.features import FeatureImportances
from sklearn.datasets import load_iris
data=load_iris()
fig = plt.figure()
ax = fig.add_subplot()
viz = FeatureImportances(GradientBoostingClassifier(), relative=False)
viz.fit(data['data'],data['target']) # Fit the data to the visualizer
viz.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
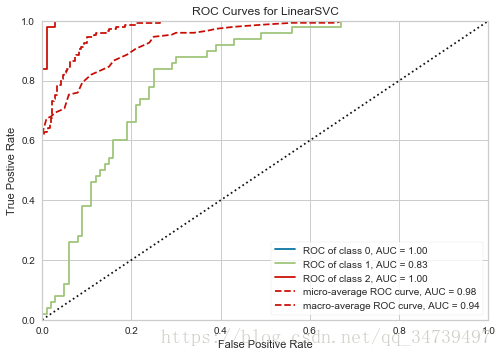
#线性支持向量机ROC曲线可视化
from sklearn.svm import LinearSVC
from yellowbrick.classifier import ROCAUC
model = LinearSVC()
model.fit(data['data'],data['target'])
visualizer = ROCAUC(model)
visualizer.score(data['data'],data['target'])
visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
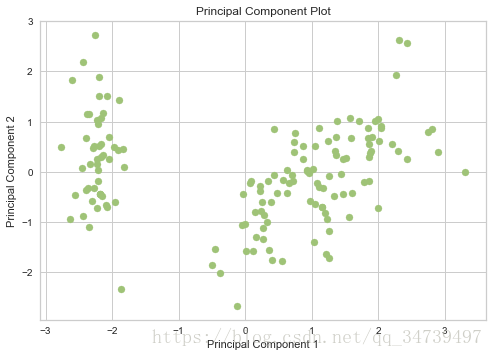
#主成分分析二维降维可视化
from yellowbrick.features.pca import PCADecomposition
visualizer = PCADecomposition(scale=True, center=False, color="g", proj_dim=2)
visualizer.fit_transform(data['data'],data['target'])
visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
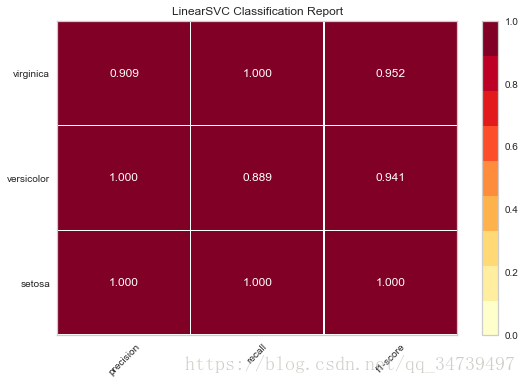
#线性支持向量机准确率、召回率、f1-score可视化
from sklearn.svm import LinearSVC
from yellowbrick.classifier import ClassificationReport
from sklearn.model_selection import train_test_split
model = LinearSVC()
X_train, X_test, y_train, y_test = train_test_split(data['data'],data['target'], test_size=0.2)
visualizer = ClassificationReport(model, classes=data['target_names'])
visualizer.fit(X_train, y_train) # Fit the visualizer and the model
visualizer.score(X_test, y_test) # Evaluate the model on the test data
g = visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
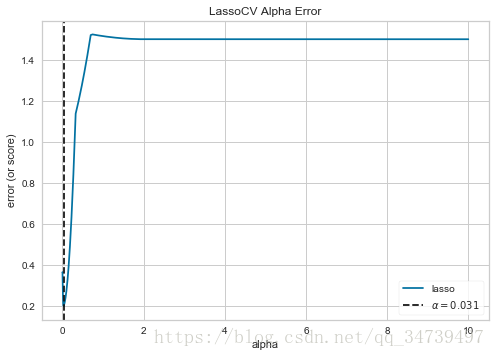
#alpha 的选择如何影响正则化可视化
import numpy as np
from sklearn.linear_model import LassoCV
from yellowbrick.regressor import AlphaSelection
# Create a list of alphas to cross-validate against
alphas = np.logspace(-10, 1, 400)#以10为底对数,-10到1分成400份
# Instantiate the linear model and visualizer
model = LassoCV(alphas=alphas)
visualizer = AlphaSelection(model)
visualizer.fit(data['data'],data['target'])
g = visualizer.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
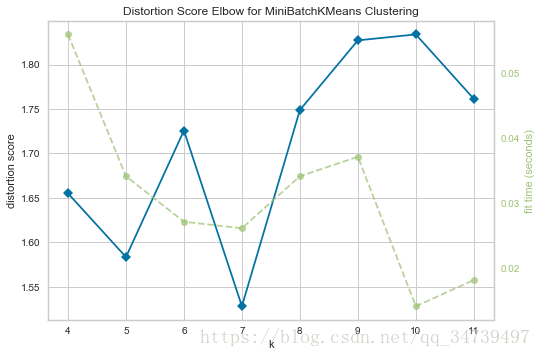
#肘部法则选择最佳聚类的k
from sklearn.cluster import MiniBatchKMeans
from yellowbrick.cluster import KElbowVisualizer
# Instantiate the clustering model and visualizer
visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))
visualizer.fit(data["data"]) # Fit the training data to the visualizer
visualizer.poof() # Draw/show/poof the data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
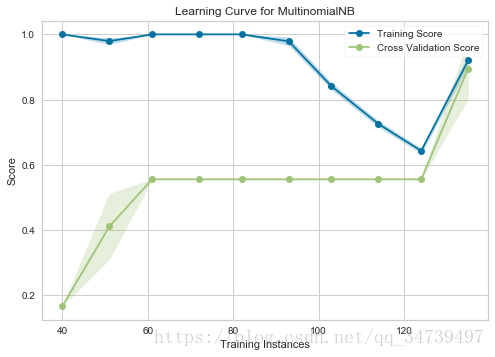
#训练集数量对模型表现可视化
import numpy as np
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import StratifiedKFold
from yellowbrick.model_selection import LearningCurve
# Create the learning curve visualizer
cv = StratifiedKFold(12)#k折交叉切分
sizes = np.linspace(0.3, 1.0, 10)
viz = LearningCurve(
MultinomialNB(), cv=cv, train_sizes=sizes,
scoring='f1_weighted', n_jobs=4
)
# Fit and poof the visualizer
viz.fit(data['data'],data['target'])
viz.poof()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

 浙公网安备 33010602011771号
浙公网安备 33010602011771号