

MYSQL之索引
在讲MYSQL的索引之前,先了解一下MYSQL的B+树,首先它是多路平衡搜索树,为什么MYSQL使用的是B+树,因为数据存储在磁盘中,而树的高度决定了访问磁盘的次数,所以选择B+树;MYSQL的B+树结构如下图所示:
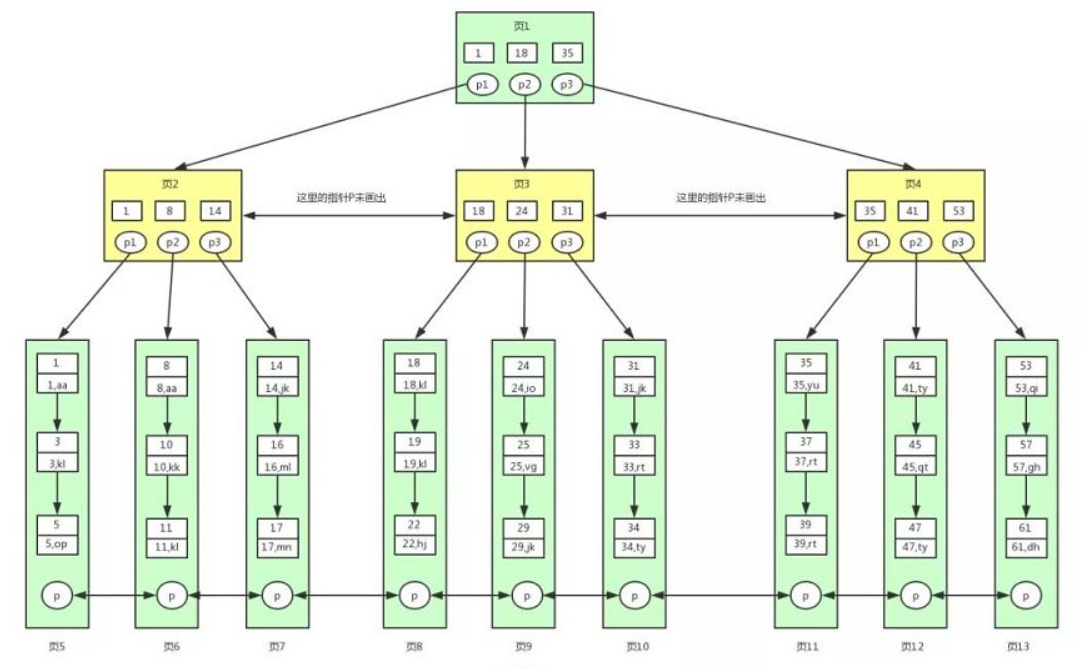
MYSQL的B+树它具有以下特点:
(1)叶子节点当中存储所有的数据
(2)非叶子节点当中只存储所有索引信息(key用来排序)
(3)B+树的高度代表访问磁盘的次数
(4)节点默认的大小是16K,即一页(磁盘管理的最小单位)
(5)所有叶子节点都在同一层高度
(6)采用中序遍历
对于整颗树采用中序遍历,每访问一个节点,就需要访问一次磁盘IO;对于非叶子节点,节点内的数据采用数组的方式存储,在查询时,把数据从磁盘读取到内存中,再用二分查找,快速找到下一次访问的位置;对于叶子节点,节点内的数据是以单链表存储,叶子节点之间通过前后指针指向构成双向连表,便于范围查找;在查询时,先遍历单链表,再通过双链表找到相邻的叶子节点,继续遍历单链表,依次执行最终找到所查询的数据。
索引
(1)主键索引
非空索引,一个表只有一个主键索引,在innodb中,主键索引的B+树包含包含表行数据
PRIMARY KEY(key)
(2)唯一索引
不可以出现相同的索引内容
UNIQUE(key)
(3)普通索引
允许出现相同的索引内容
INDEX(key) OR KEY(key......)
(4)组合索引
对表上的多个列进行索引
INDEX idx(key1,key2,........)
UNIQUE(key1,key2,........)
(5)全文索引
将存储在数据库当中的整本书和整篇文章中的任意内容信息查找出来的技术;关键词 FULLTEXT;在短字符串中用 LIKE % ;在全文索引中用 match 和 against
主键选择的规则
innodb中每一张表有且仅有一个主键
(1)如果设置了PRIMARY KEY,则该设置的key为该表的主键
(2)如果没有显式设置主键,则从非空唯一索引中选择
a.只要有非空唯一索引,则选择该索引为主键
b.有多个非空唯一索引,则选择声明的第一个为主键
(3)如果没有设置主键,也没有设置非空唯一索引,则自动生成一个6字节的_rowid作为主键
外键约束
外键用来关联两个表,来保证参照完整性,MyISAM存储引擎本身不支持外键,innodb完整支持外键;外键的作用是使表数据实现联动删除/更新,父表删除/更新,子表也会删除/更新。
约束与索引区别,创建主键或者唯一索引时,同时创建了相应的约束,但是约束是逻辑上的概念,索引是一个数据结构,既包含逻辑也包含物理的存储方式。
索引实现
索引存储
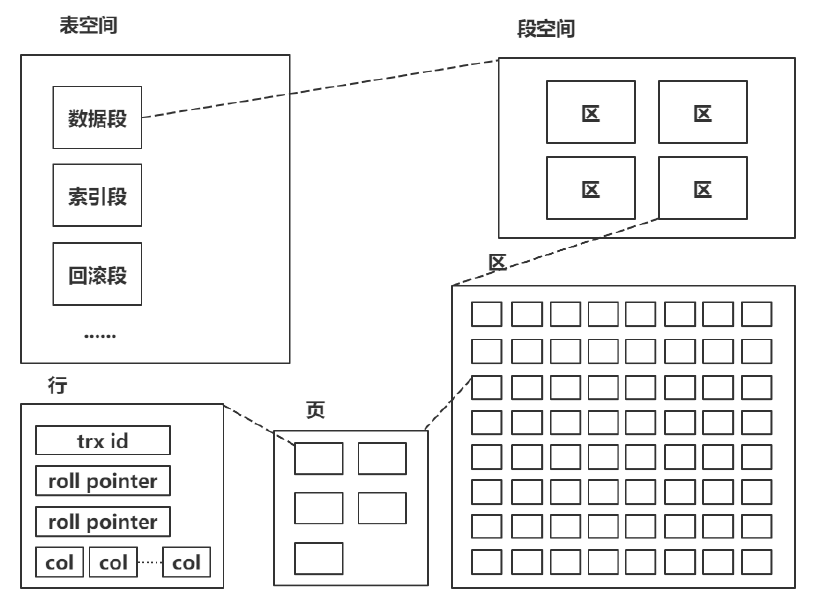
innodb由段、区、页组成:
(1)段,数据段(每一行数据)、索引段(B+树)、回滚段(事务);每一个段的段空间由区构成(4~5 个区);
(2)区,区大小为1MB,每一个区由64个连续页构成;
(3)页,默认值为16k;页为逻辑页,磁盘物理页大小一般为 4K 或者 8K,为了保证区中的页的连续,存储引擎一般一次从磁盘中申请 4~5 个区;
页是innodb磁盘管理的最小单位,默认16k,可以通过innodb_page_size参数来修改,B+树的一个节点就是一页,大小也就是16k,以上只是一种组成方式,就类似于内存池由大块、小块组成,并不能确定了一颗B+树的大小
聚集索引
根据主键来构建的B+树,叶子节点中存放数据页(包含了所有数据),数据也是索引的一部分。
innodb当中
(1)叶子节点中的聚集索引,它的数据和索引也都在叶子节点当中;
(2)数据存储在主键的B+树。
myisam当中
(1)B+树的叶子节点并不存储数据,而是指针,指针指向数据存储在磁盘位置;
(2)具体的数据不是存储在B+树,而是存储在堆表。
所以myisam读取性能高。
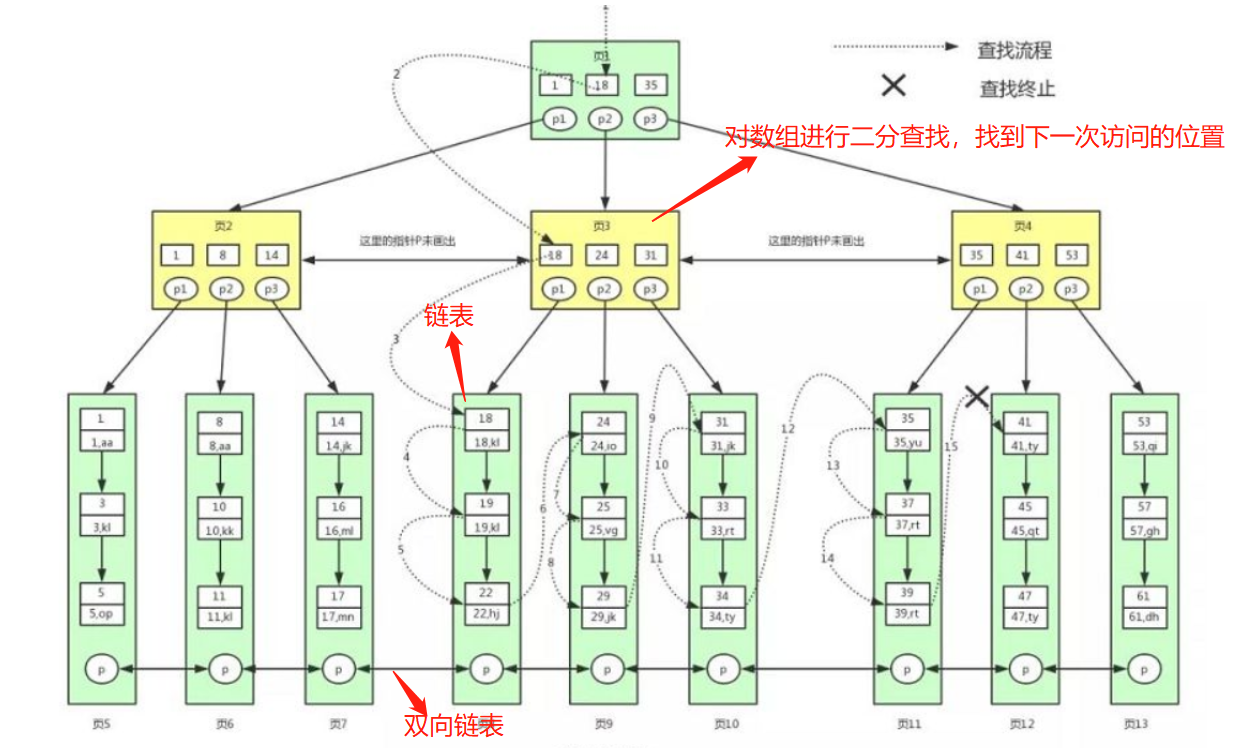
例如:select * from user where id 1 >= 18 and id < 40;在B+树中查找如下图所示,需要7次IO。
辅助索引
即不是根据主键来构建的B+树。
辅助索引的叶子节点不包含行记录的全部数据,除了用来排序的键值key还包含一个bookmark,该书签存储了聚集索引的key。所以,使用辅助所引查找时,如果通过辅助索引不能直接获取到select所需的所有字段数据,则先在辅助索引的B+树中进行查找,找到辅助索引对应的的key,由于该节点也存储了聚集索引的key,再到聚集索引的B+数中找key对应的行数据,本次IO访问的次数是辅助索引访问次数+聚集索引访问次数;如果通过辅助索引就能获取到查询字段的数据,则不会到聚集索引中查找,此时访问磁盘IO次数较少(因为辅助索引B+树高度一般低于聚集索引B+树的高度);所以辅助索引可以根据具体的业务场景来创建,进行优化。
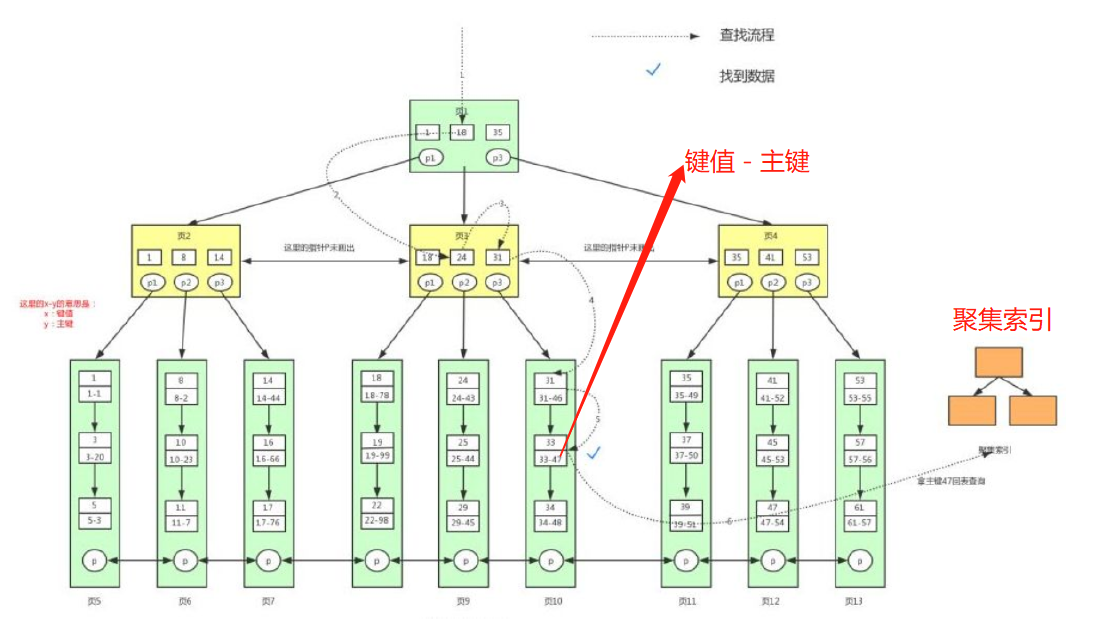
例如: 某个表 包含 id name lockyNum; id是主键,lockyNum存储辅助索引;执行select * from user where lockyNum = 33流程如下。
最左比配原则
对于组合索引,从左到右依次匹配,遇到> < between like就停止匹配。
覆盖索引
从辅助索引中就能找到数据,而不需要通过聚集索引查找,利用辅助索引树的高度一般低于聚集索引树的高度,较少访问磁盘IO,当辅助索引中包含索引key正好是select只要字段,此时不需要访问聚集索引,即可获取。
索引失效
(1)select ... where A and B 若 A 和 B 中有一个不包含索引,则索引失效;
(2)索引字段参与了运算,则失效;例如: from_unixtime(idx) = '2021-04-30';
(3)索引字段发生隐式转换,则失效;例如: '1' 隐式转换为 1;
(4)LIKE模糊查询,通配符%开头,则失效;如果%在后面是可以的,例如: select * from user where name like '%ark';
(5)索引字段上使用NOT <> !=,则失效;例如:判断 id <> 0 则修改为idx > 0 or idx < 0;
(6)组合索引中,没使用第一列索引,索引失效。
索引原则
(1)查询频次较高且数据量大的表建立索引;索引选择使用频次较高,过滤效果好的列或组合;
(2)使用短索引;节点包含的信息多,较少磁盘IO操作(如果索引字段长,B+树相应的高度会高);
(3)对于很长的动态字符串,考虑使用前缀索引;
(4)对于组合索引,考虑最左侧匹配原则和覆盖索引;把经常访问的索引放在最左边;
(5)尽量选择区分度高的列作为索引,该列相同的值越少越好;
(6)尽量扩展索引,在现有索引的基础上,添加复合索引;在原来的key上扩展,而不是新建一个key;
(7)不要select *;尽量只列出需要的列字段;
(8)索引列,列尽量设置非空,并给一个默认值
EXPLAIN
用来查看SQL语句的具体执行过程
原理:模拟优化器执行SQL查询语句,从而知道mysql是如何处理sql语句的
SHOW PROCESSLIST
查看连接线程,可以查看当前连接执行的sql,以及执行多久;如果要查看完整的sql语句,使用SHOW FULL PROCESSLIST,再进行优化。
