
基于概率的相似度定义方法
本文的主要内容来自百分点科技
问题定义:
本文在基于item协同过滤算法的框架下,定义了一种新的item相似度计算方法。该方法是一种基于概率的算法,即两个item的相似度为一个用户随机的选择item,同时选到这两个item的概率。本文的实验结果表明,本文的算法准确率要比传统的算法要好,并且本文也给出了该算法在hadoop上的实现过程。
方法:
1. 基本定义
首先定义了几个概念:
![]()
分别是选择item y的用户集合和用户u选择的item集合。
如果从item的角度来看,商品x被用户u选择户u选择的概率应该为这个item(x)的度比上所有user的数,即

如果从user的角度来看,用户u选择商品x的概率应该为这个用户的度比上所有item的数目,即

下图是用户选择商品的矩阵图,其中橙色的点表示用户喜欢相应的商品,图中没有标记出用户不喜欢商品

注:A表示所有的items U表示所有的users L(x)表示喜欢item(x)的users集 L(u)表示用户u所喜欢的items集
根据上述的定义,那些出现橙色点的概率应该为

其展开形式为

这些点在本文中定义为positive case,与positive case对应的是negative case,即用户不喜欢商品的概率

结合上述的两种情况,我们最终可以得到用户u选择商品x的概率为

2. 考虑数据density的影响

在上面两个图中,用户u和商品x都是一样,不同的是,左图在x和u附件橙色点比较少,而在右图,x和u附近的橙色点比较多,虽然是同样的用户和同样的商品,但是在上面两个图中计算出来的概率不一样的,左右俩图中A和U值是相等的,所以p(u,x)的值只受到L(u)和L(x)的影响,由于密度的不同,对于密度大的右图来说,item(x)被随机用户u随机选中的概率会大于左边,因此本文在原来的基础上加入了权重因子π来影响这种density的影响

令V为上图中的所有橙色点的总数目,则从平均的角度来看,每个用户橙色点的数目应该为

每一个item被用户喜欢的概率为

所以user喜欢某个item的概率等价于

于是

最终可推导出

最终本文定义的用户u喜欢商品x的概率为

3. Item的相似度定义方法
首先用户u同时喜欢商品x和y的概率为

而两个商品的交集为
![]()
因此两个商品的相似度为


求出了item之间的相似度矩阵,就可以利用基本的协同过滤框架来构造推荐集了由于本文中的item相似度是基于概率的,所以在进行推荐的时候也拓展了一个新的算法
4.算法描述
前面求出的基于概率的item相似度是基于user-item矩阵随机分布为前提的,但是我们现在知道了用户已经喜欢了某些item子集了,假设为y,所以用户由于喜欢y而喜欢item(x)的概率为
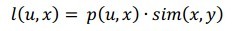
现在的问题是我们怎么把所有y的子集联合起来得出用户喜欢item(x)的概率,考虑到sim(x,y)的值表示x和y之间的概率相似度,亦即当
sim(x,y)=1表示俩者之间没有关系
sim(x,y)<1表示俩者之间存在反向关系
sim(x,y)>1表示俩者之间存在正相关关系
所以x,y的相似度可以转化为

于是在已知用户喜欢的item子集前提下用户喜欢item(x)的倾向为
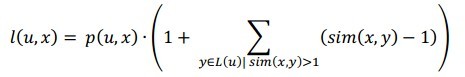
4. 实验结果
实验数据集取自Video-on-Demand和MovieLens

从上图中可以看出,本文的算法ProbSim要比其他的一些方法好要,除了基于矩阵分解算法(Vendor_B)和基于语义算法(Vendor_A)。在Precision指标上,本文算法又要好于这两个算法,如下图所示:

下图是MovieLens的实验结果

该文章中提供了一种分布式Mapreduce框架的编码思路,写得还算是挺清楚明了的,不过自己按着文章的思路来写代码的时候还是转了不少的弯路,例如先直接求出了user-item的概率矩阵,如果先直接求出这个矩阵,它的规模是1000万X1万,大概就是1000亿的数据级别,本人用的是自己的数据,规模只有250万X1500,大概40亿的级别,集群10个节点,运行到90%的时候单点空间不够任务竟然失败了,后来再认真的看了文章中关于概率相似度那一点的并行运算方法,经修改后才得以顺利运行。
不过我只做到求出item相似度而已,业务上没有必要求最后一步,所以也就没继续折腾下去了,感觉也不好写代码,因为里面也是要再一次生成一个user-item的概率矩阵。
最后给出一些大概的结果,sim在这里表示用户随机选择情况下item(x,y)同时出现的概率因子

5.结果对比
没办法,闲着蛋疼,而且也很手痒,所以还是把全部的步骤都走了一番
数据选取:2013-03-22~2013-03-31汽车网整站数据,主要用以生成项目相似度跟用户推荐列表,最终为每用户生成10个推荐项目
推荐结果集格式如下:
user array1<item> array2<item> match
第一列代表唯一用户,第二列代表用户有2013-04-01当天的访问项目,第三列代表根据用户先前的行为给出的10个推荐项目集,第四列代表俩个集的交集个数
随机抽取出20万用户,查准率只有1.32%,查全率为3.34%
这结果吓死哥了,不给力啊,难道是我哪里出错了不成
我自己弄了一套用关联规则做相似度的协同过滤算法的结果如下
查准率是3.87%,查全率是10.5%
这不科学啊。。。。好可怕
不过有一个发现就是ProbSim的结果多样性比较好,而关联规则的结果是比较偏向推热门
文章下载地址: http://openresearch.baidu.com/u/cms/www/201210/30145028ysy1.pdf
【个性化推荐引擎】基于概率的相似度定义方法: http://blog.baifendian.com/?p=1923


