


Log4j2集成ELK平台进行日志管理入门
背景介绍
当前分布式架构下多节点日志管理分析操作链条较长,过程繁杂。面对复杂场景,需要对大量日志分析的场景下,检索分析比较困难,多服务日志关联分析困难。业务日志存库开销大,体积增长快,日志文件分析难度大。
由此引入Log4j2集成ELK平台进行日志管理,重点解决分布式架构下日志收集与汇总管理分析问题。
ELK概述
ELK是Elasticsearch + Logstash + Kibana的缩写,ELK一般用来收集分布式架构下各个节点的日志,并进行统一地管理。
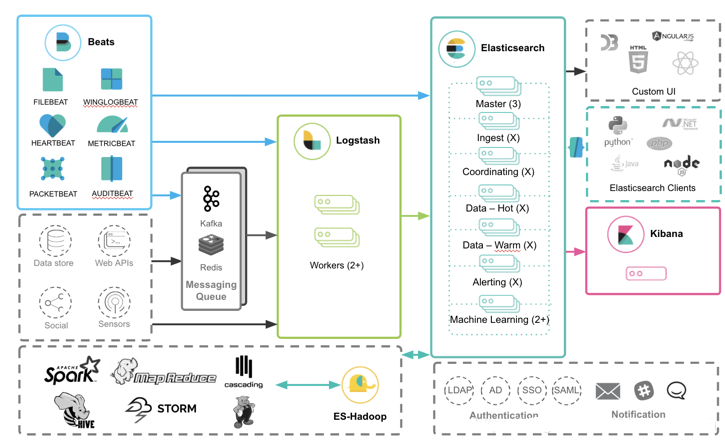
Elasticsearch
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去
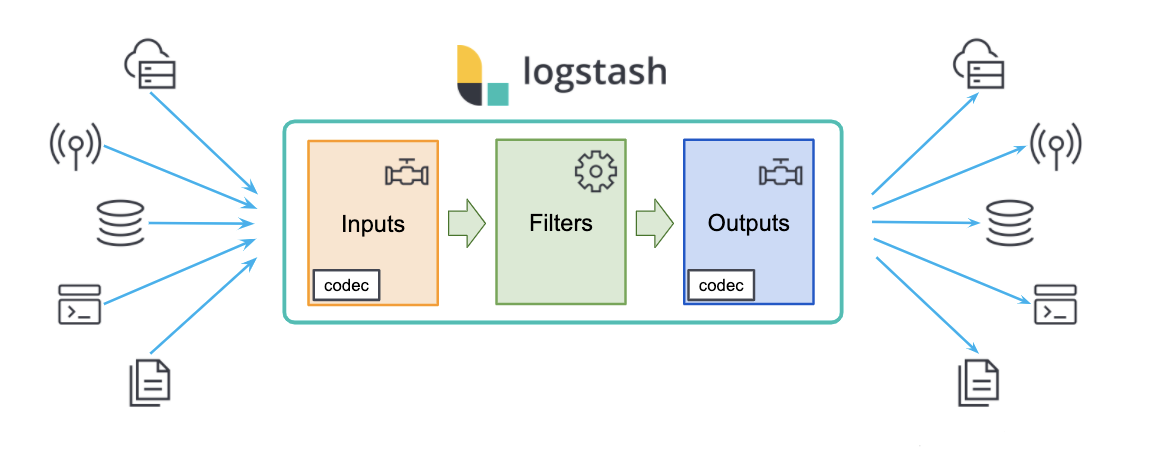
Logstash 是一个数据流引擎
- 它是用于数据物流的开源流式 ETL(Extract-Transform-Load)引擎
- 在几分钟内建立数据流管道
- 具有水平可扩展及韧性且具有自适应缓冲
- 不可知的数据源
- 具有 200 多个集成和处理器的插件生态系统
- 使用 Elastic Stack 监视和管理部署
Log4j2推送日志到ELK
-
Log4j2为我们提供SocketAppender,使得我们可以通过TCP或UDP发送日志
-
Socket方式连接Logstash的服务端,如果在连接期间,Logstash的服务停止了或者断掉了,就算接下来重启了Logstash,项目工程也无法自动重新连接上Logstash,除非重启项目工程。在生产环境中,Logstash自然是有可能半路出问题重启的,所以不能使用这种Socket方式来传输日志。
-
可以使用gelf的方式来传输日志到Logstash,本文基于Gelf插件的方式进行举例。
-
需要添加依赖
implementation "biz.paluch.logging:logstash-gelf:1.15.0" -
Logstash配置中数据输入配置需要配置为gelf的方式,见后文logstash.conf
-
Log4j2配置调整
- host是部署了Logstash服务端的地址,端口号要和Logstash里配置的一致
- 注意:Gelf Appender必须要配置到下面的Logger才能将日志输出到Logstash里
- Logstash/Gelf Loggers – log4j2 (paluch.biz)
<?xml version="1.0" encoding="UTF-8"?>
<!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL -->
<Configuration status="INFO" monitorInterval="5" packages="com.jiuqi.np.log.log4j2.appender">
<properties>
<!--设置日志在硬盘上输出的目录-->
<property name="logPath">${sys:user.dir}/acct_logs</property>
<property name="historyLogPath">${sys:user.dir}/acct_logs/history</property>
</properties>
<Appenders>
<Gelf name="logstash-gelf" host="tcp:10.7.0.25" port="9700" version="1.1" ignoreExceptions="true"
extractStackTrace="true" filterStackTrace="false">
<Field name="timestamp" pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ}" />
<Field name="level" pattern="%level" />
<Field name="simpleClassName" pattern="%C{1}" />
<Field name="className" pattern="%C" />
<Field name="server" pattern="%host" />
</Gelf>
<!-- 采用异步方式输出业务日志。 -->
<Async name='asyncDatabaseAppender' bufferSize="1024">
<AppenderRef ref="databaseAppender"/>
</Async>
</Appenders>
<Loggers>
<asyncRoot level="INFO" includeLocation="false">
<appender-ref ref="logstash-gelf"/>
</asyncRoot>
</Loggers>
</Configuration>
Kibana
Kibana也是一个开源和免费的工具,Kibana可以为Logstash和ElasticSearch提供的日志分析友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
Index Patten索引模式
要使用Kibana,就需要通过配置一个或多个索引模式来告诉它您想探索的 Elasticsearch 索引(相当于创建es连接)。创建连接之后可以:
- 在Discover中以交互方式探索数据。
- 在Visualize中以图表,表格,仪表,标签云等形式显示数据。
- 在Canvas演示文稿中展示数据。
- 如果数据包含地理数据,可使用地图Maps将其可视化。
- 另外,如果索引中含有一个时间戳字段,并且想将这个字段用于执行基于时间比较的操作,可选择 索引含有带时间戳的事件 选项,Kibana 会读取索引映射并列出包含时间戳的所有字段,从中选择需要的字段即可(例如@TimeStamp)。
- 默认情况下,Kibana 会限制基于时间的索引模式的通配符扩展,(因为这意义不大,且浪费时间,尽量用正常的比较操作)符,范围为当前选定时间内的索引数据。点击“当搜索时不要展开索引模式”选项来禁用此行为(即不走时间索引)。
Discover数据探索模块
数据探索(Discover)页面负责交互式地探索es数据:
- 可以访问与选定索引模式匹配的每个索引中的每个文档。
- 可以提交搜索请求、过滤搜索结果、查看文档数据。
- 还可以看到与搜索查询匹配的文档数,并获取字段值的统计信息。
- 如果索引模式中配置了时间字段,您还可以在这个页面的顶部看到基于时间分布的文档数量柱状图。
配置Kibana查看Elasticsearch的index数据
接下来就是最后一步了,通过Kibana来查看我们刚刚index到Elasticsearch里的数据。
启动了Kibana后,在浏览器访问10.7.0.25t:5601,进入界面后,操作如下:
- Management -> Index Patterns
- 输入index的名字,我们这里填的是
test-logstash;然后点击Next step - 在
Time Filter field name下方的下拉框里选择timestamp作为我们的一个排序字段,默认是desc,即递减排序 - 最后点击
Create index pattern
现在已经配置好了Index pattern,我们就可以直接在左侧菜单栏里的Discover去查看对应的index里的数据了。如果不出意外,现在在Discover里已经看到刚刚被我们index进去的日志信息了。
环境安装
Docker环境安装
基于Windows操作系统
-
开启Hyper-V
- 需要开启windows自带虚拟机支持Hyper-V
- Windows专业版或企业版自带Hyper-V,在“控制面板\启用或关闭Windows功能”勾选Hyper-V选项后重启即可
- 非Windows专业版或企业版需要先行安装Hyper-V,可编写脚本hyper-v.cmd,并管理员权限执行安装后重启即可。
pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i" del hyper-v.txt Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL -
下载并安装docker-desktop
- 地址 https://www.docker.com/products/docker-desktop
- 安装并运行
- 提示缺少WSL 2
- 重新运行docker-desktop
-
配置国内镜像源
- registry server是默认指向https://hub.docker.com/,可以通过切换至国内镜像仓库来提速
- Linux环境下用sudo vi /etc/docker/daemon.json添加registry-mirrors
- Docker Destop中到Preferences -> Docker Engine添加镜像配置
{ "registry-mirrors": [ "https://registry.docker-cn.com/", "http://hub-mirror.c.163.com/", "https://ustc-edu-cn.mirror.aliyuncs.com/", "https://hub.docker.com/" ] } -
测试验证
# 启动rabbitmq服务 docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq:management
基于Linux操作系统
此处安装除安装docker外,同时包含k8s安装步骤,按需选择即可
- 使用如下创建脚本install_docker_k8s.sh
- 赋权执行并按提示选项选择安装内容chmod +x install_docker_k8s.sh
#!/bin/bash
# Kubernetes部署环境要求:
#(1)一台或多台机器,操作系统CentOS 7.x-86_x64
#(2)硬件配置:内存2GB或2G+,CPU 2核或CPU 2核+;
#(3)集群内各个机器之间能相互通信;
#(4)集群内各个机器可以访问外网,需要拉取镜像;
#(5)禁止swap分区;
# 安装步骤
#1. 安装docker
#1.1 如果没有安装docker,则安装docker。会附带安装一个docker-compose
#
#2. 安装k8s
#2.1 初始化环境
#2.2 添加安装源
#2.3 安装kubelet、kubectl、kubeadmin
#2.4 安装master
#2.5 安装网络插件
set -e
# 安装日志
install_log=/var/log/install_k8s.log
tm=$(date +'%Y%m%d %T')
# 日志颜色
COLOR_G="\x1b[0;32m" # green
RESET="\x1b[0m"
function info(){
echo -e "${COLOR_G}[$tm] [Info] ${1}${RESET}"
}
function run_cmd(){
sh -c "$1 | $(tee -a "$install_log")"
}
function run_function(){
$1 | tee -a "$install_log"
}
function install_docker(){
info "1.使用脚本自动安装docker..."
curl -sSL https://get.daocloud.io/docker | sh
info "2.启动 Docker CE..."
sudo systemctl enable docker
sudo systemctl start docker
info "3.添加镜像加速器..."
if [ ! -f "/etc/docker/daemon.json" ];then
touch /etc/docker/daemon.json
fi
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": [
"https://5ajk0rns.mirror.aliyuncs.com"
]
}
EOF
info "4.重新启动服务..."
sudo systemctl daemon-reload
sudo systemctl restart docker
info "5.测试 Docker 是否安装正确..."
docker run hello-world
info "6.检测..."
docker info
read -p "是否安装docker-compose?默认为 no. Enter [yes/no]:" is_compose
if [[ "$is_compose" == 'yes' ]];then
info "7.安装docker-compose"
sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod a+x /usr/local/bin/docker-compose
# 8.验证是否安装成功
info "8.验证docker-compose是否安装成功..."
docker-compose -v
fi
}
function install_k8s() {
info "初始化k8s部署环境..."
init_env
info "添加k8s安装源..."
add_aliyun_repo
info "安装kubelet kubeadmin kubectl..."
install_kubelet_kubeadmin_kubectl
info "安装kubernetes master..."
yum -y install net-tools
if [[ ! "$(ps aux | grep 'kubernetes' | grep -v 'grep')" ]];then
kubeadmin_init
else
info "kubernetes master已经安装..."
fi
info "安装网络插件flannel..."
install_flannel
info "去污点..."
kubectl taint nodes --all node-role.kubernetes.io/master-
}
# 初始化部署环境
function init_env() {
info "关闭防火墙"
systemctl stop firewalld
systemctl disable firewalld
info "关闭selinux"
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/g' /etc/selinux/config
source /etc/selinux/config
info "关闭swap(k8s禁止虚拟内存以提高性能)"
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
info "设置网桥参数"
cat <<-EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system #生效
sysctl -w net.ipv4.ip_forward=1
info "时间同步"
yum install ntpdate -y
ntpdate time.windows.com
}
# 添加aliyun安装源
function add_aliyun_repo() {
cat > /etc/yum.repos.d/kubernetes.repo <<- EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
}
function install_kubelet_kubeadmin_kubectl() {
yum install kubelet-1.19.4 kubeadm-1.19.4 kubectl-1.19.4 -y
systemctl enable kubelet.service
info "确认kubelet kubeadmin kubectl是否安装成功"
yum list installed | grep kubelet
yum list installed | grep kubeadm
yum list installed | grep kubectl
kubelet --version
}
function kubeadmin_init() {
sleep 1
read -p "请输入master ip地址:" ip
kubeadm init --apiserver-advertise-address="${ip}" --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.19.4 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
mkdir -p "$HOME"/.kube
sudo cp -i /etc/kubernetes/admin.conf "$HOME"/.kube/config
sudo chown "$(id -u)":"$(id -g)" "$HOME"/.kube/config
}
function install_flannel() {
yum -y install wget
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
}
# 安装docker
read -p "是否安装docker?默认为:no. Enter [yes/no]:" is_docker
if [[ "$is_docker" == 'yes' ]];then
run_function "install_docker"
fi
# 安装k8s
read -p "是否安装k8s?默认为:no. Enter [yes/no]:" is_k8s
if [[ "$is_k8s" == 'yes' ]];then
run_function "install_k8s"
fi
基于Docker部署ELK
-
mkdir -p elasticsearch/data/ && chmod -R 777 elasticsearch/data/
-
部署目录文件结构,增加配置文件目录
. ├── config │ ├── elasticsearch.yml │ ├── kibana.yml │ ├── logstash.conf │ └── logstash.yml ├── docker-compose.yml └── elasticsearch └── data -
基于docker-compose部署,创建elk的容器网络:docker network create elk_net
-
启动docker-compose up -d
-
使用上述配置重启容器后,进入容器执行elasticsearch-setup-passwords interactive,可配置elastic、kibana、logstash_system 等账号的密码,设置完成后,登录Kibana的账户就是 kibana , elasticsearch的账户为 elastic
-
docker-compose.yml
version: '3' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.16.2 container_name: elasticsearch_server restart: always environment: - discovery.type=single-node - discovery.zen.minimum_master_nodes=1 - ES_JAVA_OPTS=-Xms3g -Xmx3g volumes: - ./elasticsearch/data:/usr/share/elasticsearch/data #- ./config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml ports: - 9200:9200 - 9300:9300 networks: elk_net: # 指定使用的网络 aliases: - elasticsearch #容器别名,elk_net网络中的其他容器可通过别名elasticsearch访问该容器 kibana: image: docker.elastic.co/kibana/kibana:7.16.2 container_name: kibana_server ports: - "5601:5601" restart: always networks: elk_net: aliases: - kibana environment: - I18N_LOCALE=zh-CN - ELASTICSEARCH_URL=http://elasticsearch:9200 - SERVER_NAME=kibana volumes: - ./config/kibana.yml:/usr/share/kibana/config/kibana.yml depends_on: - elasticsearch logstash: image: docker.elastic.co/logstash/logstash:7.16.2 container_name: logstash_server ports: - "9600:9600" - "9700:9700" restart: always environment: - LS_JAVA_OPTS=-Xmx256m -Xms256m volumes: - ./config/logstash.yml:/etc/logstash/conf.d/logstash.yml - ./config/logstash.conf:/etc/logstash/conf.d/logstash.conf networks: elk_net: aliases: - logstash depends_on: - elasticsearch entrypoint: - logstash - -f - /etc/logstash/conf.d/logstash.conf logging: driver: "json-file" options: max-size: "200m" max-file: "3" networks: elk_net: name: elk_net- elasticsearch.yml
cluster.name: "docker-cluster" network.host: 0.0.0.0 http.cors.enabled: true http.cors.allow-origin: "*" http.cors.allow-headers: Authorization xpack.security.enabled: true xpack.security.transport.ssl.enabled: true- kibana.yml
server.host: "0.0.0.0" server.shutdownTimeout: "5s" elasticsearch.hosts: [ "http://elasticsearch:9200" ] monitoring.ui.container.elasticsearch.enabled: true elasticsearch.username: "elastic" elasticsearch.password: "123456"- logstash.yml
http.host: "0.0.0.0" xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ] xpack.monitoring.enabled: true xpack.monitoring.elasticsearch.username: logstash_system xpack.monitoring.elasticsearch.password: 123456- logstash.conf
input { gelf { host => "0.0.0.0" port => 9700 use_tcp => true } } filter { mutate { lowercase => [ "logger", "level" ] } } output { elasticsearch { hosts => ["http://elasticsearch:9200"] index => "test-logstash" } }
