
Python之sklearn学习
1、安装sklearn
pip3 install sklearn -i https://pypi.tuna.tsinghua.edu.cn/simple
2、SVC测试分类法判断某点所在象限
import numpy as np from sklearn.svm import SVC X = np.array([[1, 1], [-2, 1], [-1, -1], [2, -1]]) y = np.array(['1', '2', '3', '4']) clf = SVC(gamma='auto') clf.fit(X, y) print(clf.predict([[100, 100]]))

这里使用的是SVC分类法,也就是监督学习法。一次性训练数据,生成模型并使用模型
3、可以增量学习的类

4、sklearn提供的模型
from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC, LinearSVC from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import Perceptron from sklearn.linear_model import SGDClassifier from sklearn.tree import DecisionTreeClassifier

一共分为:分类,回归,聚类,降维,一般项目主要总到分类和回归
模型:
分类:SVM、KNN、贝叶斯【多项式、高斯、伯努利】、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN
回归:支持向量机回归、k临近回归器、回归树、集成回归器
聚类:GaussianMixture【GMM】、k-means
降维:
分类器+模型选择:
MultiOutputClassifier(RandomForestClassifier()) # 随机森林+多输出分类器,对特征阈值判断很有效,可实现判断不同的阈值
OneVsRestClassifier(SVC) # 一对多分类器+SVC,实测当特征值过多,对阈值判断会出现错误
5、随机森林RandomForestClassifier,支持多标签输出
import numpy as np
import random
from joblib import dump
import os
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.multioutput import MultiOutputClassifier
from sklearn.multioutput import MultiOutputRegressor
from sklearn.linear_model import LinearRegression
from sklearn.multiclass import OneVsRestClassifier
# lr = LinearRegression()
# moedel = MultiOutputRegressor(lr)
model = MultiOutputClassifier(RandomForestClassifier())
# 身高 月收入 颜值
X = [[180, 20000, 90],
[160, 20000, 90],
[180, 3000, 90],
[180, 20000, 40],
[160, 3000, 40]]
Y = [['高', '富', '帅'],
['矮', '富', '帅'],
['高', '穷', '帅'],
['高', '富', '丑'],
['矮', '穷', '丑']]
model.fit(X, Y)
print(model.predict([[180, 20000, 90]]))
# [['高' '富' '帅']]
6、朴素贝叶斯多项式模型MultinomialNB是通过概率来计算结果
如根据一片文章出现"教育"和"科技"的次数来判断是教育类文章还是科技类文章
7、朴素贝叶斯高斯模型GaussianNB,支持在线学习
import numpy as np X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) Y = np.array([1, 1, 1, 2, 2, 2]) from sklearn.naive_bayes import GaussianNB clf = GaussianNB() clf.fit(X, Y) print(clf.predict([[-0.8, -1]])) clf_pf = GaussianNB() clf_pf.partial_fit(X, Y, np.unique(Y)) print(clf_pf.predict([[-0.8, -1]]))
8、朴素贝叶斯伯努利模型BernoulliNB
9、OneVsRestClassifier+SVC注意事项
标签不支持多状态,即某个参数只能有2种状态;
标签只能是数字0、1的格式,不能是字符串。
10、分类和回归的区别
如果希望知道参数的状态【有限个】则用分类;【如判断参数是否在阈值之内、判断一朵花的种类】
如果希望知道参数下一状态的取值则用回归。【如预测房价】
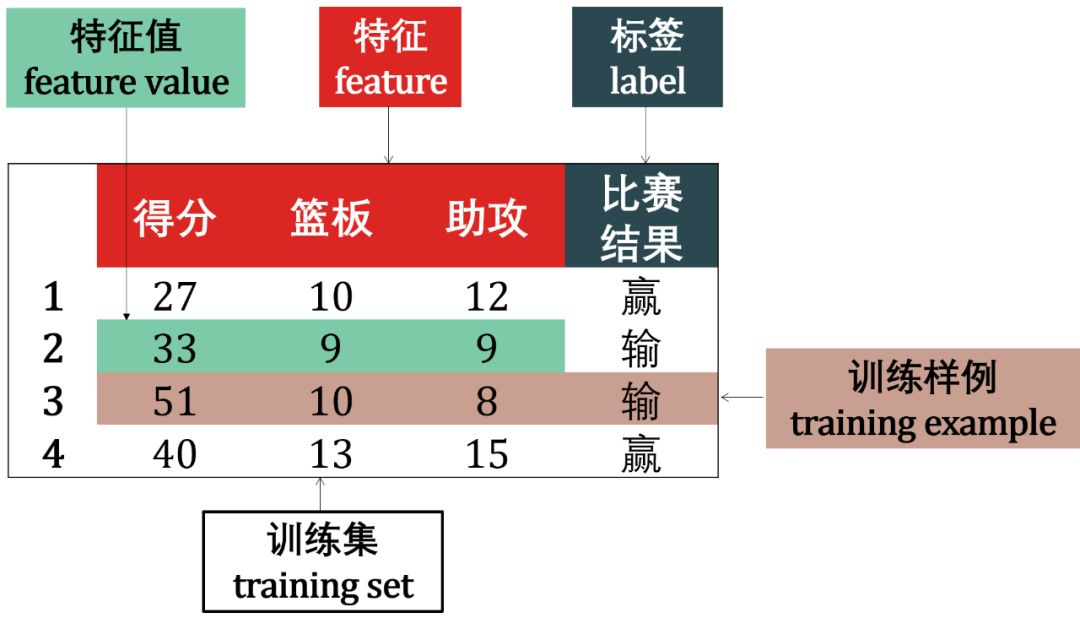
图片转自:https://blog.csdn.net/zandaoguang/article/details/103047249
11、multiclass与multilabel
这是个概念问题,而不是具体的函数。
multiclass是指一个模型所有特征可能对应多个分类,【如判断一条新闻是属于军事新闻、财经新闻、国际新闻】此时一条新闻只能取一种可能,
然后在已经是multiclass的情况下,如果的某一条特征取值有多个可能性,就是multilabel【如一个既属于帅哥,又属于有钱人,又属于高挑身材的人】
然后不管是multiclass还是multilabel,sklearn都提供两种分类器来完成分类,OneVsRestClassifier、OneVsOneClassifier【区别就在于建立的分类器个数不同,其他不用深究具体区别】。
那么模型如何知道是multiclass还是multilabel呢?通过fix(x,y)中的y,如果y的格式类似[ [1], [2], [3] ]就是多类,如果是[ [1, 2, 3], [1, 2, 3], [1, 2, 3] ]就是多标签
12、关于sklearn的预测和诊断
sklearn的诊断是通过分类来实现,即各训练数据之间没有关联,要么属于0,要么属于1,然后输入一条测试数据,输出一个0或1的label,即诊断这条数据属于什么类型
sklearn的预测是通过回归来实现,即各训练数据之间可能存在某种关联,在输入测试数据后,sklearn会结合自己的历史数据,查找最可能的取值,完成预测。
所谓的诊断和预测其实都是输出一个在输入数据那一刻最可能取到的label,而不是真正意义上一段时间后的取值【有大神通过平移使sklear能够预测未来的值,但原理没懂:】
13、LinearRegression使用
import numpy as np import random from joblib import dump import os from sklearn.svm import SVC from sklearn.svm import LinearSVC from sklearn.multiclass import OneVsRestClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.multioutput import MultiOutputClassifier from sklearn.multioutput import MultiOutputRegressor from sklearn.linear_model import LinearRegression from sklearn.multiclass import OneVsRestClassifier lr = LinearRegression() model = lr # 身高体重 X = [[180, 20000, 90], [160, 20000, 90], [180, 3000, 90], [180, 20000, 40], [180, 3000, 40], [160, 20000, 40], [160, 3000, 90], [160, 3000, 40]] # 0代表ok,1代表不ok Y = [[0, 0, 0], [1, 0, 0], [0, 1, 0], [0, 0, 1], [0, 1, 1], [1, 0, 1], [1, 1, 0], [1, 1, 1]] print(X, Y) model.fit(X, Y) print(model.predict([[170, 20000, 90]])) # print(model.coef_, model.intercept_) print(model.predict([[160, 3000, 40]])) # print(model.coef_, model.intercept_)
14、GMM的使用
import numpy as np import random import numpy as np from sklearn import mixture # 生成随机观测点,含有2个聚集核心 obs = np.concatenate((np.random.randn(100, 1), 10 + np.random.randn(300, 1))) clf = mixture.GaussianMixture(n_components=2) # print(obs) clf.fit(obs) # 预测 print(clf.predict([[0], [2], [9], [10]])) print(clf.score_samples([[0], [2], [9], [10]])) print(clf.predict_proba([[0], [2], [9], [10]]))
15、SGD的使用
from sklearn.linear_model import SGDClassifier X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) Y = np.array([1, 1, 1, 2, 2, 2]) model = SGDClassifier(shuffle=True, loss='log') model.partial_fit(X, Y, classes=np.unique(Y)) print(model.predict([[1, 1]]))
16、如何有效的过滤参数毛刺
1)、采样
通常传感器返回的数据频率较快,通过对这些数据采样,能够有效的过滤毛刺
长风破浪会有时,直挂云帆济沧海!
可通过下方链接找到博主
https://www.cnblogs.com/judes/p/10875138.html
