KMP算法
就我学过的所有处理字符串的算法(包括匹配算法、回文算法、后缀算法、字符串哈希),都离不开两个恒定的主题:递推构建和压缩信息。这一特征很明显和字符串的性质有关:子串众多,而子串之间互相关联性强。字符串的算法大多数都是 \(O(n)\) 的时间或空间复杂度,和“字符串本身包含的信息只有 \(O(n)\),只是它们互相组合产生 \(O(n^2)\) 的子串”有关。
KMP 算法,作为字符串的开端,也强烈的体现了这两个主题。
我们先来看一个自动机成品:
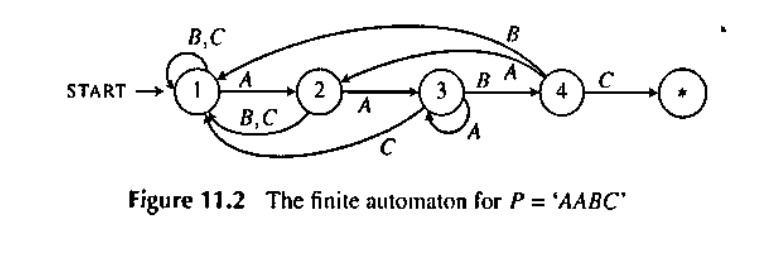
这是一个完整的自动机。它在字符集 \(\Sigma=\{A,B,C\}\) 上,对每个匹配的情况和下一个字符都有一条边。其边数是 \(|\Sigma|N\)。但是,首先,我们不知道如何快速构建这个匹配自动机,其次,我们认为这个自动机的信息还压缩的不够充分。
首先,我们把上面自动机的边分成两类。一类是“成功匹配”,一类是“匹配失败,和当前的某个后缀进行匹配”。
如果剥离所有的“失败匹配”,自动机就是这样的:

这一部分是匹配算法的主干,是很难压缩也无需压缩的。并且其建立也是很容易的,我们需要压缩的是“失败匹配”。
在压缩“失配边”之前,我们需要意识到一件事情:呈现在我们面前的自动机,是已经被压缩之后的结果。也就是,比如 \(3\) 节点在失配之后,\(C\) 可能的结果有很多,可能是先走到 \(2\) 再匹配到 \(3\),也可能是先走到 \(1\) 再匹配到 \(2\),我们是将其一一尝试之后,选择了最终的结果。那么我们不如把这个路径重新展开,换一种方式去压缩。
首先我们发现,当前失配之后,去哪里尝试,和新的字符无关。还是举这张图的例子,在 \(3\) 节点失配之后,不管是 \(A\) 还是 \(C\),都是先到 \(2\) 尝试匹配。虽然 \(A\) 匹配上了,\(C\) 匹配失败,但是这都是下一个子任务的事情了。我们展开之后的失配边目的不是找到一个成功的匹配,而是将问题引导到下一个子任务。所有子任务结合起来,直到有一个可以成功匹配的子任务终止。
这就是字符串算法中“递归构建”思想的体现之一:每次我们只是将问题引导向下一个子任务。那么,所有的失配边,不管是 \(A\),\(C\),\(D\),只要不能匹配,就全部合并起来去下一个子任务统一处理,这个合并的过程,就是借用这些文本串的相同点进行信息压缩。
这样,我们发现,每个节点最多只有一个失配边,而最多也只有一个匹配边。我们惊奇的发现边数变成了 \(2n\)。
到这里,我们的东西已经不是自动机了,因为它不符合“每次输入转移一次”的限制。我们不如新发明一种东西,来承载这些信息。
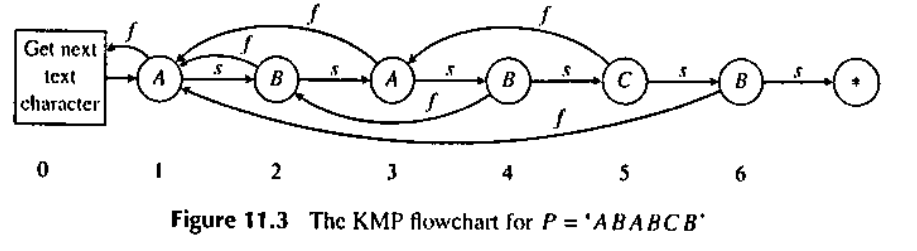
我们已经把我们需要的信息压缩到最优了,现在的问题是如何求取 \(f\) 边。
第一种理解:\(border\)
定义 \(border\) 为对于字符串的每个前缀 \(s\),其最长的真前缀使得 \(s\) 也存在一个和它相等的后缀。
我们考虑我们的 \(f\) 边是要干什么,是在不能匹配的情况下,找到最近的能匹配的地方,也就是尽可能的保留前面的匹配信息,不让其丢失从而导致需要回退重新计算使得复杂度退化。
而 \(border\) 恰恰能给我们提供这种信息。
我们发现,如果我们需要重新进行匹配,例如:
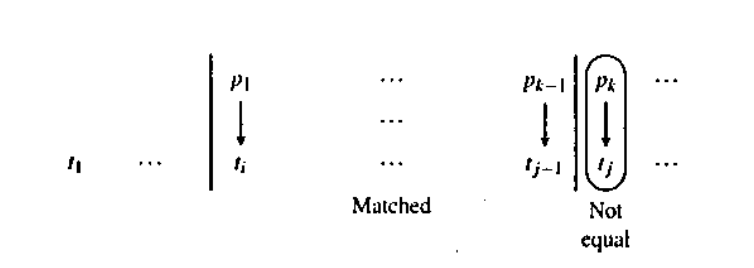
在这种情景下,我们需要找到新的尝试的地方作为 \(k-1\) 的 \(f\) 边。那么,假如我们新尝试的地方是 \(a\),那么我们要满足 \(p[1,a]\) 和 \(t[j-a,j-1]\) 匹配。而我们又需要 \(p[1,a]\) 和 \(t[i,i+a-1]\) 匹配,所以就有 \(t[j-a,j-1]\) 和 \(t[i,i+a-1]\) 匹配。而因为 \(p[1,k-1]\) 和 \(t[i,j-1]\) 匹配,所以 \(p[1,a]\) 和 \(p[k-a,k-1]\) 是匹配的。
所以,\(a\) 是一个满足对于 \(p\) 的前缀 \(p[1,k]\),其长度为 \(a\) 的前缀和后缀相等的地方。
而我们的失配边恰恰需要找到最大的这种地方进行匹配(匹配不到再往下找小的,而观察可以发现,这种性质在前缀和它满足要求的前缀之间具有传递性,所以我们可以放心的找最大的,因为其他的在最大的也失配之后一定会被扫描到。
也就是,这样:

这样,我们就知道了如何递归的处理失配,直到成功匹配。而每次计算新的 \(f\) 边正是依靠之前的 \(f\) 边,所以这又是递推思想。(因为现在的 \(f\) 边的很多信息和它的前缀是重合的)
第二种理解:自己匹配自己
我们每次把前缀 \(a\) 的自动机生成出来,然后用当前的字符 \(a\) 进行一次转移,除了第一次不。这样,在我们输入 \(a\) 的时候,一定是在前缀 \(a-1\) 建出的自动机中。它们的所有指针都是确定的。而前缀 \(a\) 去掉第一个字符之后在前缀 \(a\) 的自动机上的终止状态就是 \(a\) 的失配指针指向的位置。
这种算法似乎很妙,而且很容易拓展到多模匹配,但是和上面本质上同是一个算法。因为我们去掉当前的第一个其实就是“取出一个真后缀”,把当前的串当成模式串,也就找到了当前的最长的后缀和前缀相同的位置。
不过,我们也可以用别的方式来理解它。因为我们自动机的目的就是“找到最优的保存信息的匹配位置”,所以在自动机上跑出来的结果也一定是“最优的匹配位置”。
而其中则蕴含了一种重要的思想:用未完成构建的自动机本身去扩展自动机。这在 KMP 和 AC 机上尚不明显,但是 SAM 就尤其的运用了这种思想。
KMP 的实现:
非常简单,我们默认字符串下标从 \(1\) 开始。
//构造失配指针
int j=nxt[1]=0;
rep(i,2,m){
while(j&&t[i]!=t[j+1])j=fail[j];
if(t[i]==t[j+1])fail[i]=++j;
}j=0;
//进行匹配
rep(i,2,n){
while(j&&s[i]!=t[j+1])j=fail[j];
if(s[i]==t[j+1]){
j++;
if(j==m){
//匹配成功
j=fail[j];//需要注意,匹配到之后要自动失配一次,因为下面不可能用现在的匹配往下拓展了
}
}
}
