

一、小数据池
id可获取内存地址,==是判断两个对象的值是否相同,而is判断的是两对象的内存地址是否相同。
一个文件就是一个代码块(函数、类都是一个代码块);在文件交互命令里一行就是一个代码块。
同一个代码块有数据驻留机制,即同样的值赋给不同的变量,两个变量的内存地址是一样,这样就避免了内存的浪费。
i1 = 1000 i2 = 1000 print(i1 is i2)
驻留机制针对的对象:
int:任意数字
str:几乎所有字符串((字符串X数字)字符串含特殊字符或总字符大于20时例外)
在不同代码块间的缓存机制叫小数据池。
小数据池针对的对象有:
int:-5~256
str:一定规则的字符串
bool
空元祖
不管是同代码块的缓存机制还是不同代码块间的小数据池的驻留机制,其目的是相同的:
1、节省内存空间
2、提升性能
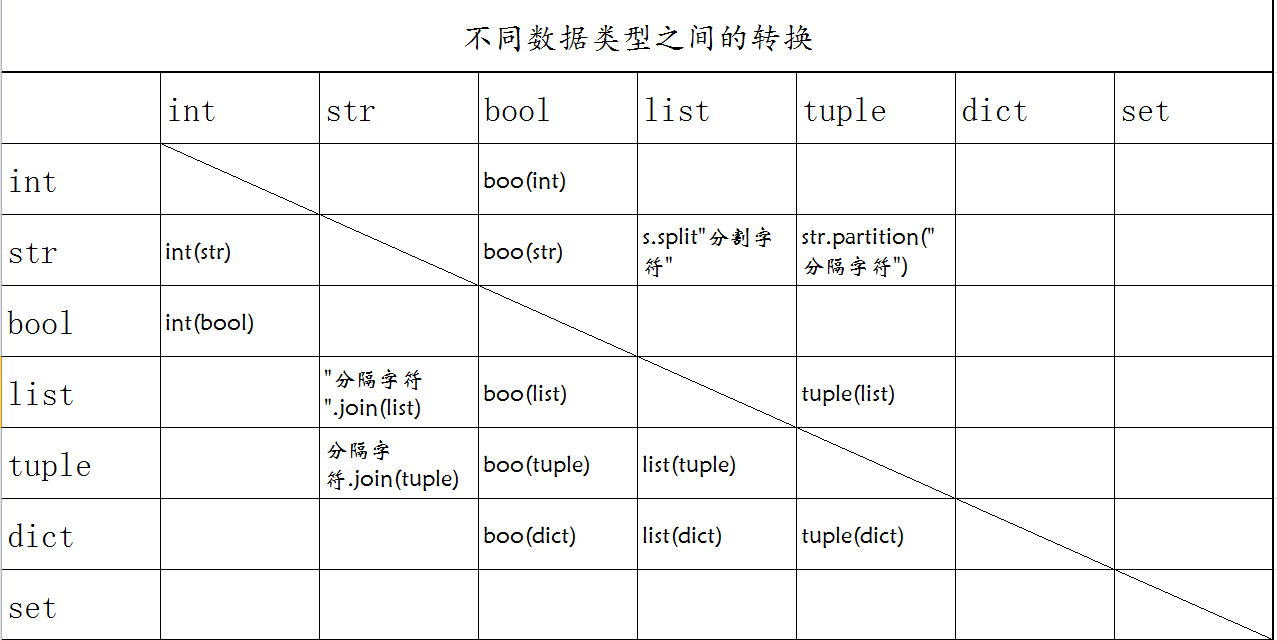
二、数据类型的补充
fromkeys可以往字典里添加值相同的不同键值对。如果值的数据类型可变,那么其在内存里面id一样。用法为:
dic = dict.fromkeys([key1,key2,key3],'value')
执行后再字典dic里会添加三个值均为'value的键值对,如果'value'是一个可变的数据类型,它在内存里的地址一样。
循环易犯的错误:
循环一个列表时要轻易去改变列表的长度,否则会影响最后的结果,详细实例如下:


循环,更改列表 例:将列表 l1 = [11,22,33,44,55] 的索引为奇数的对应的元素全部删除 方法一: del l1[1::2] print(l1) 方法二:(错误示例) for index in range(len(l1)): if index % 2 == 1: l1.pop(index) print(l1) ***循环一个列表时要轻易去改变列表的长度,否则会影响最后的结果 更正: for index in range(len(l1)-1,-1,-1): if index % 2 == 1: l1.pop(index) print(l1) 倒序遍历,这样即使更改了列表长度也不会影响到后面的循环 方法三: new_l = [] for index in range(len(l1)): if index % 2 == 0: new_l.append(l1[index]) l1 = new_l print(l1)
同样,循环一个字典时,不能改变字典的大小,否则会报错。详细示例如下:
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
将字典中的key中含有k元素的所有键值对删除.
错误示例:
for key in dic:
if 'k' in key:
dic.pop(key)
print(dic)
报错信息: dictionary changed size during iteration
更正:
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
for key in l1:
dic.pop(key)
print(dic)
