使用datax实现增量同步mysql数据库数据(定时任务)
使用datax来做数据全量同步很简单,增量同步该怎样做呢,接下来就一起试试吧
1.下载datax(前提CentOS已安装jdk等运行环境),解压(路径自定),使用centos7自带的python执行datax.py,运行自检
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz tar -zxvf datax.tar.gz && mv datax /usr/local/ cd /usr/local/datax/bin/ python datax.py /usr/local/datax/job/job.json
如果报错参考这篇博客:https://www.cnblogs.com/juanxincai/p/16258154.html
下面是解决办法

cd /usr/local/datax/plugin/reader ll -a [root@Data1 reader]# ll -a total 76 drwxr-xr-x 21 502 games 4096 Feb 19 21:05 . drwxr-xr-x 4 502 games 66 Feb 19 21:05 .. drwxr-xr-x 3 502 games 224 Feb 19 21:05 cassandrareader -rwxr-xr-x 1 502 games 212 Oct 12 2019 ._cassandrareader .... 删除._开头语文件 rm -f ._* cd /usr/local/datax/plugin/writer/ rm -f ._*
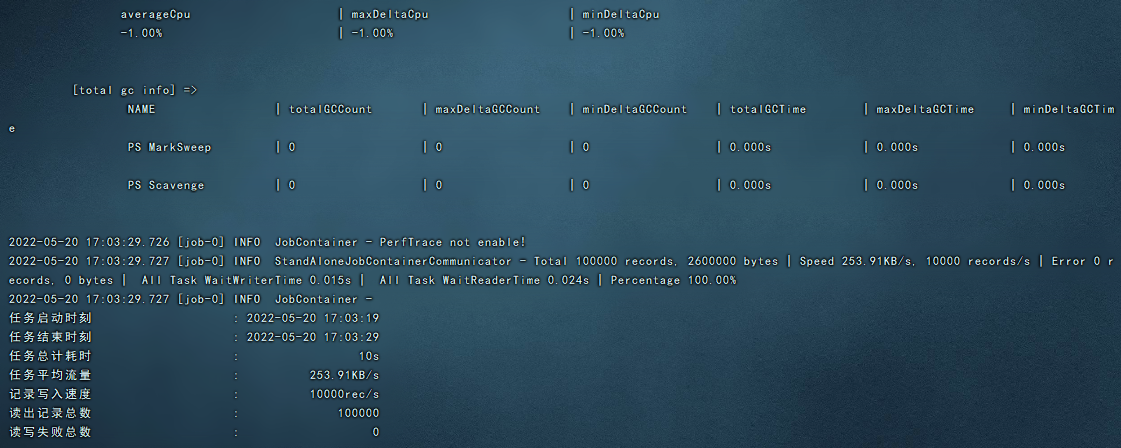
可以看到,自检成功
同步思路:
使用python查询数据源库表,查询到的最后一条数据的时间保存在一个txt文件中,下次执行再读取,加上cron任务从而定时同步时间间隔中的数据(增量同步)
想用pymysql就得升级python3,centos7自带python2,安装看这里:https://www.cnblogs.com/juanxincai/p/16280031.html
安装完成后再运行自检,执行报错看这里:https://www.cnblogs.com/juanxincai/p/16284779.html
接下来需要4个东西:
1,执行读取和写入的mysqltomysql.json,(我这里文件名叫new.json)里面有数据源库表的信息,读取的字段等设置,并且接收外部传入的两个时间参数(格式化为时间戳),路径为/usr/local/datax/job下,修改注意格式为标准json,格式化无问题再使用
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "用户名",
"password": "密码",
"where": "data_time >= FROM_UNIXTIME(${create_time}) and data_time < FROM_UNIXTIME(${end_time})",
"column": [
"id","data_time","name","age","insert_time"
],
"connection": [
{
"table": [
"表名"
],
"jdbcUrl": [
"jdbc:mysql://数据源IP:3306/数据库名?useUnicode=true&characterEncoding=utf8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "update",
"username": "用户名",
"password": "密码",
"column": [
"id","data_time","name","age","insert_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://目标库IP:3306/数据库名?useUnicode=true&characterEncoding=utf8",
"table": [
"表名"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}2.定时执行的python脚本,用于获取数据源库表最后一条数据时间并写入txt文件,执行datax.py运行上面的new.json(文件名:mysql2mysqlexecute.py)
#!/usr/bin/env python3
# coding: utf-8
import subprocess as sp
import time,os,sys
import pymysql
import pickle
print ("going to execute")
configFilePath = sys.argv[1]
logFilePath = sys.argv[2]
lastDataTime=""
def save_variable(v, filename):
f = open(filename, 'wb')
pickle.dump(v, f)
f.close()
return filename
def load_variavle(filename):
ff = open(filename, 'rb')
r = pickle.load(ff,encoding ="UTF-8")
ff.close()
return r
startTime=load_variavle('/usr/local/datax/job/tempTime.txt') #这个就是存放临时时间变量的txt文件,注意编码格式,读取起始时间
def do_sql(sql):
db = pymysql.connect(host = '数据源库IP',port = 3306,user = '用户名',passwd = '密码',db = '数据库名')
#创建连接(连接数据库)
cursor = db.cursor() #创建游标
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) #设置游标格式为字典格式,即取值时会以字典的形式呈现
cursor.execute(sql) #执行sql语句
rs=cursor.fetchall()
#for r in rs:
#print (r)
content=rs
db.commit() #提交,以保存执行结果
cursor.close() #关闭游标
db.close() #关闭连接
x = rs[0]['dataTime']
return x;
print("startTime=",startTime) #输出格式化的同步开始日期
startTimeArray = time.strptime(startTime, "%Y-%m-%d %H:%M:%S")
startTimeStamp = int(time.mktime(startTimeArray))
sql='SELECT CAST(data_time AS CHAR) as dataTime FROM 表名 ORDER BY data_time DESC LIMIT 1'
lastDataTime = do_sql(sql)
print("endTime=",lastDataTime)
lastDataTimeArray = time.strptime(lastDataTime, "%Y-%m-%d %H:%M:%S")
lastDataTimeTimeStamp = int(time.mktime(lastDataTimeArray))
try:
script2execute = "/usr/bin/python3 /usr/local/datax/bin/datax.py %s -p \"-Dcreate_time=%s -Dend_time=%s\" >> %s"%(configFilePath,startTimeStamp,lastDataTimeTimeStamp,logFilePath)
print("to be excute script:",script2execute)
os.system(script2execute)
#sp.run(script2execute)
except IOError:
print(IOError)
print("script execute ending")
save_variable(lastDataTime,'/usr/local/datax/job/tempTime.txt') #保存临时时间变量作为下次的开始时间
print("ending---")3.定时执行同步任务的sh脚本:(文件名:timeMission.sh),这里可以看到执行的时候将new.json文件位置传入,还有日志的路径
#! /bin/bash
source /etc/profile
/usr/bin/python3 /usr/local/datax/job/mysql2mysqlexecute.py '/usr/local/datax/job/new.json' '/usr/local/datax/job/test_job.log' '/usr/loal/datax/job/test_job.record'4.可以看到上面的读取与存放临时时间变量的文件名叫做:tempTime.txt ,自己新建就好,注意路径和编码格式
既然用到了sh,就记得给脚本赋予执行权限
chmod +x ./xxx.sh接下来就可以编写定时任务,这里我们使用corntab,有问题参考这篇:https://www.cnblogs.com/juanxincai/p/15852374.html
crontab -eSHELL=/bin/bash
*/5 * * * * /usr/local/datax/job/timeMission.sh退出保存 :wq 加上这两行,代表每5分钟执行一次timeMission.sh,也就是五分钟同步一次
crontab -l 可以看到,我们的定时任务已经写入
可以看到,我们的定时任务已经写入
systemctl reload crond.service
systemctl restart crond.service重启和重新加载cron服务,查看任务执行日志输出
tail -f /var/spool/mail/root 再看一下datax的运行日志
再看一下datax的运行日志
tail -200f /usr/local/datax/job/test_job.log 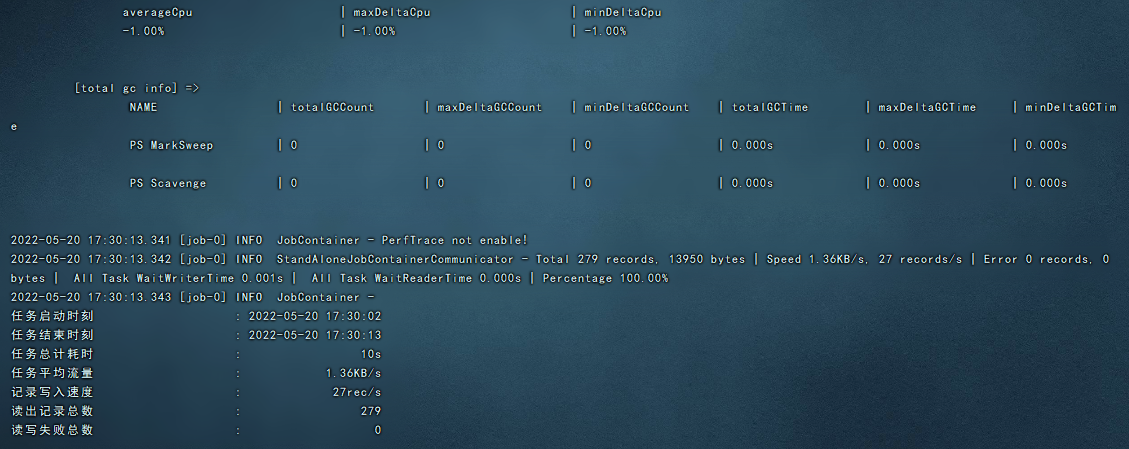 可以看到,数据已同步,具体还可以优化,请参考datax官方文档,搭建运行中间不要怕出问题,大胆尝试细心排错,有可能格式,执行权限,文件编码都会造成执行不成功,祝大家一次同步成功
可以看到,数据已同步,具体还可以优化,请参考datax官方文档,搭建运行中间不要怕出问题,大胆尝试细心排错,有可能格式,执行权限,文件编码都会造成执行不成功,祝大家一次同步成功


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话