InfluxDB与MySQL的性能测试
一、单线程插入查询对比
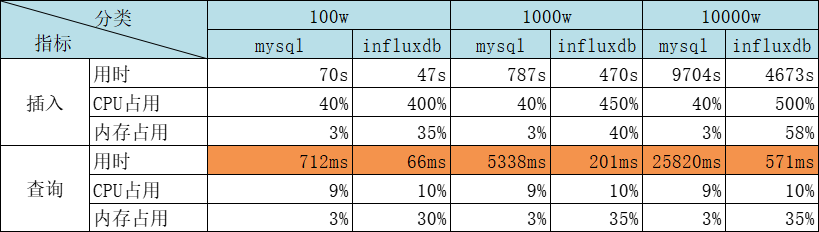
注:批量插入,每批1万条
配置:
CPU:16 Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz
内存:16G
磁盘:4T
MySQL: V5.7
InfluxDB: V1.8.0
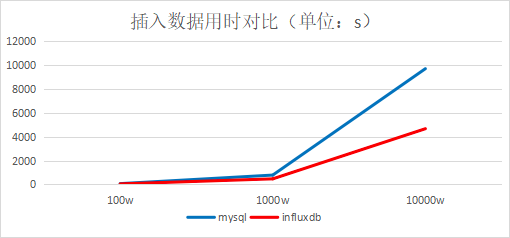

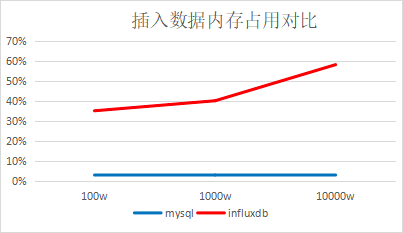

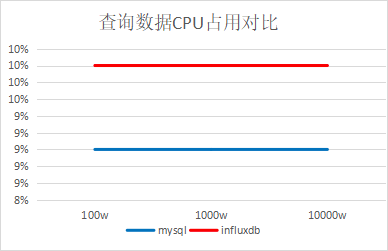

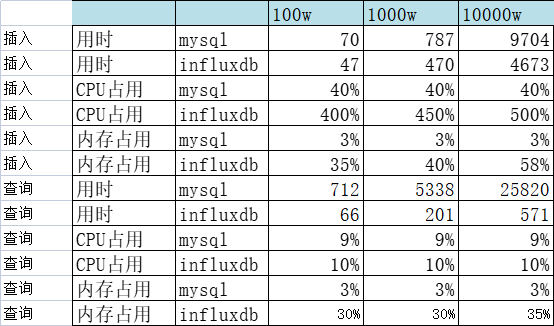
结论:插入速度InfluxDB是MySQL的两倍,查询速度InfluxDB是MySQL的45倍(查询数据量很少的情况,大约1000条左右)
二、MySQL和InfluxDB分别从一亿的表中取一定量数据对比
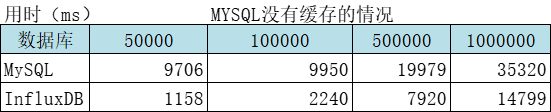
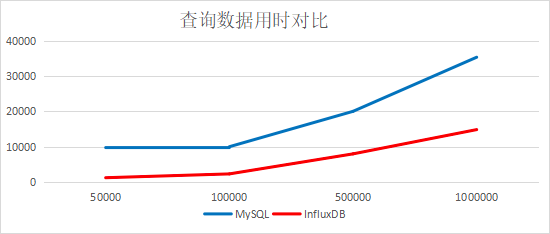
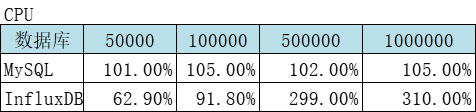
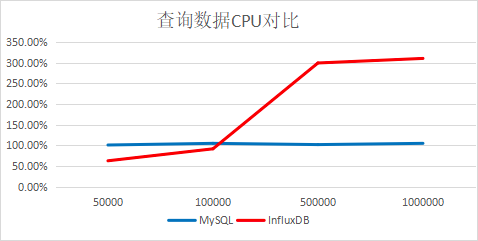
结论:查询速度InfluxDB是MySQL的2倍多
三、多个线程分别取十万条数据对比

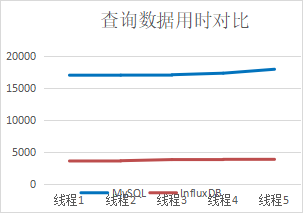
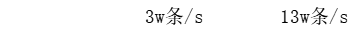
结论:多线程下查询速度InfluxDB是MySQL的4倍
四、多个线程分别插入2000万数据

结论:插入速度InfluxDB是MySQL的2倍多
五、结论总结
单线程:写入速度InfluxDB是MySQL的2倍左右
查询速度InfluxDB是MySQL的2倍左右
多线程:写入速度InfluxDB是MySQL的2.5倍左右
查询速度InfluxDB是MySQL的4倍左右
写数据瓶颈在于带宽
InfluxDB应用场景
InfluxDB(时序数据库),常用的一种使用场景:监控数据统计。每毫秒记录一下电脑内存的使用情况,
然后就可以根据统计的数据,利用图形化界面(InfluxDB V1一般配合Grafana)制作内存使用情况的折线图;
可以理解为按时间记录一些数据(常用的监控数据、埋点统计数据等),然后制作图表做统计;
InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便,适合用于包括DevOps监控,应用程序指标,物联网传感器数据和实时分析的后端存储。类似的数据库有Elasticsearch、Graphite等。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话