
awk命令详解及应用技巧
awk是Linux中三剑客之一,awk在对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,可以根据按行按列的操作金属数据分析。相比于sed,优势在于取行取列最快,并且应用数组有计算的功能。sed是换数据最快最好用的。
一、 AWK的基础用法
1 awk基本使用格式:
awk [参数] ‘模式[动作]’ 文件名
其中:
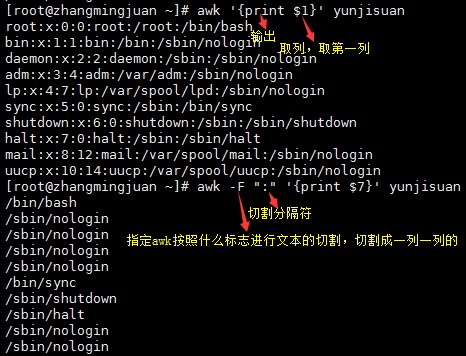
参数:-F “ ” 指定分列符,默认是以空格作为分列符的
模式:内容的查找范围→过滤的文件内容(按行取数)
NR 记录符,取行,不是真正的行数,是awk处理过的行数(如NR==2)
/ / 取内容(如/^b/)
动作:{}里面可以有多个动作,语句间用;分隔
awk –F “[ :]+” ‘NR==2{print $13,14}’取多列用,分隔
$ 表示取列的意思
$NR 表示取最后一列
$0 表示取出所有列

2 awk执行过程
BEGIN
1)awk读入第一行内容
2)判断是否符合模式中的条件
a,如果匹配则执行对应的动作
b,如果不匹配条件,继续读取下一行
3)继续读取下一行
4)重复过程1-3,直到读取到最后一行
END
注:BEGIN和END只执行一次,中间部分有几行执行几次
3 awk完整使用格式:

(1)BEGIN模块:在awk读取文件之前执行一次,一般用来定义内置变量,也可以输出表头
(2)END 模块:在awk读取玩所有的文件的时候,在执行END模块,一般用来输出一个结果(累加、数组结果),也可以是和BEGIN模块类似的结尾标识符
(3)关于行:
RS:(record separator)读入换行符,行与行之间怎么分隔,默认是\n
ORS:(output record separator)输出换行符,默认也是\n
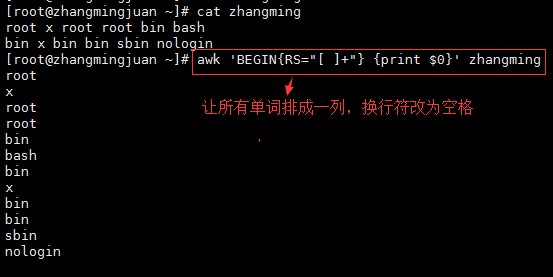
注:awk中可以通过BEGIN模块来重新定义修改变量值,如BEGIN{RS=“/”}
awk对每一行的记录号都有一个内置变量NR来保存,没处理一次,NR自动加一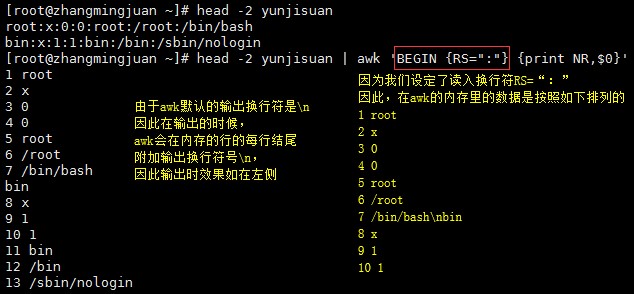
(4)关于列:
FS:(field separator)输入(列)分隔符。默认空格做分隔符
命令:
①-F参数:-F “:”
②BEGIN模块:‘BEGIN{FS=“:”}
注:默认awk中是以空格作为分隔符的,但是默认的分列符是将内容前后空格都去掉以后,再算空格的,不同于指定空格作为分隔符。
二、awk模式与动作
1 模式(过滤条件)分为:
①正则表达式作为模式(符号、字符)
②比较表达式作为模式(大小)
③范围模式
④特殊模式BEGIN和END
(1)正则表达式作为模式:(/^r/ 以…开头)
awk支持所有正则,默认不支持{},加参数—posix
正则表达式的运用,默认是在行内查找匹配到的字符串,若有匹
配则执行动作;但有时候需要固定的列来匹配指定的内容(加~)
~正则匹配操作符,用于对记录或区域的表达式进行匹配
|
awk正则中 |
^或$是匹配一个字符串的开头或结尾 |
|
sed和grep |
^或$是匹配行的开头或结尾 |




![]()

(2)比较表达式作为模块:(比较大小,相等)
awk –F ‘$5==”root”’ test
(3)范围模式
(4)BEGIN模式和END模式
BEGIN模块:
② 变量赋值:BEGIN{a=1;b=2;print a,b,a+b}
③ 修改内置变量:BEGIN{FS=”[ :]+”}
④ 输出表头:BEGIN{print “username”,”UID”}
⑤ 计算:BEGIN{print 10/3}
END模块:
最后awk读完所有文件时,再执行END模块,一般用来输出一个结果(累加,数组结果),也可以是和BEGIN模块类似的结尾标识。
应用:


▲企业应用:
?按单词出现频率降序排序(计算文件中每个单词的重复数量)
需掌握的关于统计的几个命令
uniq 去重 (参数-C 去重的同时计数)
sort 排序,默认是按26个字母排序,第一列
-n 按数字进行排序
-r 逆转排序
-k 指定按哪一列排序

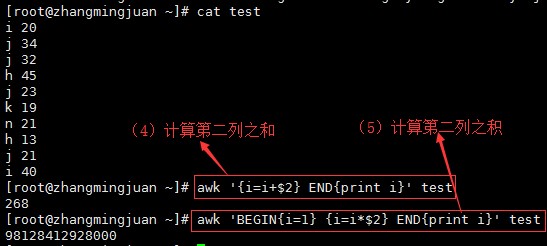
以上,可以完成排序,去重任务,但是不能计算,故下面引入数组。
AWK数组:
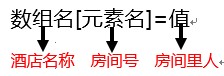
for (i in h) print i,h[i]
其中,
i 是变量,i里存的书房间号,特点:不会重复
in 变量从哪里取值
h 数组名
应用:awk最重要的一个功能是计数,而数组是在awk里最大的作用是去重

(1)去重并计数(统计重复数)

(2) 去重并计算

数组的房间号的一个特点:不会重复。故经常将要去重的项当成房间号。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号