

传统分布式共识算法整理
拜占庭问题
为什么拜占庭节点数必须<总节点数的1/3?
简单说一下论证过程, 假设总数N个节点, f个fault节点, 那么必须接收到N-f个消息应答, 就能够判断出结果(因为fault节点可能不发送应答). N-f个应答中有f个可能是假的(fault节点发出的), 那么真实的是N-f-f, 要求真实的应答大于假的应答, 即N-f-f > f ==> N > 3f.
所以: N_min = 3f + 1
pbft拜占庭容错算法
这是一种基于消息传递的一致性算法,算法经过三个阶段达成一致性,这些阶段可能因为失败而重复进行。
假设节点总数为3f+1,f为拜赞庭错误节点:
1、当节点发现leader作恶时,通过算法选举其他的replica为leader。
2、leader通过pre-prepare 消息把它选择的 value广播给其他replica节点,其他的replica节点如果接受则发送 prepare,如果失败则不发送。
3、一旦2f个节点接受prepare消息,则节点发送commit消息。
4、当2f+1个节点接受commit消息后,代表该value值被确定
5、最终client如果收到f+1个相同的reply就可确认
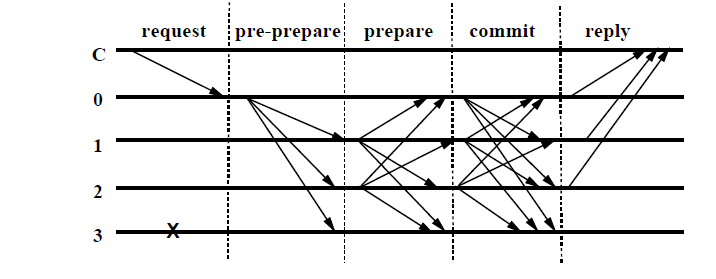
如下图表示了4个节点,0为leader,同时节点3为fault节点,该节点不响应和发出任何消息。最终节点状态达到commited时,表示该轮共识成功达成。
prepare和commit阶段为何都要2f+1个节点反馈确认?(这2f+1并不一定是相同的)
对于prepare和commit来说,节点需要在2f+1个状态复制机的沟通内就要做出决定,这是刚好可以保证一致性的,考虑最坏的情况:我们假设收到的有f个是正常节点发过来的,也有f个是恶意节点发过来的,那么,第2f+1个只可能是正常节点发过来的。(因为我们限制了最多只有f个恶意节点)由此可知,“大多数”正常的节点还是可以让系统工作下去的。所以2f+1这个参数和n>3f+1的要求是逻辑自洽的。
client为何只需要f+1个相同的回复就可确认?
之前我们说,prepare和commit阶段为何都要2f+1个节点反馈,才能确认。client只需要f+1个相同的reply就可以了呢?我们还是来考虑最坏的情况,我们假设这f+1个相同的reply中,有f个都是恶意节点。
所以至少有一个rely是正常节点发出来的,因为在prepare阶段,这个正常的节点已经可以保证prepared(m,v,n,i)为真,所以已经能代表大多数的意见,所以,client只需要f+1个相同的reply就能保证他拿到的是整个系统内“大多数正常节点“的意见,从而达到一致性。
如果primary是恶意节点呢?
对于一致性,我们可以这么看:如果prepared(m,v,n,i)为真,那么prepared(m’,v,n,j)一定是错误的,因为对于同一个提案我们不可能有两种结果,从而保证整个系统的一致性。
假设primary节点是恶意的,那么意味着在replicas节点中⾄多有f-1个恶意的节点,prepared(m,v,n,i)为真,则证明有f+1个善意节点达成了了⼀致,prepared(m’,v,n,j)为真,意味着另外f+1个善意节点达成了一致,因为系统中只有2f+1个善意节点,因此最少有⼀个善意节点发送了两个冲突的prepare消息,这是不可能的。所以prepared(m,v,n,i)为真,那么prepared(m’,v,n,j)是错误的。
优点:
上述共识算法都脱离不了币的存在,系统的正常运转必须有币的奖励机制,系统的安全性实际上是由系统币的持有者维护保证。当我们区块链系统实际运用到商业应用时,由其承载的资产价值可能远远超出系统发行的币的价值,如果由币的持有者保证系统的安全及稳定性将是不可靠的 。
1)系统运转可以脱离币的存在,pbft算法共识各节点由业务的参与方或者监管方组成,安全性与稳定性由业务相关方保证。
2)共识的时延大约在2~5秒钟,基本达到商用实时处理的要求。
3)共识效率高,可满足高频交易量的需求。
缺点:
仅仅适用于permissioned systems (联盟链/私有链)。
通信复杂度过高,可拓展性比较低,一般的系统在达到100左右的节点个数时,性能下降非常快。
PBFT在网络不稳定的情况下延迟很高。
应用:央行的数字货币、布萌区块链。
参考
https://zhuanlan.zhihu.com/p/53897982
