
知识图谱表示学习与关系推理(2016-2017)(三)
笔者:整理2016-2017年ACL、EMNLP、SIGIR、IJCAI、AAAI等国际知名会议中实体关系推理与知识图谱补全的相关论文,供自然语言处理研究人员,尤其知识图谱领域的学者参考,如有错误理解之处请指出,不胜感激!(如需转载,请联系本人:jtianwen2014,并注明出处)
ISGIR 2016
Hierarchical Random Walk Inference in Knowledge Graphs
- 作者:Qiao Liu, Liuyi Jiang, Minghao Han, Yao Liu, Zhiguang Qin
- 机构:School of Information and Software Engineering, University of Electronic Science and Technology of China
--------论文掠影--------
本文面向的任务是基于知识图谱的关系推理。本文通过对比考察PRA方法和TransE方法在关系推理上的执行效果并分析原因,在PRA基础上提出层次的随机游走算法HiRi进行实体关系推理。
本文首先叙述了基于知识图谱的关系推理的相关工作,大体分为三种方法:首先是统计关系学习方法(SRL),如马尔科夫逻辑网络、贝叶斯网络,但这类方发需要设计相应的规则,因此没有很好的扩展性和泛化性;嵌入式表示的方法,旨在将实体和关系映射为空间中的向量,通过空间中向量的运算来进行推理(如TransE),该方法取得了较好的准确率,但分布式表示的解释性不强,另外,较难实现并行计算;基于关系路径特征的随机游走模型,该方法可以进行并行计算,具有较好的执行效率,但准确率与召回率相比嵌入式表示学习的方法存在劣势。本文的想法是:是否可以设计算法同时实现随机游走模型的执行效率以及保留嵌入式表示学习方法的准确率?
--------方法介绍--------
本文对TransE方法(嵌入式表示学习的代表)和PRA方法(随机游走模型的代表)进行对比,在一对多、一对一、多对多、多对一这四类关系上进行对比分析:

对比发现:在1:M关系上,PRA远不如TransE;但在M:1关系上,两者很接近。有此现象,本文的第一个假设认为可以将知识图谱看做无向图,以此来规避1:M关系上的弱势。
另外,PRA方法在M:M关系上也只达到了TrasnE方法效果的一半,本文认为这说明了PRA在多对多关系上抽取的路径特征并没有充分地利用多对多关系产生的簇中的连接信息(文中有举例说明这一点)。相比而言,嵌入式学习的方法由于将知识图谱全局信息编码到向量空间里,所以可以充分利用到这种信息。
在利用多对多推理关系时,经常会用到关系的反向,即从尾实体到头实体的方向,这种推离的方法可以使用odd-hop随机游走模型来建模,基于此本文的第二个假设是:**具有拓扑结构的关系明确的簇可能会涵盖对推理很有帮助的信息,那么,基于关系学习算法的随机游走可以增强推理能力。 **
本文提出了一种层次化推理的架构,共分为三个部分:全局推理、局部推理、推理结果融合,结构框图如下:

全局推理是利用PRA算法进行推理,以得到三元组成立的概率\(f(h,r_i,t)\);局部推理时在特定关系的子图(簇)上计算一个3跳的概率矩阵,以得到存在可能该关系的三元组概率\(g(h,r_i,t)\),由于是在一个簇上进行的,这是一个局部的推理。融合的过程是利用一个线性模型对两部分的概率融合,以得到最终的概率。
笔者:本文通过分析PRA与TransE的在不同类型关系上的差距,提出了两个假设,并在此基础上提出层次化的推理方法HiRi,即在全局和局部分别进行关系推理,最终融合在一起获得推理结果。本文在第二个假设的提出上没有给出太多明确的解释,所举的例子和该假设的提出在递进关系上有些牵强,笔者未理清思路。另外,3跳的由来是否来自于“关系-关系反向-关系”路径,即3跳回到原关系?对于假设一,将关系看做无向的,会带来哪些不良后果?前人是否有这方面的探讨?
IJCAI 2016
From One Point to A Manifold: Knowledge Graph Embedding For Precise Link Prediction
- 作者:Han Xiao, Minlie Huang, Xiaoyan Zhu
- 机构:Dept. of Computer Science and Technology, Tsinghua University
--------论文掠影--------
本文提出:目前已有的知识表示学习方法无法实现精确链接预测,本文认为有两个原因导致了这一现象的出现:ill-posed algebraic problem、adopting an overstrict geometric form。
其中,ill-posed algebraic problem指的是:一个方程组中的方程式个数远大于变量个数。本文以翻译模型为代表叙述这一问题。翻译的目的是,对知识库的三元组的嵌入式表示满足\(\boldsymbol {\rm {h_r+r=t_r}}\),如果三元组的数量为\(T\),嵌入式表示的维度为\(d\),那么一共有\(T*d\)个方程式,而所需要学习的变量一共有\((E+R)*d\),其中\(E,R\)表示实体和关系类型的数量。由于三元组的数量远大于实体和关系类型的数量,那么这种翻译模型存在严重的ill-posed algebraic problem问题。
对于一个ill-posed algebraic系统,所求得的解经常是不精确且不稳定的,这也正是以往方法无法进行精确链接预测的原因之一。为此,本文提出一个基于流形(manifold)的原则,用\(\mathcal{M}(\boldsymbol {\rm {h,r,t}})=D_r^2\)用来代替\(\boldsymbol {\rm {h_r+r=t_r}}\),其中\(\mathcal{M}\)是流形函数。
另外,对于TransE的方法,对于给定的头实体和关系,应用于\(\boldsymbol {\rm {h+r=t}}\),所得到的尾实体几乎是一个点,这对于多对多关系而言显然是不正确的,这是一种overstrict geometric form。前人的一些方法如TransH、TransR将实体和关系映射到一些与关系相关的子空间中来缓解这一问题,然而,这种问题在子空间中仍然存在。这种过于严苛的形式或导致引入大量的噪声元素,在链接预测的过程中无法准确预测。
如下图所示,越靠近圆心组成正确三元组的可能性越大,蓝色为正确的答案,红色为噪声,其中TransE的方法无法很好地区分,而本文提出的ManifoldE可以很好的区分噪声数据。

--------方法介绍--------
本文提出用\(\mathcal{M}(\boldsymbol {\rm {h,r,t}})=D_r^2\)用来代替\(\boldsymbol {\rm {h_r+r=t_r}}\),其中\(\mathcal{M}\)是流形函数。打分函数定义为:
对于\(\mathcal{M}\)的定义,其中一种以球体为流形。即对于给定头实体和关系类型,尾实体在向量空间中分布在以\(\boldsymbol {\rm {h+r}}\)为球心的球面上,此时:
这里的向量可以应用Reproducing Kernel Hilbert Space (RKHS)映射到Hilbert空间,以更高效地表征流形。
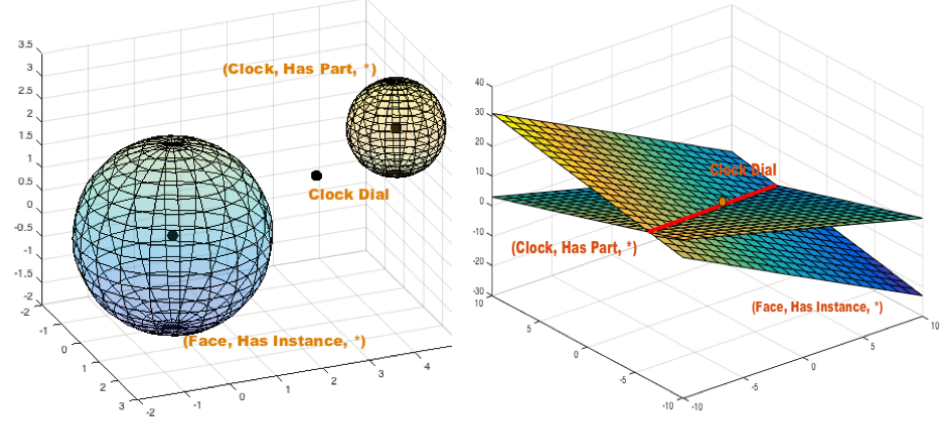
考虑到球体不易相交,而这可能导致一些实体的损失,本文叙述可以以超平面为流形。即对于给定头实体和关系类型,尾实体位于以\((\boldsymbol {\rm {h+r_{head}}})^{\rm {T}}\)为方向、偏移量与\(D_r^2\)相关的超平面上。在空间中,只要两个法向量不平行,这两个超平面就会有相交。流形函数定义如下:
本文叙述为了增加给定头实体和关系推理出精确的尾实体数量,对向量绝对值化:
其中,\(|\boldsymbol {\rm {w}}|=(|w_1|,|w_2|,|w_3|,...,|w_n|)\)。
对于以往方法存在的ill-posed问题,本文的方法对其较好地解决。以球形为例,本文对于每个三元组只对应一个等式:\(\sum_{i=1}^{d}(h_i+r_i-t_i)^2=D_r^2\),所以如果满足\(d\geq \frac {\#Equation}{E+R}=\frac {T}{E+R}\)。要满足这一条件只需适当增加向量的维度,从而较好的实现精确预测。
训练的过程是增加正例的分数,而减小负例的分数,目标函数如下:
实验结果显示该方法较好的实现了精确链接预测(hit@1):

笔者:本文提出之前的表示学习无法较好的实现精确链接预测,并提出造成该问题的两点原因:ill-posed algebraic problem、adopting an overstrict geometric form,并针对这两个点问题切中要害提出基于流形的表示学习方法,实验结果显示该方法较好的实现了精确链接预测。
Text-enhanced Representation Learning for Knowledge Graph
- 作者:Zhigang Wang and Juanzi Li
- 机构:Tsinghua University
本文面向知识图谱的表示学习任务,提出利用外部文本中的上下问信息辅助知识图谱的表示学习。
本文叙述:TransE、TransH、TransR等方法无法很好的解决非一对一关系,而且受限于知识图谱的数据稀疏问题,基于此本文提出利用外部文本中的上下问信息辅助知识图谱的表示学习。类似距离监督,本文首先将实体回标到文本语料中;以此获取到实体词与其他重要单词的共现网络,该网络可以看做联系知识图谱与文本信息的纽带;基于此网络,定义实体与关系的文本上下文,并将其融入到知识图谱中;最后利用翻译模型对实体与关系的表示进行学习。
下图是一个简单的图示:

Representation Learning of Knowledge Graphs with Hierarchical Types
- 作者:Ruobing Xie, Zhiyuan Liu, Maosong Sun
- 机构:Tsinghua University
本文面向知识图谱的表示学习任务,提出融入实体类型信息辅助知识图谱的表示学习。
本文叙述:目前的大多数方法专注于利用知识图谱中三元组结构的表示学习,而忽略了融入实体类型的信息。对于实体而言,对于不同的类型含义应该具有不同的表示。本文从Freebase中获取实体的类型信息,并将其层次化表示,并设计了两种编码方式,对于不同的关系通过参数调整获得对应的实体表示。
Knowledge Representation Learning with Entities, Attributes and Relations
- 作者:Yankai Lin, Zhiyuan Liu, Maosong Sun
- 机构:Tsinghua University
本文面向知识图谱的表示学习任务,提出利用实体、属性、关系三个元素来进行表示学习。
本文提出对属性和关系加以区分,并在表示学习的过程中区别对待,本文首先提出属性与关系的区别,本文叙述:属性的值一般是抽象的概念,如性别与职业等;而且通过统计发现,属性往往是多对一的,而且对于特定的属性,其取值大多来源于一个小集合,如性别。对关系与属性采用不同的约束方式进行独立表示学习,同时提出属性之间的更强的约束关系。本文想法新颖,很值得借鉴。


