
面试再也不怕问ThreadLocal了
要解决多线程并发问题,常见的手段无非就几种。加锁,如使用synchronized,ReentrantLock,加锁可以限制资源只能被一个线程访问;CAS机制,如AtomicInterger,AtomicBoolean等原子类,通过自旋的方式来尝试修改资源;还有本次我们要介绍的ThreadLocal类,通过为每个线程维护一个变量副本,每个线程都有自己的资源了,自然没有并发问题。ThreadLocal也是一个高频面试题,看下如下的问题,是否没想象中那么简单呢,看完这篇文章以后面试再问ThreadLocal就毫无鸭梨了。
- ThreadLocal 作用,原理
- 你在哪些场景使用过ThreadLocal,有什么注意事项
- ThreadLocalMap的key为什么设计为弱引用,value为什么不设置为弱引用
- 如何将父线程的ThreadLocal传递给子线程
- 如何将线程的ThreadLocal传递给线程池中的线程
- ThreadLocal设计上可以做哪些优化
ThreadLocal原理
ThreadLocal设计上为每个线程维护一份线程私有数据,它可以避免多线程之间共享资源竞争问题,同时可以在线程执行的不同阶段传递变量。
关于原理主要涉及到3个类,ThreadLocal,Thread,ThreadLocalMap。
ThreadLocal本身只是个“壳”,其操作的都是它的一个内部类ThreadLocalMap,一个类似HashMap的结构,但它不实现Map接口,ThreadLocalMap内部维护了一个Entry数组,存放实际的数据,Entry的key就是ThreadLocal对象本身,value是要存放的值,每次读写数据,就是通过TheradLocal对象计算hashcode,定位到数组的下标操作。Entry是一个继承了WeakReference<ThreadLocal<?>>的类,作为key的ThreadLocal对象会被设置为弱引用。
public class ThreadLocal<T> {
static class ThreadLocalMap {
private Entry[] table;
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
}
Thread线程类内部有一个threadLocals属性,就是该线程对应的ThreadLocalMap,这个字段是通过ThreadLocal维护,也就是操作入口都是在ThreadLocal。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
我们看下ThreadLocal.set方法源码
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
非常好理解,拿到当前线程,拿到当前线程的ThreadLocalMap,把当前ThreadLocal作为key,和value传递给ThreadMap保存。
用一张图来表示一下三者的关系,如下:
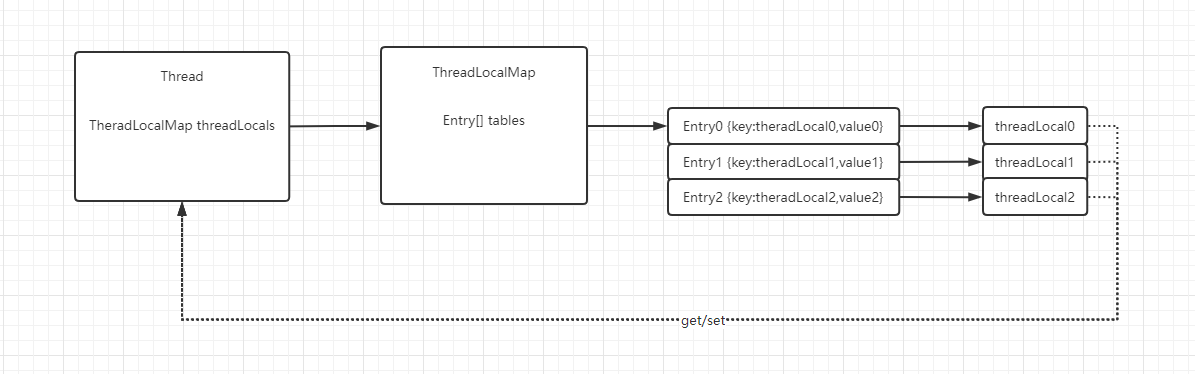
TheradLocal的应用
有时候面试官会问你在哪些场景使用过ThreadLocal,看你到底有没有真正使用过,记住我如下例子就行啦。(以下代码都是默写的伪代码~)
spring动态数据源
有些时候需要在一次方法内操作不同数据源,这个时候就涉及到多数据源的切换。我们会定义一个AbstractRoutingDataSource用来决定选哪个数据源
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceHolder.getDataSource();
}
}
选哪个数据源是通过从当前线程ThreadLocal获取
public class DynamicDataSourceHolder {
private static final ThreadLocal<String> threadLocal = new ThreadLocal<String>();
public static String getDataSource() {
return threadLocal.get();
}
public static void setDataSource(String dataSource) {
threadLocal.set(dataSource);
}
public static void clearDataSource() {
threadLocal.remove();
}
}
接着可以定义一个注解和切面,在方法执行前判断拿到这个注解标记的数据源,将值设置到ThreadLocal,并在DynamicDataSource决定使用哪个数据时获取到,实现数据源切换,伪代码如下:
public @interface DS {
String name();
}
@Component
public class DynamicDataSourceAspect {
@Pointcut("@annotation(com.my.DS)")
public void pointcut() {}
@Before("pointcut()")
public void doBefore(JoinPoint joinPoint) {
DynamicDataSourceHolder.set(dataSourceName);
}
@After("pointcut()")
public void after(JoinPoint point) {
DynamicDataSourceHolder.remove(dataSourceName);
}
}
关于动态数据有兴趣的可以看下mybatis plus的dynamic-datasource-spring-boot-starter,原理跟我们上面说的是一样的。
可靠消息的实现
我们知道数据库和mq要确保两者都成功,一种做法就是使用本地消息表,也就是数据落库的时候同时写一条待发送的消息,并且将消息id记录到ThreadLocal,在事务提交完成后,我们可以注册回调,从本地ThreadLocal拿到消息id,再发送出去。当然,实际还要考虑发送失败的情况,通过定时任务补偿。这就是本地消息表的一种实现思路,ThreadLocal存储了消息id,在事务提交后,再从ThreadLocal取出来发送消息。
首先说明,如下写法是不可取的,原因有:1.如果事务commit失败,mq还是发出去了 2.导致事务时间变长,事务内不宜处理其它耗时逻辑,如发送mq,调用接口等。
@Transactional
public void register() {
//插入数据
User user = new User();
userMapper.insert(user);
//发送消息,处理其它事情
mq.send(topic, user.getId());
}
改写如下:
@Transactional
public void register() {
//插入数据
User user = new User();
userMapper.insert(user);
UserMsg userMsg = new UserMsg();
userMsgMapper.insert(userMsg);
//不使用整个user对象,只存个id占用内存较少,user对象可以及时被回收
threadLocal.set(user.getId);
//注册回调
transCallbackService.afterCommit(() -> {
mqHandleService.handleUserRegister();
});
}
@Service
class TransCallbackService {
public void afterCommit(Runnable runnable) {
if (TransactionSynchronizationManager.isActualTransactionActive()) {
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
runnable.run();
}
});
}
}
}
@Service
class MqHandleService {
public void handleUserRegister() {
//从threadlocal获取id,再处理各种事情
mq.send(topic, threadLocal.get());
}
}
弱引用问题
java中对象引用有几种类型:强引用,弱引用,软引用和虚引用,它们的区别主要跟gc有关。
强引用:通常我们写的代码都是强引用,如:User user = new User(); user就是一个强引用,它指向了内存一块区域,只要user还是可达的,那么gc就不会回收对应的内存。如果user的作用域非常长,而且后面它又没有用到了,可以将它设置为null,这样gc可以快点回收对应的内存,当然现在jvm比较智能,可以自动分析完成这个事情。还有一个注意事项是,如果对象被如一个全局的HaspMap引用着,那么即使设置为null或者指向它的变量不可达了,它也不会被回收,如:
User user = new User();
HashMap map = new HashMap(); //被map引用着,map可达就不会被回收
map.put(user, 1);
user = null;
弱引用:如果一个对象只被弱引用对象引用着,那么它会在下一次gc被回收,弱引用使用WeakReference
User user = new User();
WeakReference weakReference = new WeakReference(user);
user = null;
HashMap hashMap = new HashMap();
hashMap.put(weakReference,1);
System.gc();
当执行完user=null后,其对象内存区域就没有强引用指向它了,只有一个弱引用对象weakReference。接着执行gc,user原本指向的内存就会被回收。此时我们执行weakReference.get()将拿到一个null。 从这里可以看到如果使用弱引用,假设我们忘记从HashMap移除不需要的元素,它也会再下一次gc时被回收,防止内存泄漏。
软引用:在内存充足的条件下,不会被回收,只要在内存不足时才会被回收。
虚引用:随时可能被同时,主要用于跟踪gc,在对象被gc后会收到一个通知。
对于ThreadLocal来说,它里面的Entry继承了WeakReference
上面的例子我们刚提到,当你忘记remove的时候,使用弱引用可以防止内存泄漏,ThreadLocal也是出于这目的。假设key不是弱引用,开发者忘记remove,那么key就发生内存泄漏,只能等到Thread对象销毁时才回收,在一些使用线程池的场景下,Thread会一直复用,就会导致内存一直回收不了。
public void test() {
inner();
System.gc();
//Thread.currentThread.threadLocals
}
private void inner() {
TestClass testClass = new TestClass();
testClass.set(new User());
}
class TestClass {
ThreadLocal threadLocal = new ThreadLocal();
public void set(Object value) {
threadLocal.set(value);
}
}
//更简单的例子
public void test() {
ThreadLocal threadLocal = new ThreadLocal();
threadLocal.set(new User());
threadLocal = null;
System.gc();
//Thread.currentThread.threadLocals
}
如上代码,往ThreadLocal放了一个User对象,此时ThreadLocalMap就维护一个key为threadLocal,value为User的Entry,当inner方法执行完,threadLocal已经不可达,但它的内存区域还被Entry引用着,并且没法再访问到,如果是强引用,就出现内存泄漏。如果是弱引用,在gc后,我们观察Thread.currentThread.threadLocals就可以发现,它的referent变成了null,被回收了。但作为value的User对象是强引用,不会被回收。到这里有些面试官就会问,为什么value不也设置为弱引用呢?
如下代码:
public void test() {
TestClass testClass = inner();
System.gc();
User user = testClass.get();
}
private void inner() {
User user = new User();
TestClass testClass = new TestClass();
testClass.set(user);
return testClass;
}
class TestClass {
ThreadLocal threadLocal = new ThreadLocal();
public void set(User user) {
threadLocal.set(user);
}
public User get() {
reteurn threadLocal.get();
}
}
这里我们返回了TestClass,threadLocal对象就还被引用着,我们假设value如果是弱引用,那value在inner方法后就没有强引用了,gc后会被回收,会后再获取会拿到一个null,这显然是不合理的。
说到底,key设置为弱引用是为了防止内存泄漏,value不能设置为弱引用是因为如果key还被强引用着,value若是弱引用会被gc回收,下次就拿不到了。
从另一个方面说,开发人员处理的是value,key是java自己帮我们生成的,所以它要负责任,确保不会出现内存泄漏问题,而value是开发自己设置的,不需要时要手动remove,不然出现问题就是开发的锅啦。如果我忘记remove value,value泄漏是我的问题,但不能因此还多了一个key的泄漏,这个开发就不认了,为了避免这种纠缠不清问题,所以java作者将key设置为弱引用。
父线程/线程池传递ThreadLocal
如果在线程内,创建一个子线程,子线程还能访问到父线程的ThreadLocal吗?答案是不能的,但是从父子继承的角度来说,有时候需要能,所以Thread内部还有一个inheritableThreadLocals,它也是一个ThreadLocalMap。对应的也有一个InheritableThreadLocal,它继承了ThreadLocal。
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在new Therad()创建子线程的时候有如下逻辑
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
this是子线程,parent是父线程,也是当前线程,这里会判断父线程是否有inheritableThreadLocals,有就传递给子线程。
所以在父子线程场景下,传递ThreadLocal可以使用InheritableThreadLocal。
使用InheritableThreadLocal只能在第一次创建时把数据传递过去,后面主线程再改子线程也不会变化。对于使用线程池的情况,线程是复用的,如果希望子线程每次执行都能获取到主线程的ThreadLocal值,InheritableThreadLocal也无能为力了。例如日志跟踪traceid,每次执行主线程都会生成一个traceid,线程值每次执行,也都应该拿到最新的traceid,这样才能链路才能一致。
实现思路是自定义一个TtlRunnable继承Runnable,在执行run方法前,拷贝一下当前线程的值,在runnable.run执行前,将父线程的值拷贝到当前线程,这样每次执行都会做一次拷贝。
public class TtlRunnable implements Runnable {
private Runnable runnable;
private HashMap<ThreadLocal, Object> ttlThreadLocals;
public TtlRunnable(Runnable runnable) {
this.runnable = runnable;
//将当前线程的ThreadLocal拷贝一份
ttlThreadLocals = copyCurrentThreadLocals();
}
@Override
public void run() {
//将父线程ThreadLocal拷贝到当前子线程
copyParentThreadLocal2Current(ttlThreadLocals);
runnable.run();
}
}
上面只是简单的实现思路,像spring cloud sleuth在处理traceid时思想也是类似的,当然实际还有很多东西要考虑,不过我们不用自己实现,阿里有一个TransmmittableThreadLocal可以直接使用,参见:transmittable-thread-local。
ThreadLocal可以做哪些优化
能问到这里证明离offer已经不远了,基本很多面试官也不会问到这个层面。
回到ThreadLocal原理部分,它实际操作的是ThreadLocalMap,通过当前ThreadLocal的hashcode,计算Entry数组的下标,这个hashcode是new ThreadLocal()时通过一个全局的AtomicInteger累加0x61c88647得到。
跟hashmap的原理类似,通过hashcode计算下标,可能会出现hash冲突,hashmap使用链表+红黑树的方式解决hash冲突。而ThreadLocal使用线性探测法解决。
线性探测法的做法是,当出现hash冲突时,探测下一个位置,看看是否可以放入,可以就放入,否则继续往下一个位置探测。问题就出现在这里,当出现较多hash冲突时,相当于链表的遍历不断的探测,效率较低,可能ThreadLocal的作者认为ThreadLocal的设计上它不会存放太多数据吧。
那怎么优化呢?既然出现hash冲突影响效率,那干脆就不处理了,使用一个递增为1的AtomicInteger,每个ThreadLocal对应一个下标,这样就不会有冲突了,O(1)的查询速度,但是会占用较多空间,是一种空间换时间的思想。
实际这种做法就是netty中FastThreadLocal的实现,netty中提供了FastThreadLocal,FastThreadLocalMap,InternalThreadLocalMap,它们需要搭配使用,否则会退化为jdk的ThreadLocal。
每个FastThreadLocal都有一个递增唯一的index,放入InternalThreadLocalMap时不会有冲突,查询效率也高。通过index直接定位到下标,不需要hash,在扩容的时候直接搬到新数组对应下标,也不需要rehash,扩容速度快。同时由于不会出现冲突,所以不需要保持ThreadLocal的引用,也就没有上面弱引用和内存泄漏的问题。
通过netty的FastThreadLocal来回答这个问题,有理有据,有兴趣的可以去研究一下它的源码。
更多分享,欢迎关注我的github:https://github.com/jmilktea/jtea

 浙公网安备 33010602011771号
浙公网安备 33010602011771号