
特征工程
通过结合方差阈值、特征相关性分析、单因素统计测试、递归特征消除和特征重要性等特征选择方案,在减少特征数量的同时,最大限度地保留对目标变量的关键信息,从而提升模型的效率、可解释性,并防止过度拟合的发生。
一、特征相关性分析
计算各个特征之间的相关性(可用皮尔逊相关系数)。如果有相关系数较高的两个特征,可以只选择其中一个特征,保留重要性更高或与目标变量更相关的那个。这有助于减少模型的复杂性,并提高模型的解释性。
如: 特征相关性分析(热图) 参考:https://blog.csdn.net/amyniez/article/details/127786482
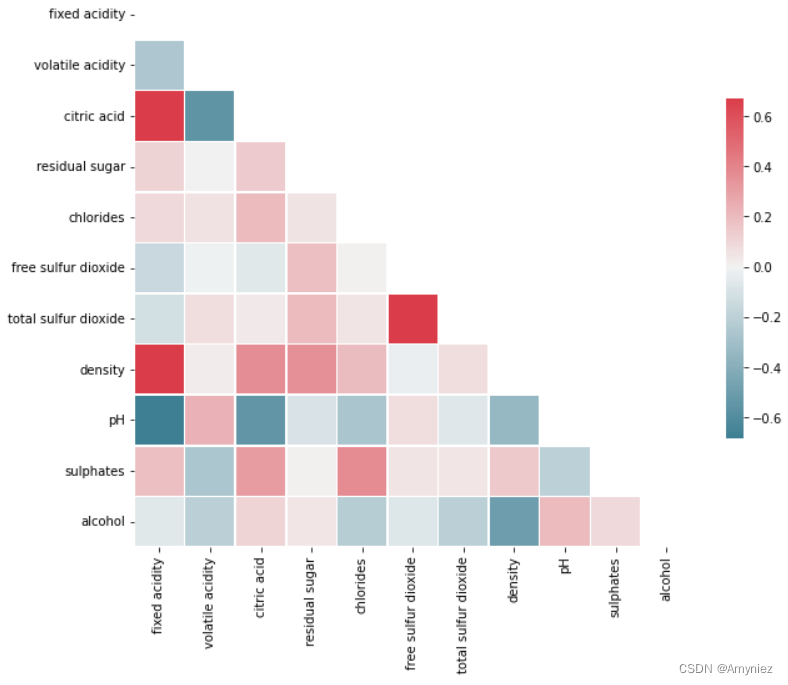
表明特征之间没有高度关联(即没有多重共线性的风险)
正相关特征:"总二氧化硫 "与 “游离二氧化硫”、"固定酸度 "与 "柠檬酸 "、"固定酸度 "与 “密度”;
负相关特征:"pH值 "与 “固定酸度”、"pH值 "与 "柠檬酸 "、"柠檬酸 "与 “挥发性酸度”;
这些相关性可能是由于这些特征之间的物理关系造成的。
二、特征重要性评估
随机森林的特征重要性评估通常使用的是随机森林本身提供的特征重要性方法。Boruta算法是一种用于特征选择的算法,与随机森林的特征重要性评估是相关的,但并不相同。
在随机森林中,特征的重要性是通过在训练过程中测量每个特征对模型准确性的贡献来计算的。随机森林的思想在于,如果某个特征对于构建决策树模型的过程中起到了关键作用,那么它的重要性就会相对较高。
一般来说,随机森林中的特征重要性是通过以下两种方式之一计算的:
-
基尼重要性(Gini Importance): 基于Gini指数的减小程度,即每个特征在决策树节点中的分裂中对不纯度减小的贡献。
-
平均减少不纯度(Mean Decrease in Impurity): 通过在每个决策树节点上测量特征对不纯度减少的平均贡献。
相比之下,Boruta算法是一种用于特征选择的方法,它基于随机森林的特征重要性来判断哪些特征是显著的,哪些是次要的。Boruta算法通过在原始特征集和随机生成的阴影特征之间进行比较,确定真实特征的重要性。
总的来说,虽然Boruta算法可以与随机森林一起使用,但随机森林自身提供的特征重要性评估通常足以进行特征选择。 Burota算法主要用于确定哪些特征是显著的,以辅助特征选择的过程。
1、Boruta算法的基本步骤
本文来自博客园,作者:计算之道,转载请注明原文链接:https://www.cnblogs.com/jszd/p/17943255

 浙公网安备 33010602011771号
浙公网安备 33010602011771号