kaggle竞赛_mnist_10%
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg import seaborn as sns #专门用于数据可视化的 %matplotlib inline np.random.seed(2) from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix import itertools from keras.utils.np_utils import to_categorical # convert to one-hot-encoding from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D from keras.optimizers import RMSprop from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ReduceLROnPlateau
sns设定格式¶
sns.set(style='white', context='notebook', palette='deep')
读取数据,两个kaggle上下载的csv已经提前放置在了固定的地方¶
train = pd.read_csv("./input/train.csv")
test = pd.read_csv("./input/test.csv")
数据的显示和预处理¶
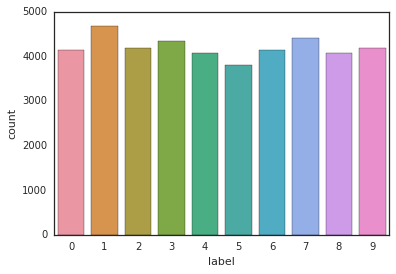
Y_train = train["label"] #获得label X_train = train.drop(labels = ["label"],axis = 1) #获得label以外的东西,也即是数据 del train #没用了 g = sns.countplot(Y_train)
空数据检查¶
X_train.isnull().any().describe() #isnull是所有空数据,any是进行与运算,describe其实是用来查看第一个数据是什么的
Out[42]:
test.isnull().any().describe() #通过这里的检查,可以发现所有数据的isnull都为false,也就是所有的地方都是有数据的
Out[43]:
将mnist图片转换为浮点类型¶
X_train = X_train / 255.0 test = test / 255.0
将mnist图片转化为图片的大小¶
X_train = X_train.values.reshape(-1,28,28,1) #这里就是按照28*28的图片大小进行压缩 test = test.values.reshape(-1,28,28,1) #这个地方的这种写法,能够成功地将图片转化成28*28 * N的格式
准备训练数据¶
Y_train = to_categorical(Y_train, num_classes = 10) #onhot
即使是有test了,也要进行train的数据分割¶
random_seed = 2 X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1, random_state=random_seed)
打印结果,查看是否正确¶
g = plt.imshow(X_train[1][:,:,0])

开始导入cnn¶
model = Sequential() #序贯,关于模型的选择我还没有什么想法,我不知道从模型方面考虑怎样才能从0.9961继续往上增长 model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu', input_shape = (28,28,1))) model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu')) model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu')) model.add(MaxPool2D(pool_size=(2,2), strides=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(256, activation = "relu")) model.add(Dropout(0.5)) model.add(Dense(10, activation = "softmax"))
训练准备¶
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) model.compile(optimizer = optimizer , loss = "categorical_crossentropy", metrics=["accuracy"])
学习率自动降低¶
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001) In [52]: epochs = 28 # 训练次数 batch_size = 256
数据增量方法¶
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
In [54]:
#开始训练
history = model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data = (X_val,Y_val),
verbose = 2, steps_per_epoch=X_train.shape[0] // batch_size
, callbacks=[learning_rate_reduction])
绘制曲线¶
fig, ax = plt.subplots(2,1) ax[0].plot(history.history['loss'], color='b', label="Training loss") ax[0].plot(history.history['val_loss'], color='r', label="validation loss",axes =ax[0]) legend = ax[0].legend(loc='best', shadow=True) ax[1].plot(history.history['acc'], color='b', label="Training accuracy") ax[1].plot(history.history['val_acc'], color='r',label="Validation accuracy") legend = ax[1].legend(loc='best', shadow=True)
得出结果¶
results = model.predict(test)
results = np.argmax(results,axis = 1)
results = pd.Series(results,name="Label")
submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("mnist_kaggle_jsxyhelu.csv",index=False)
最后要把 mnist_kaggle_jsxyhelu.csv上传上去


 浙公网安备 33010602011771号
浙公网安备 33010602011771号