检查点和实例恢复
检查点和实例恢复
1 什么是checkpoint(检查点)
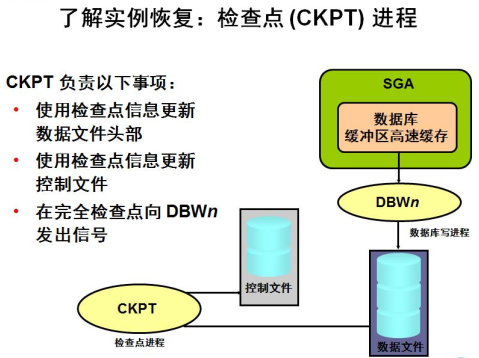
“检查点”是一种数据结构,用于定义数据库的重做日志中的系统更改号 (SCN)。检查点被记录在控制文件和每个数据文件头中
每隔三秒,CKPT进程就会在控制文件中存储一次数据,以记录DBWn已将哪些脏块从SGA写到磁盘。每次刷新截止的那个块的位置就叫检查点位置checkpoint position。如果发生日志切换,则CKPT进程还会将此检查点信息写入数据文件的头部。文件头中记录的SCN可保证将该SCN之前对数据库块进行的所有更改写入到磁盘中
2 检查点作用
- 保证数据库的一致性。一致性关闭数据库时,确保所有commit的数据写到磁盘上
- 确保内存中脏块定期写入磁盘
- 缩短实例恢复的时间。实例恢复时,要把实例异常关闭前没有写到硬盘的脏数据通过日志进行恢复。只需要处理上一个检查点之后的联机重做日志文件条目,从而减少实例恢复的时间
3 检查点分类
在Oracle 8i之前,数据库的发生的检查点都是完全检查点。完全检查点会将数据缓冲区里面所有的脏数据块写入相应的数据文件中,并且同步数据文件头和控制文件,保证数据库的一致。但是由于完全检查点会将所有的脏数据库块写入,巨大的IO往往会影响到数据库的性能。 因此Oracle从8i开始引入了增量检查点的概念
3.1 数据库检查点(database checkpoint)
刷新所有脏块
DBA 手工执行检查点的命令
alter system checkpoint;
一致性关闭数据库实例
shutdown immediate; --最常用
shutdown transactional;
shutdown normal;
联机日志文件切换
数据库设置为热备份模式
alter database begin backup
3.2 表空间和数据文件检查点(局部检查点)
对于仅限于局部影响的操作,可以触发局部检查点。
表空间offline
数据文件offline
删除extent
表空间begin backup(将表空间置于热备份模式)等
3.3 增量检查点incremental checkpoint
增量检查点的主要宗旨就是dbwr定期的刷新一部分脏块到磁盘,避免日志切换时dbwn一次写大量的脏块
database buffer cache中被修改过的块称为脏块。脏块按照首次变脏的时间顺序被一个双向链表指针串联起来,这称做检查点队列
当增量检查点发生时,DBWR就会被触发,沿着检查点队列的顺序将部分脏块刷新到磁盘上,每次刷新截止的那个块的位置就叫检查点位置checkpoint position,检查点位置之前的块,都是已经刷新到磁盘上的块。而检查点位置对应的日志地址(RBA redo block address)又总是被记录在控制文件中。如果发生系统崩溃,这个最后的检查点位置就是实例恢复运用日志的起点
增量检查点使检查点位置前移。进而缩短实例恢复需要的日志起点和终点之间的距离
4 实例恢复机制
4.1 什么是实例恢复
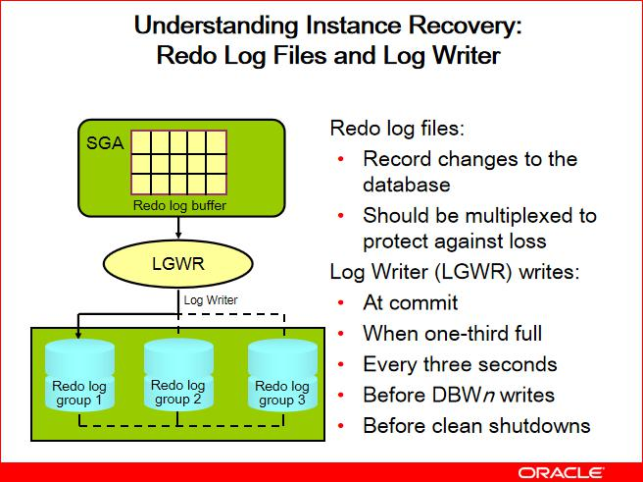
背景:实例崩溃时,内存数据丢失,磁盘上的datafile和当时内存db buffer内容不一致
那么要解决两个问题:
① 重新构成崩溃时内存中还没有保存到磁盘的已commit的变更块
② 回滚掉已被写至数据文件的uncommit的变更块

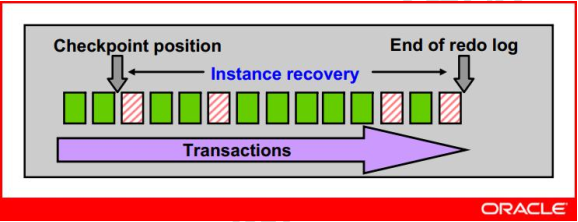
每当增量检查点触发时,一部分dirty buffer被刷新到磁盘,并记录了最后一次检查点位置。当实例恢复时,Oracle首先从控制文件里找到最后一次检查点位置,这个位置其实就是实例恢复时运用日志的起点(RBA),然后是smon监控下的一系列动作
4.2 实例恢复的阶段
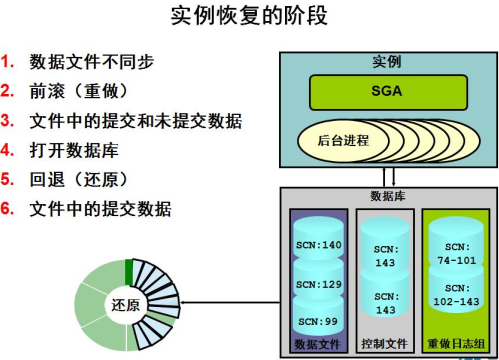
要使实例打开一个数据文件,数据文件头中包含的系统更改编号(SCN)必须与控制文件中存储的当前SCN匹配。如果编号不匹配,实例会应用联机重做日志中的重做数据,并按顺序“重做”事务处理,直到数据文件处于最新状态。所有数据文件都与控制文件同步后,就会打开数据库,此时用户可以进行登录
应用重做日志后,会应用所有事务处理,使数据库返回到出现错误时的状态。这通常包括正在进行但尚未提交的事务处理。打开数据库之后,会回退那些未提交的事务处理。在实例恢复的回退阶段结束时,数据文件只包含提交的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号