创建和管理表-DDL语句
建和管理表-DDL语句
1 数据库对象
表:列组成表的结构, 行组成表的数据
视图:存储在数据字典中的一条 select 语句
序列:一种生成唯一数字的结构: 有序的发出数字
索引:可以减少对表中行的访问次数、 提高查询性能
同义词:别名
能够访问数据的对象
【掌握】 创建、 修改、 删除
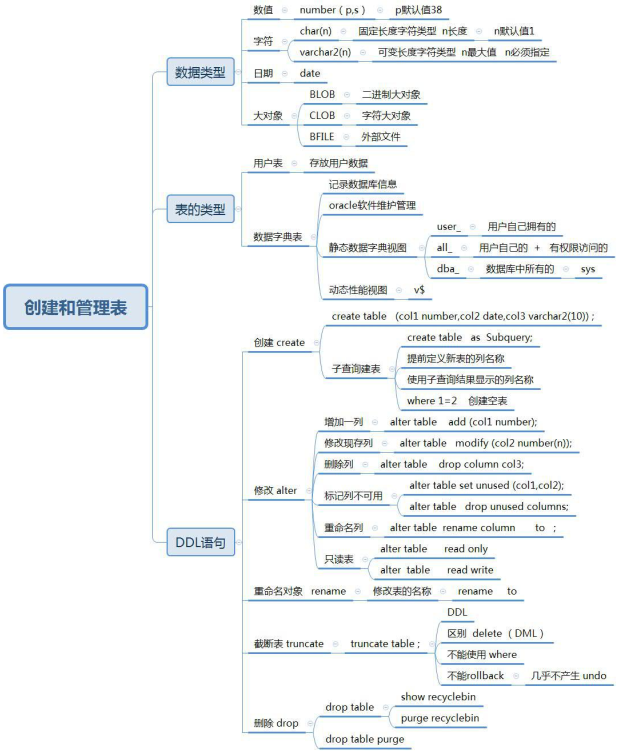
2 create table基本语法
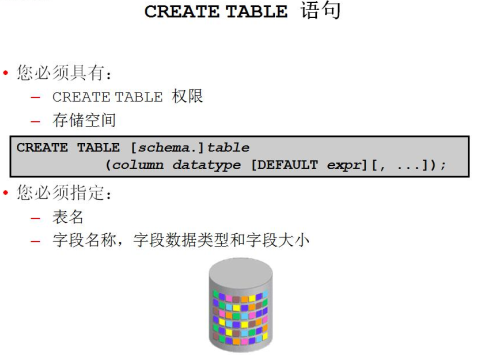
用户要建表,需要有create table权限,有存储空间,一张表中最多有1000 个列
[GLOBAL TEMPORARY]
临时表级别:
事务级:事务结束,数据消失
会话级:会话断开,数据消失
[schema.] 方案名
存储空间:在表空间有使用权限
逻辑存储结构:表空间、段、区、块
物理存储结构:数据文件
3 创建表:create table

create table dept01(deptno number(2),dname varchar2(14),loc varchar2(13));

3.1 default默认值
default选项:
- 在插入的过程中,为列指定一个默认值
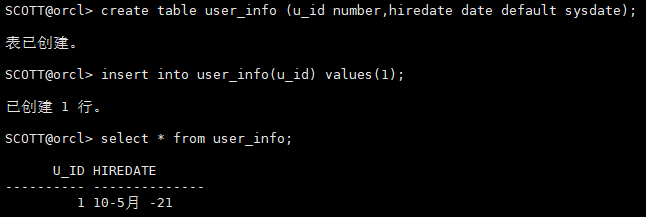
... hire_date date default sysdate, ...
- 字符串,算数表达式,或sql函数都是合法的
- 默认值必须满足列的数据类型定义
create table user(uid number,hiredate date default sysdate);
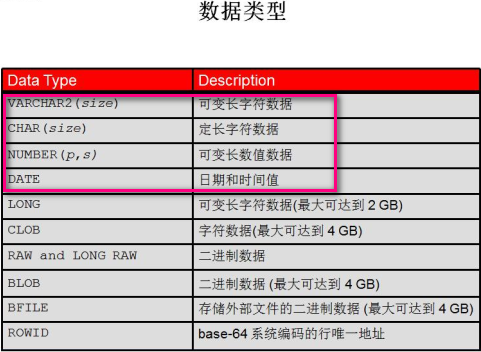
4 数据类型
常见数据类型:字符、数字、日期、大对象

4.1 字符
char(n) 固定长度字符数据,读取效率快,存储时使用空格填满空白内容。n 默认值 1,范围 1~2000字节
varchar2(n)可变长度字符数据,节省存储空间。n必须指定,范围 1~4000 字节
性别char(2),一个汉字占两个字节
姓名varchar2()
4.2 数字
number(p,s)数值数据,包括零、负数、正数
p是precision精度,总有效数据位数,最大值是 38,默认是 38
s是scale刻度,小数点后位数
s=0整数
s>0小数点后保留s位,小数点左边最多p-s位
s<0小数点前第|s|位四舍五入,用0取代小数点前|s|位。最多p-s位(p+|s|)
4.3 日期
date日期和时间值。包括世纪、年、月、日、小时、分、秒
必须指定年、月、日
timestamp(n):时间戳,表示日期和时间,比date更精准。n表示秒向下划分的精度范围,n取值0~9,默认6
4.4 大对象
BLOB,Binary Large Object(二进制大对象),例如图片、视频、音频
CLOB,Character Large Object(字符型大对象),例如文本、BFILE、定位器,指向保存在数据库服务器的操作系统上的文件文件大小限制为4GB
子查询创建表的时候,long类型不会被拷贝
long类型不能出现在group by和order by子句
一个表只能有一个long类型字段
long类型字段不能有约束
5 oracle数据库中的表

6 查询数据字典
6.1 描述用户拥有的表
select * from user_tables;
6.2 查看用户所有的数据类型
select OBJECT_TYPE from user_objects;
6.3 查看用户拥有的表、视图、同义词、序列
select * from user_catalog;
6.4 eg:
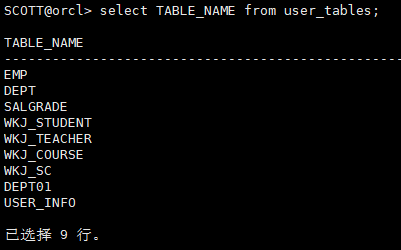
user_tables 查询属于用户自己的表
select TABLE_NAME from user_tables;
user_objects : 对象的名字、 ID、 类型
select OBJECT_NAME,OBJECT_ID,OBJECT_TYPE from user_objects;
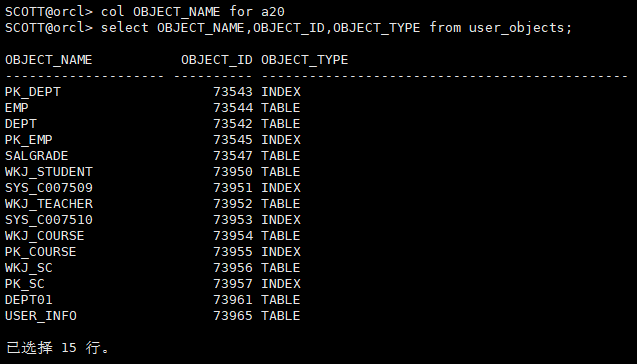
查看用户拥有的表、 视图、 同义词、 序列
select * from user_catalog;

6.5 总结
数据字典表在创建数据库时生成,只有oracle能够读写
oracle提供了一组视图来查询数据字典,大致有4中类型的数据字典视图:
USER_:用户所有的对象的信息;
ALL_:用户拥有的和有权限操作的对象的信息;
DBA_:只有具有DBA角色的用户可以访问,里面包含数据库所有对象的信息;
V$_:动态性能视图(数据来自内存)、数据库服务器的性能和锁的相关信息
哪个视图显示数据库中所有的表?
是 DBA_TABLES 不是 ALL_TABLES
7 使用子查询来创建一个表
- 使用create table语句和as [select子句]选项,将创建表和插入数据结合起来完成
语法:create table table_name[(col1 col_type, ...)] as [select子句];
- 指定的列和子查询中的列要一一对应
- 通过列名和默认值定义列
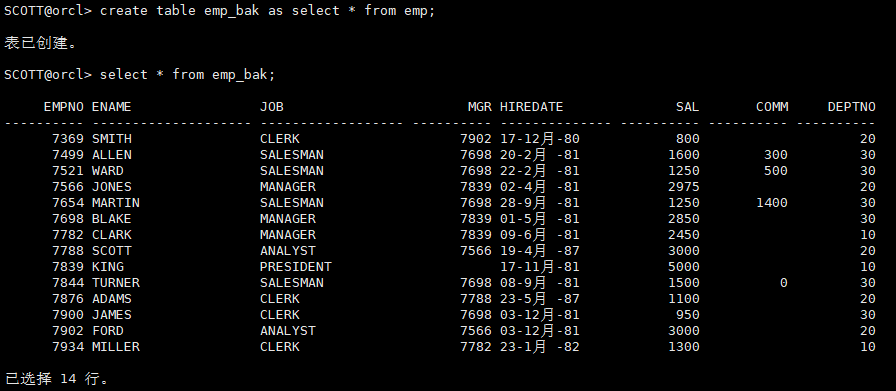
create table emp_bak as select * from emp;
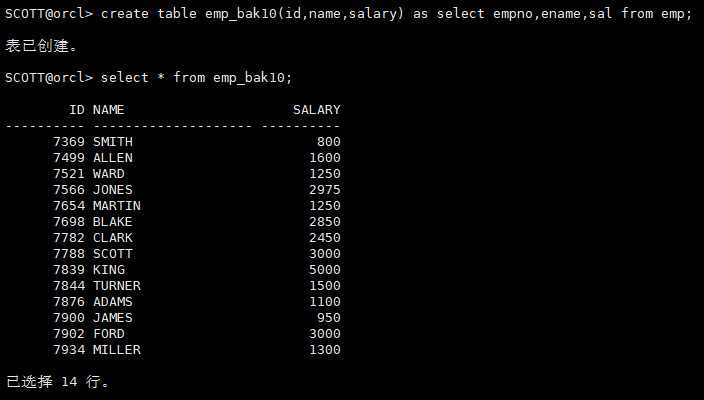
create table emp_bak10(id,name,salary) as select empno,ename,sal from emp;
1.创建出来的表结构可以与原表不同
2.列上的not null(非空)约束也将应用于新表,但primary key(主键)、unique(唯一)、foreigne key(外键)约束以及隐式的not null(主键列)约束都不会被继承
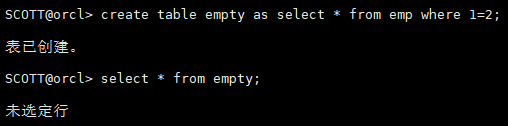
7.1 创建一个空表
只创建表结构
create table empty as select * from emp where 1=2;
8 修改表:alter table命令
使用ALTER TABLE语句可以:
- 添加一个新列
- 修改现有的列定义
- 新的列定义默认值
- 删除一列
- 重命名列
- 将表更改为只读状态
增加新列:
语法:alter table table_name add (col1 col_type,col2 col_type, ...)
修改现有的列:
语法:alter table table_name modify (col1 col_type,col2 col_type, ...)

8.1 add增加一列
alter table emp_bak10 add (job varchar2(20));

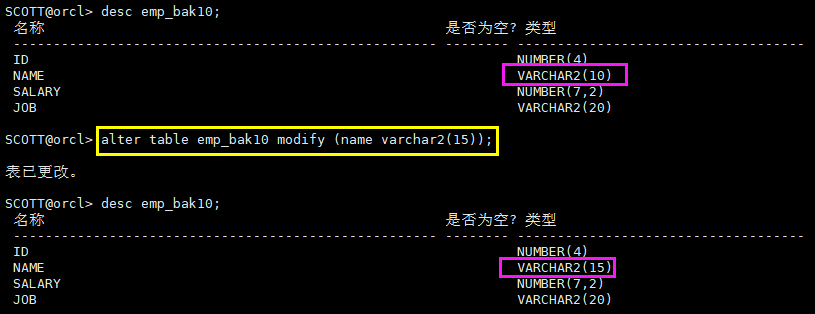
8.2 modify修改现有列
alter table emp_bak10 modify (name varchar2(15));
8.3 drop column删除一个列
使用drop column来删除表中不使用的列
语法:alter table table_name drop column col1;
alter table emp_bak10 drop column job;

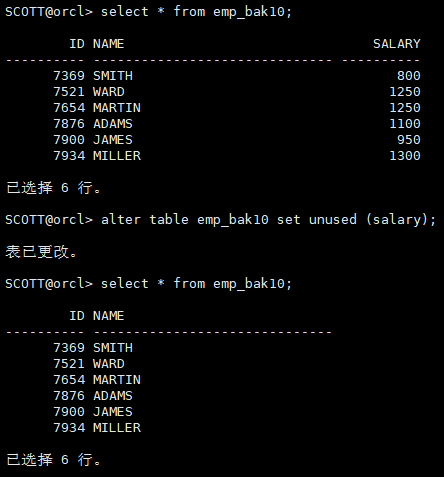
8.4 set unused标记列不可用
当表中数据量非常大时,在业务高峰时间直接执行 alter table drop column,会报ORA-01562错误。Oracle推荐使用SET UNUSED选项标记一列(或多列),使该列不可用(set unused不会真地删除字段),SET UNUSED COLUMNS用于drop多列时效率更高,SET UNUSED COLUMNS方法系统开销比较小,速度较快,但效果等同于直接drop column,就是说这两种方法都不可逆,无法再还原该字段及其内容
语法:alter table table_name set unused (col1,col2,...);
alter table emp_bak10 set unused (salary);
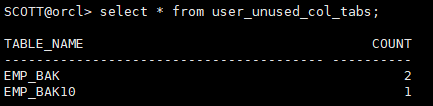
查看数据库用户下所有被set unused的列数
select * from user_unused_col_tabs;
删除不用的columns:
alter table emp_bak10 drop unused columns;
alter table emp_bak drop unused columns;

注意:
1.如果set unused某列,该列上有索引,约束,并定义了视图,引用过序列:索引和约束自动删除,序列无关,视图保留定义
2.无法删除属于SYS的任意表中的列,会报ORA-12988错误,哪怕是sys用户都不可以
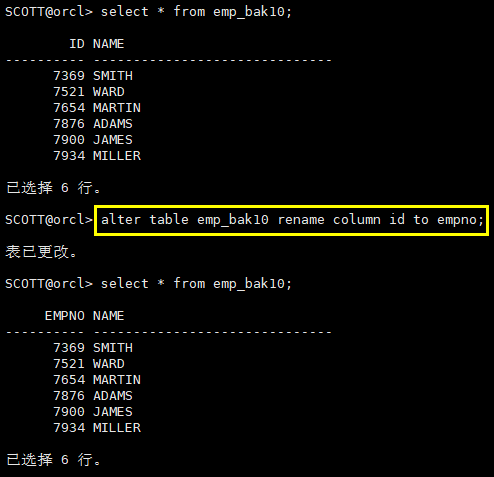
8.5 rename column重命名列
语法:alter table table_name rename column col1 to col2;
alter table emp_bak10 rename column id to empno;
8.6 read only设置表只读\读写
语法:alter table table_name read only;
alter table table_name read write;
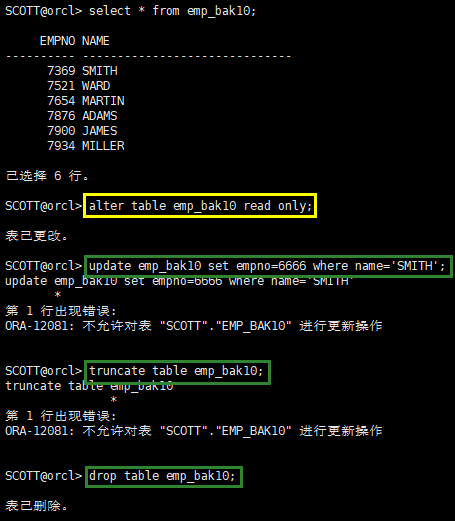
alter table emp_bak10 read only;
update emp_bak10 set empno=6666 where name='SMITH';
truncate table emp_bak10;
drop table emp_bak10;
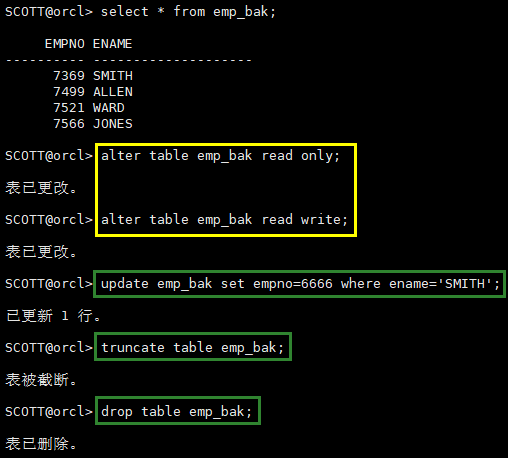
alter table emp_bak read only;
alter table emp_bak read write;
update emp_bak set empno=6666 where ename='SMITH';
truncate table emp_bak;
drop table emp_bak;
【知识点】
只读表可以drop,因为只需要在数据字典做标记
但是只读表不能做DML,也不能truncate,因为它们都在对只读表做写操作
9 修改对象(表、视图、同义词、序列)的名称
修改表、视图、同义词、序列的名称都可使用rename命令
语法:rename table_name1 to table_name2;
rename dept1 to department;

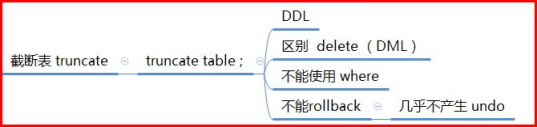
10 truncate截断表
语法:truncate table table_name;
truncate语句:
- 从表中删除所有的行, 保留了口弄表和完成的表结构
- 数据定义语言DDL,不是DML语言,不能使用撤销
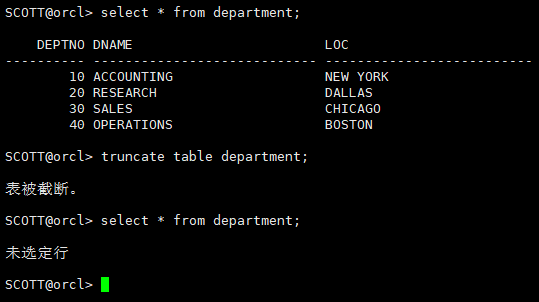
select * from department;
truncate table department;
select * from department;
11 为表增加注释
语法:comment on table table_name is 'Description Information';
- 可以使用comment语句为一个表或者表中的某一列增加注释
- 注释可以通过数据字典视图进行查询
- ALL_COL_COMMENTS
- USER_COL_COMMENTS
- ALL_TAB_COMMENTS
- USER_TAB_COMMENTS
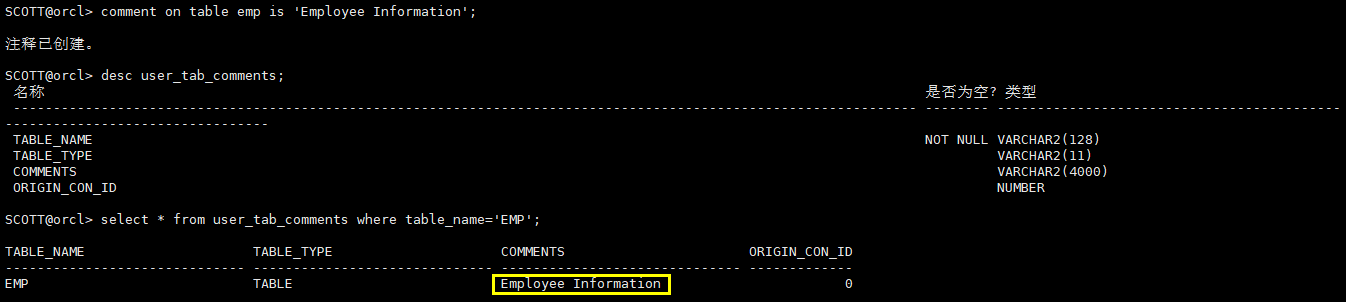
给emp表添加注释:Employee Information
comment on table emp is 'Employee Information';
desc user_tab_comments;
select * from user_tab_comments where table_name='EMP';
给emp表的deptno列添加注释:Department Number
comment on column emp.deptno is 'Department Number';
desc user_col_comments;
select * from user_col_comments where table_name='EMP';

12 删除表:drop table
- 表中所有的数据和结构都被删除
- 所有未决的事务都被提交
- 此表上所有的索引全部被删除
- 操作是不能回滚的
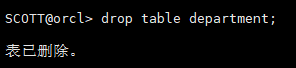
语法:drop table table_name;
drop table department;
13 总结
常用数据类型:varchar2,number,date
创建表:create table
修改表:alter table (add,modify,drop column,rename column,read only/read write)
删除表:drop table
截断表:truncate table
14 补充扩展:truncate和delete对比
- delete是DML语句,会产生很多undo数据,用于回滚(rollback),速度慢
- delete不会降低高水位线,delete 可以删除表中部分数据
- truncate是 DDL语句,几乎不产生 undo 数据,不能回滚、速度快
- truncate会降低高水位线,truncate会删除表中所有数据
| delete | truncate | |
| 速度 | 慢 | 块 |
| 语句类型 | DML | DDL |
| 能否回滚 | 能 | 不能 |
| 是否生成undo数据 | 大量 | 几乎不 |
| 能否降低高水位线 | 不降低 | 降低 |
| 能否加条件 | 可以 | 不能 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号