并发编程 - 进程
并发编程
多道技术(基于单核背景下产生)
单道:指的是一条道路走到黑 --> 串行
串行:a,b需要使用cpu,a先试用,b等待a使用完成后,b才能使用cpu
多道:一条道路分配走 --> 并发
并发:a,b需要使用cpu,a先使用,b等待a,直到a进入“IO或执行时间过长”,a会(切换+保存状态),然后b可以使用cpu,待b执行遇到“IO或执行时间过长”,再将cpu执行权限交给a,直到两个程序结束
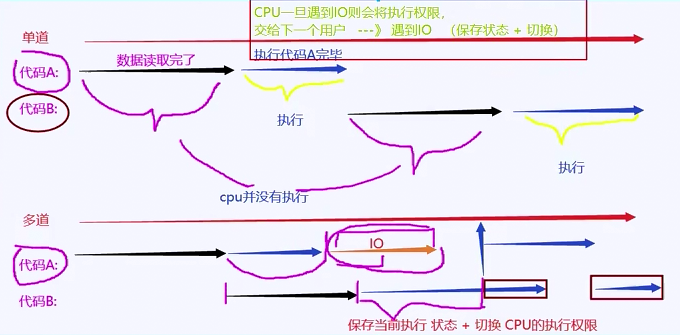
特点:
空间上的复用:(*******)
多个程序使用一个cpu
时间上的复用:(*******)
1.当执行程序遇到IO时,操作系统会将cpu的执行权限剥夺
优点:
cpu的执行效率提高
2.当执行程序遇到执行时间过长时,操作系统会将cpu的执行权限剥夺
缺点:
程序的执行效率低
并发编程 - 进程
1、进程
(1)什么是进程
进程是一个资源单位
(2)进程与程序
程序:一堆可执行的代码文件
进程:执行代码的过程,称之为进程
(3)进程调度(了解)
① 先来先服务调度算法
比如程序 a,b,若a先来,则先让a先服务,待a服务完毕后,b再服务
缺点:
执行效率低
② 短作业优先调度
执行时间越短,则先调度
缺点:
导致执行时间长的程序,需要等待所有时间短的程序执行完毕后,才能执行
现代操作系统的进程调度算法: 时间片轮转法 + 多级反馈队列(知道)
③ 时间片轮转法
比如同时有10个程序需要执行,操作系统会给你10秒,然后时间片轮转法会将10秒分成10等份。
④ 多级反馈队列
1级别队列:优先级最高,先执行此队列中的程序
2级别队列:优先级以此类推
3级别队列:...
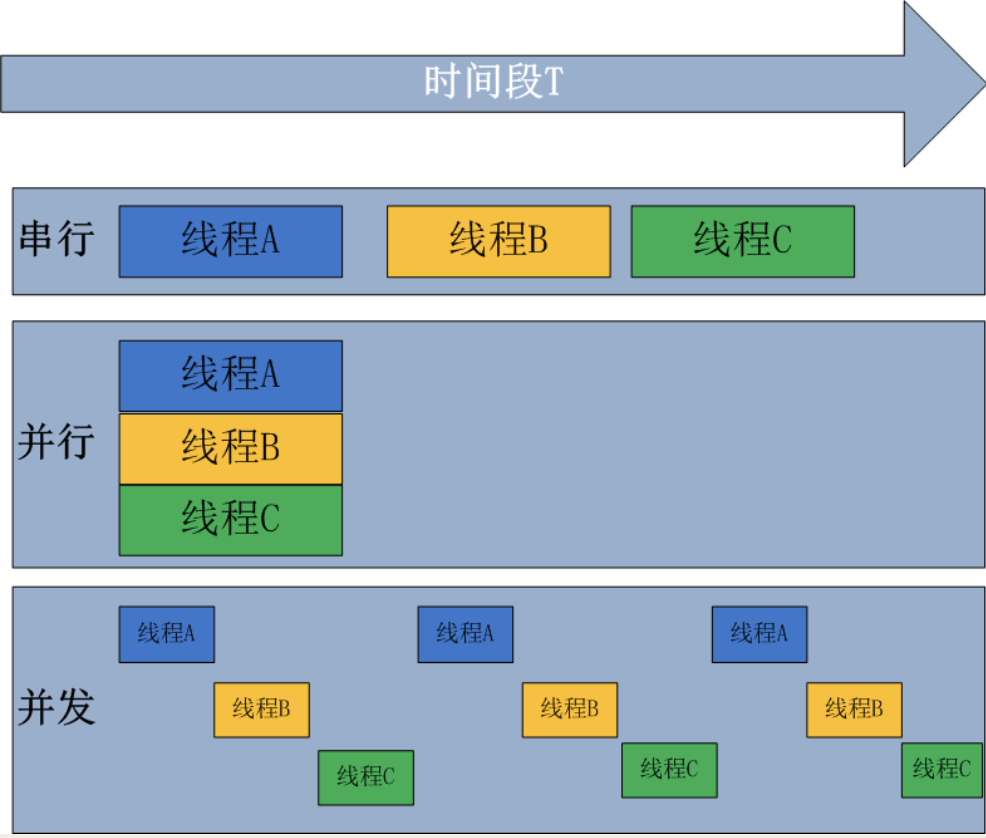
2、串行、并发与并行
串行:类似于单道,相当于同步提交任务
并发:在单核(1个cpu)情况下,当执行a,b两个程序时,a先执行,当a遇到IO时,b开始争抢cpu的执行权限,再让b执行。类似于多道,相当于异步提交任务。(看起来像同时运行)
并行:在多核(多个cpu)情况下,多个任务同时执行。(他们是真正意义上的同时运行)
3、同步与异步
同步与异步指的是 "提交任务的方式"
同步(串行):
两个a,b程序都要提交并执行,假如a先提交执行,b必须等a执行完成后,b才能提交任务并执行
异步(并发):
两个a,b程序都要提交并执行,假如a先提交执行,b无需等a执行完成,就可以直接提交任务并执行
4、阻塞与非阻塞
阻塞:
凡是遇到IO操作都会阻塞,进入阻塞态
IO操作:
input()
output()
time.sleep()
文件的读写
数据的传输
非阻塞(不等待):
只要不遇到IO阻塞,其他都是非阻塞(比如计算从1到100万的和)
IO密集型:很多IO操作
计算密集型:很多计算操作
5、进程的三种状态
就绪态:
所有任务提交完成后,都会进入就绪态。 (同步和异步)
运行态:
通过进程调用一个任务开始执行,该任务会进入运行态。 (非阻塞)
程序运行时间过长,会将程序返回给就绪态,等待下次调度
阻塞态:
凡是遇到IO操作的任务都会进入阻塞太,待IO操作结束,则阻塞态结束,进入就绪态,等待下次调度
6、进程的两种创建方式(代码)
方式1:直接调用Process类
例1:
import time
from multiprocessing import Process
def task(): # 任务
print("start...")
time.sleep(3)
print("end...")
if __name__ == '__main__':
# target=任务(函数地址) ---> 创建一个子进程
p_obj = Process(target=task)
# 告诉操作系统去创建一个子进程
p_obj.start()
# 告诉主进程,等待子进程结束后,再执行主进程
p_obj.join()
print("正在执行当前主进程")
执行结果:
start...
end...
正在执行当前主进程
例2:
import time
from multiprocessing import Process
def task(name): # 任务
print(f"start...{name}的子进程")
time.sleep(3)
print(f"end...{name}的子进程")
if __name__ == '__main__':
# target=任务(函数地址) ---> 创建一个子进程
# 异步提交3个任务 (3个子进程)
p_obj1 = Process(target=task, args=("apple", ))
p_obj2 = Process(target=task, args=("orange", ))
p_obj3 = Process(target=task, args=("banana", ))
# 告诉操作系统去创建一个子进程
p_obj1.start()
p_obj2.start()
p_obj3.start()
# 告诉主进程,等待子进程结束后,再执行主进程
p_obj1.join()
p_obj2.join()
p_obj3.join()
print("正在执行当前主进程")
执行结果:
# apple、orange、banana三个进程同时提交
start...apple的子进程
start...orange的子进程
start...banana的子进程
end...apple的子进程
end...orange的子进程
end...banana的子进程
正在执行当前主进程
方式二:继承Process类
import time
from multiprocessing import Process
class MyProcess(Process):
def run(self):
print(f"start...{self.name}的子进程")
time.sleep(3)
print(f"end...{self.name}的子进程")
if __name__ == '__main__':
# 定义一个空列表,将所有的子进程放进去并for循环出来告诉主进程先执行子进程
list1 = []
# 假设10个进程
for i in range(10):
obj = MyProcess()
# 告诉操作系统去创建一个子进程
obj.start()
list1.append(obj)
for obj in list1:
# 告诉主进程,等待子进程结束后,再执行主进程
obj.join()
print("正在执行当前主进程")
执行结果:
# 10个进程同时提交
start...MyProcess-1的子进程
start...MyProcess-2的子进程
start...MyProcess-3的子进程
start...MyProcess-4的子进程
start...MyProcess-5的子进程
start...MyProcess-6的子进程
start...MyProcess-7的子进程
start...MyProcess-8的子进程
start...MyProcess-9的子进程
start...MyProcess-10的子进程
end...MyProcess-1的子进程
end...MyProcess-2的子进程
end...MyProcess-3的子进程
end...MyProcess-4的子进程
end...MyProcess-5的子进程
end...MyProcess-6的子进程
end...MyProcess-7的子进程
end...MyProcess-8的子进程
end...MyProcess-9的子进程
end...MyProcess-10的子进程
正在执行当前主进程
7、问答题
(1)在单核情况下是否可以实现并行?
不可以,并行只能在多核情况下实现
(2)阻塞与同步是一样的吗?非阻塞与异步是一样的吗?
不一样
同步与异步:提交任务的方式
阻塞与非阻塞:进程的状态
补充:
异步非阻塞:异步非阻塞可将cpu的利用率最大化! 用在通过并发对程序进程操作
8、子进程回收资源的两种方式
① join()方法让主进程等待子进程结束,并且回收子进程资源,主进程再结束并回收资源
② 主进程 "正常结束" ,子进程与主进程一并被回收资源
9、僵尸进程和孤儿进程(了解)
僵尸进程(有坏处,手动解决):
在子进程结束后,主进程没有正常结束,子进程PID不会被回收
缺点:
> 操作系统中的PID号是有限的,如有进程PID号无法正常回收,则会占用PID号
> 资源浪费
> 若PID号满了,则无法创建新的进程
孤儿进程(无坏处):
在子进程没有结束时,主进程没有 "正常结束" ,子进程会被操作系统中的“孤儿院”回收
操作系统优化机制(孤儿院):
当主进程意外终止,操作系统会检测是否有正在运行的子进程,会把它们放入孤儿院中,让操作系统帮你自动回收
# 查看进程pid的两种方法
import time
from multiprocessing import Process
# 第一种:在子进程汇总调用,可以拿到子进程对象.pid可以拿到pid号
from multiprocessing import current_process
# 第二种:在子进程汇总调用,可以拿到子进程对象.pid可以拿到pid号
import os
def task():
print(f"start..{current_process().pid}") # 第一种
time.sleep(3)
print(f"end..{os.getpid()}") # 第二种
if __name__ == '__main__':
p = Process(target=task)
# 告诉操作系统开启子进程
p.start()
# 告诉主进程,等待子进程结束后,再执行主进程
p.join()
print("主进程结束...")
执行结果:
start..5224
end..5224
主进程结束...
10、守护进程
守护进程:当主进程结束时,子进程也必须结束,并回收资源
守护进程才能必须在创建子进程(调用p.start())之前设置
# 守护进程演示
import time
from multiprocessing import Process
def demo(name):
print(f"start..{name}")
time.sleep(3)
print(f"end..{name}")
if __name__ == '__main__':
p = Process(target=demo, args=("apple",))
# 守护进程才能必须在调用p.start()之前设置
p.daemon = True # 将子进程p设置为守护进程
# 告诉操作系统开启子进程
p.start()
time.sleep(1)
print("主进程结束...")
执行结果:
start..apple
主进程结束...
11、进程间数据是相互隔离的
from multiprocessing import Process
number = 10
def func():
global number
number += 10
if __name__ == '__main__':
p = Process(target=func)
p.start()
print(number) # 10
执行结果:
10
12、多进程互斥锁
多进程互斥锁是一把锁,将并行改为串行,牺牲了效率,保证了数据读写正确
作用:
某个进程要更改共享数据时,先将其锁定require,此时资源的状态为“锁定”,其他进程不能更改;直到该进程释放资源release,将资源的状态变成“非锁定”,其他的进程才能再次锁定该资源。进程互斥锁保证了每次只有一个进程进行写入操作,从而保证了多进程情况下数据的正确性。
多进程实现并行会造成数据不正确,可以引入互斥锁来避免这种问题(PS:在不使用互斥锁的情况下,假如有10个进程要对一个数据进行修改 -1,正确的结果应该是 -10,但是这10个进程并行同时去对一个数据进行修改,修改的是同一份数据,结果却是 -1,这个时候就出现了数据的不正确;在使用互斥锁的情况下,会将10个进程由并行改为串行,一个一个去对数据进行修改,这样保证每个进程都会对数据修改成功,保证了数据的正确性)
例:
抢票例子:假设有10个用户来查看余票,余票为1张,进行抢票操作
"""
多进程实现并发会造成数据不安全。
"""
from multiprocessing import Process
from multiprocessing import Lock # 进程互斥锁
import json
import time
import random
# 1.查看余票
def search(name):
# 1.读取数据
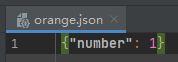
with open(r"data\orange.json", "r", encoding="utf-8") as f:
user_dic = json.load(f)
print(f"用户【{name}】查看的余票为【{user_dic.get('number')}】")
# 2.若有余票,购买成功,票数减少
def buy(name):
# 读取目录data下的orange.json文件
with open(r"data\orange.json", "r", encoding="utf-8") as f:
user_dic = json.load(f)
if user_dic.get('number') > 0:
user_dic["number"] -= 1
# 设置网络延迟,让其他用户同时参与抢票
time.sleep(random.randint(1, 3))
# 最先写入数据文件的证明抢到票
with open(r"data\orange.json", "w", encoding="utf-8") as f:
json.dump(user_dic, f)
print(f"用户【{name}】抢票成功")
else:
print(f"用户【{name}】抢票失败")
def run(name, lock):
# 假设有10个用户来查看余票
search(name)
lock.acquire() # 加锁,第一个人抢到票写入文件之后,其他人就不能对文件进行修改
buy(name)
lock.release() # 释放锁
if __name__ == '__main__':
lock = Lock()
# 开启多进程:实现并发
for line in range(10):
p_obj = Process(target=run, args=(f"谢广坤{line + 1}号", lock))
p_obj.start()
执行结果:
用户【谢广坤1号】查看的余票为【1】
用户【谢广坤2号】查看的余票为【1】
用户【谢广坤3号】查看的余票为【1】
用户【谢广坤4号】查看的余票为【1】
用户【谢广坤6号】查看的余票为【1】
用户【谢广坤5号】查看的余票为【1】
用户【谢广坤7号】查看的余票为【1】
用户【谢广坤8号】查看的余票为【1】
用户【谢广坤9号】查看的余票为【1】
用户【谢广坤10号】查看的余票为【1】
用户【谢广坤1号】抢票成功
用户【谢广坤2号】抢票失败
用户【谢广坤3号】抢票失败
用户【谢广坤4号】抢票失败
用户【谢广坤6号】抢票失败
用户【谢广坤5号】抢票失败
用户【谢广坤7号】抢票失败
用户【谢广坤8号】抢票失败
用户【谢广坤9号】抢票失败
用户【谢广坤10号】抢票失败
13、队列(FIFO)
遵循先进先出原则:
先存放的数据,就先取出来
队列相当于一个第三方的管道,可以存放数据
队列的三种使用方法:
第一种:from multiprocessing import Queue # multiprocessing提供的进程队列,先进先出
第二种:from multiprocessing import JoinableQueue # 基于Queue封装的队列,先进先出
第三种:import queue # python内置的队列queue,先进先出
补充:
队列(FIFO):先进先出
堆栈(FILO):先进后出
应用:让进程之间进行数据交互
例:
第一种方法:multiprocessing提供的进程队列
# 第一种:Queue
from multiprocessing import Queue # multiprocessing提供的进程队列,先进先出
q_obj1 = Queue(5) # q_obj1队列对象,最多可存5个数据
# 添加数据到队列中
q_obj1.put("decade")
print("添加第一个")
q_obj1.put("zio")
print("添加第二个")
q_obj1.put("amazon")
print("添加第三个")
q_obj1.put("build")
print("添加第四个")
q_obj1.put("kabuto")
print("添加第五个")
# put()添加第6个时不会提示报错,队列满了,就会进入阻塞
# q_obj1.put("ooo")
# put_nowait()添加第6个时会提示报错
# q_obj1.put_nowait("ooo")
# 从队列中取数据
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
# .get()取出第6个时不会提示报错,全部取出之后再取,就会进入阻塞
# print(q_obj1.get())
# .get_nowait()取出第6个时会提示报错
# print(q_obj1.get_nowait())
执行结果:
添加第一个
添加第二个
添加第三个
添加第四个
添加第五个
decade
zio
amazon
build
kabuto
第二种方法:基于Queue封装的队列
# 第二种:JoinableQueue
from multiprocessing import JoinableQueue # 基于Queue封装的队列,先进先出
q_obj1 = JoinableQueue(5) # q_obj1队列对象,最多可存5个数据
# 添加数据到队列中
q_obj1.put("decade")
print("添加第一个")
q_obj1.put("zio")
print("添加第二个")
q_obj1.put("amazon")
print("添加第三个")
q_obj1.put("build")
print("添加第四个")
q_obj1.put("kabuto")
print("添加第五个")
# put()添加第6个时不会提示报错,队列满了,就会进入阻塞
# q_obj1.put("ooo")
# put_nowait()添加第6个时会提示报错
# q_obj1.put_nowait("ooo")
# 从队列中取数据
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
# .get()取出第6个时不会提示报错,全部取出之后再取,就会进入阻塞
# print(q_obj1.get())
# .get_nowait()取出第6个时会提示报错
# print(q_obj1.get_nowait())
执行结果:
添加第一个
添加第二个
添加第三个
添加第四个
添加第五个
decade
zio
amazon
build
kabuto
第三种方法:python内置的队列queue
# 第三种:queue
import queue # python内置的队列,先进先出
q_obj1 = queue.Queue(5) # q_obj1队列对象,最多可存5个数据
# 添加数据到队列中
q_obj1.put("decade")
print("添加第一个")
q_obj1.put("zio")
print("添加第二个")
q_obj1.put("amazon")
print("添加第三个")
q_obj1.put("build")
print("添加第四个")
q_obj1.put("kabuto")
print("添加第五个")
# put()添加第6个时不会提示报错,队列满了,就会进入阻塞
# q_obj1.put("ooo")
# put_nowait()添加第6个时会提示报错
# q_obj1.put_nowait("ooo")
# 从队列中取数据
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
print(q_obj1.get())
# .get()取出第6个时不会提示报错,全部取出之后再取,就会进入阻塞
# print(q_obj1.get())
# .get_nowait()取出第6个时会提示报错
# print(q_obj1.get_nowait())
执行结果:
添加第一个
添加第二个
添加第三个
添加第四个
添加第五个
decade
zio
amazon
build
kabuto
14、IPC机制(进程间实现通信)
使用队列可以使进程之间互相进行通信
例:foo和goo两个函数之间进行数据通信
from multiprocessing import Process
from multiprocessing import JoinableQueue
import time
def foo(q):
x = 100
q.put(x) # 向队列中添加数据
print("foo:添加数据成功!")
time.sleep(2) # 遇到IO操作阻塞,执行goo子进程,goo子进程执行完成(无IO操作阻塞的情况下),继续执行foo子进程
from_goo = q.get() # 向队列中取数据
print(f"foo:从goo中获取到的数据为{from_goo}")
def goo(q):
from_foo = q.get() # 向队列中取数据
print(f"goo:从foo中获取到的数据为{from_foo}")
q.put(200) # 向队列中添加数据
print("goo:添加数据成功!")
if __name__ == '__main__':
q = JoinableQueue(10) # 创建队列可添加数据为10个
# 创建子进程
p1 = Process(target=foo, args=(q, ))
p2 = Process(target=goo, args=(q, ))
# 执行子进程
p1.start()
p2.start()
执行结果:
foo:添加数据成功!
goo:从foo中获取到的数据为100
goo:添加数据成功!
foo:从goo中获取到的数据为200
15、生产者与消费者
生产者:生产数据的
消费者:使用数据的
问题:供需不平衡
通过队列来实现解决供不应求的问题
from multiprocessing import JoinableQueue
from multiprocessing import Process
import time
# 生产者:生产数据添加队列中
def producer(name, food, obj):
info = f"【{name}】生产了【{food}】食物"
# 将生产的数据添加队列中
obj.put(food)
print(info)
# 消费者
def customer(name, obj):
while True:
try:
time.sleep(0.5)
# 从队列中取出数据
food = obj.get_nowait()
# 若food中数据为None,跳出循环
if not food:
break
info = f"【{name}】吃到了【{food}】食物"
print(info)
except Exception:
break
if __name__ == '__main__':
obj = JoinableQueue()
# 创建10个生产者
for i in range(10):
p1 = Process(target=producer, args=("Trump", f"thread{i}号", obj))
p1.start()
# 创建2个消费者
c1 = Process(target=customer, args=("abc", obj))
c2 = Process(target=customer, args=("qwe", obj))
# 开始执行子程序
c1.start()
c2.start()
执行结果:
【Trump】生产了【thread0号】食物
【Trump】生产了【thread2号】食物
【Trump】生产了【thread1号】食物
【Trump】生产了【thread3号】食物
【Trump】生产了【thread4号】食物
【Trump】生产了【thread6号】食物
【Trump】生产了【thread5号】食物
【Trump】生产了【thread8号】食物
【Trump】生产了【thread7号】食物
【Trump】生产了【thread9号】食物
【abc】吃到了【thread0号】食物
【qwe】吃到了【thread2号】食物
【abc】吃到了【thread1号】食物
【qwe】吃到了【thread3号】食物
【abc】吃到了【thread4号】食物
【qwe】吃到了【thread6号】食物
【abc】吃到了【thread5号】食物
【qwe】吃到了【thread8号】食物
【abc】吃到了【thread7号】食物
【qwe】吃到了【thread9号】食物
16、补充:创建执行子进程注意点
windows系统:
当创建进程时,会将当前py文件的会由上到下重新执行一次,当执行到创建子进程时,会再一次将当前py文件的会由上到下重新执行一次,依次执行,就会进入死循环,所以在windows系统执行创建子进程时,我们需要将执行代码放在if __name__ == '__main__'中执行。
linux系统:
在linux系统,会直接复制一份代码去执行,无需将执行代码放在if __name__ == '__main__'中执行。
PS:创建子进程续注意,子线程无此问题。
from multiprocessing import Process def task(): pass if __name__ == '__main__': # 创建子进程 p = Process(target=task) p.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号