Hadoop(四)HDFS集群详解
阅读目录(Content)
- 一、HDFS概述
- 1.1、HDFS概述
- 1.2、HDFS的概念和特性
- 1.3、HDFS的局限性
- 1.4、HDFS保证可靠性的措施
- 二、HDFS基本概念
- 2.1、HDFS主从结构体系
- 2.2、数据块(DataBlock)
- 2.3、名字节点(主节点:NameNode)
- 2.4、数据节点(从节点:DataNode)
- 2.5、SecondaryNameNode
- 2.6、总结NameNode和DataNode
- 四、单点故障(单点失效)问题
- 4.1、单点故障问题
- 4.2、解决方案
- 五、细说HDFS高可用性(HA:High-Availability)
- 六、HDFS的shell(命令行客户端)操作
- 6.1、HDFS的shell操作
前言
前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群。接下来这篇我详细的分享一下HDFS。
HDFS前言:
设计思想:(分而治之)将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析。
在大数据系统中作用:为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务。
分布式文件系统:
问题引发:海量数据超过了单台物理计算机的存储能力
解决方案:对数据分区存储与若干台物理主机中
分布式文件系统应运而生:
1)管理网络中跨多台计算机存储的文件系统
2)HDFS就是这样的一个分布式文件系统
一、HDFS概述
1.1、HDFS概述
1)HDFS集群分为两大角色:NameNode、DataNode
2)NameNode负责管理整个文件系统的元数据
3)DataNode负责管理用户的文件数据块
4)文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5)每一个文件块可以有多个副本,并存放在不同的datanode上
6)DataNode会定期向NameNode汇报自身保存的block信息,而namenode则会负责保持文件的副本数量
7)HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过namenode申请来进行
1.2、HDFS的概念和特性
1)HDFS的概念
HDFS采用了主从式(Master/Slave)的体系结构,其中NameNode(NN),DataNode(DN)和Client是HDFS中的3个重要角色。HDFS也在社区的努力下不断演进,包括支持文件追加,Federation,HA的引入等。
在一个HDFS中,有一个NN,一个SNN(Secondary NameNode)和众多的DN,在大型的集群中可能会有数以千计的DN。而Client,一般意义上比数据节点的个数还要多。
NN管理了HDFS两个最重要的关系:
1)目录文件树结构和文件与数据块的对应关系:会持久化到物理存储中,文件名叫做fsimage。
2)DN与数据块的对应关系,即数据块存储在哪些DN中:在DN启动时会上报到NN它所维护的数据块。这个是动态建立的,不会持久化。因此,集群的启动可能需要比较长的时间。
而DN则保存了数据块。并且执行NN的命令,比如复制,拷贝,删除等操作。Client则是使用HDFS的主题,包括写文件,读文件等常见操作。
总的来说:HDFS是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件。其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
2)HDFS的特性
2.1)HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定默认大小在hadoop2.x版本中是128M,老版本中的64M
2.2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
2.3)目录结构及文件分块信息(元数据)的管理由namenode节点承担 namenode是HDFS集群主节点,负责维护整个HDFS文件系统的目录树以及每一个路径(文件)对应的block块信息(block的id,以及所在的datanode服务器)
2.4)文件的各个block的存储管理由datanode节点承担 datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本参数也可以通过参数设置dfs.replication)
2.5)HDFS适应一次写入,多次读出的场景,且不支持文件的修改。
注意:适合用来做数据分析,并不适合用来做网盘应用(因为不方便进行修改,延迟大,网络开销大,成本太高)
3)我们通过一张图来解释
通过上面的描述我们知道,hdfs很多特点:
保存多个副本,且提供容错机制,副本丢失或宕机自动恢复(默认存3份)。
运行在廉价的机器上
适合大数据的处理。HDFS默认会将文件分割成block,,在hadoop2.x以上版本默认128M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
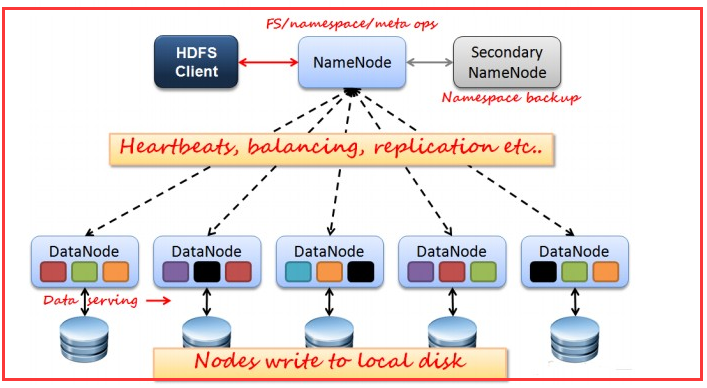
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
1.3、HDFS的局限性
1)低延时数据访问。在用户交互性的应用中,应用需要在ms或者几个s的时间内得到响应。由于HDFS为高吞吐率做了设计,也因此牺牲了快速响应。对于低延时的应用,可以考虑使用HBase或者Cassandra。
2)大量的小文件。标准的HDFS数据块的大小是64M,存储小文件并不会浪费实际的存储空间,但是无疑会增加了在NameNode上的元数据,大量的小文件会影响整个集群的性能。
前面我们知道,Btrfs为小文件做了优化-inline file,对于小文件有很好的空间优化和访问时间优化。
3)多用户写入,修改文件。HDFS的文件只能有一个写入者,而且写操作只能在文件结尾以追加的方式进行。它不支持多个写入者,也不支持在文件写入后,对文件的任意位置的修改。
但是在大数据领域,分析的是已经存在的数据,这些数据一旦产生就不会修改,因此,HDFS的这些特性和设计局限也就很容易理解了。HDFS为大数据领域的数据分析,提供了非常重要而且十分基础的文件存储功能。
1.4、HDFS保证可靠性的措施
1)冗余备份
每个文件存储成一系列数据块(Block)。为了容错,文件的所有数据块都会有副本(副本数量即复制因子,课配置)(dfs.replication)
2)副本存放
采用机架感知(Rak-aware)的策略来改进数据的可靠性、高可用和网络带宽的利用率
3)心跳检测
NameNode周期性地从集群中的每一个DataNode接受心跳包和块报告,收到心跳包说明该DataNode工作正常
4)安全模式
系统启动时,NameNode会进入一个安全模式。此时不会出现数据块的写操作。
5)数据完整性检测
HDFS客户端软件实现了对HDFS文件内容的校验和(Checksum)检查(dfs.bytes-per-checksum)。
二、HDFS基本概念
2.1、HDFS主从结构体系
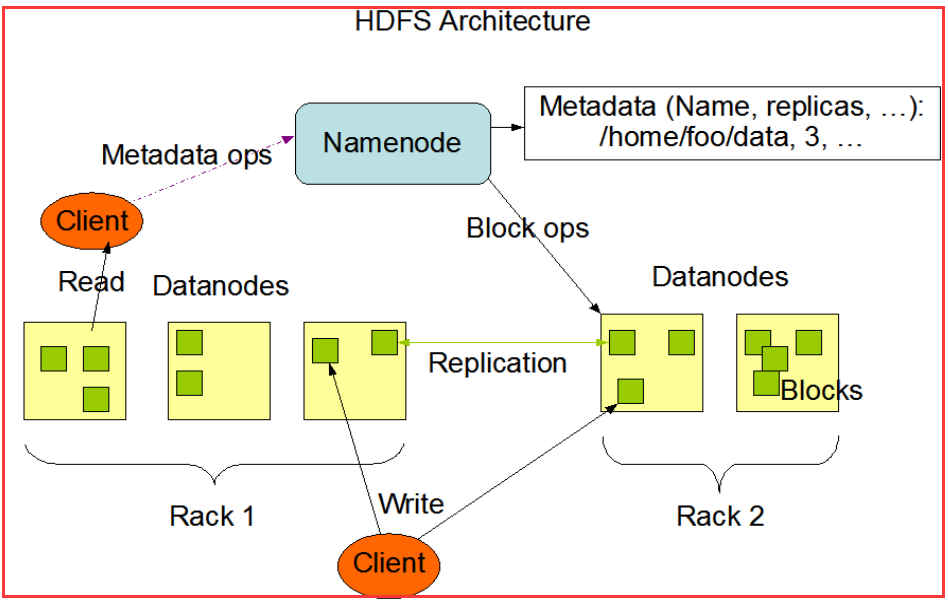
2.2、数据块(DataBlock)
HDFS将每个文件存储成一系列的数据块,所有的数据块都是同样的大小。(在配置文件中配置每个数据块的大小,最后一块不一定大小一样)
文件中所有的数据块都会有副本,每个文件的数据块大小和副本系数都是可配置的。
HDFS中的文件都是一次写入的,并且严格要求在任何时候只能有一个写入者。
我们可以查看到通过:hdfs fsck / -file -bloks -locations
HDFS的配置参数:dfs.replication、dfs.blocksize

2.3、名字节点(主节点:NameNode)
1)概述
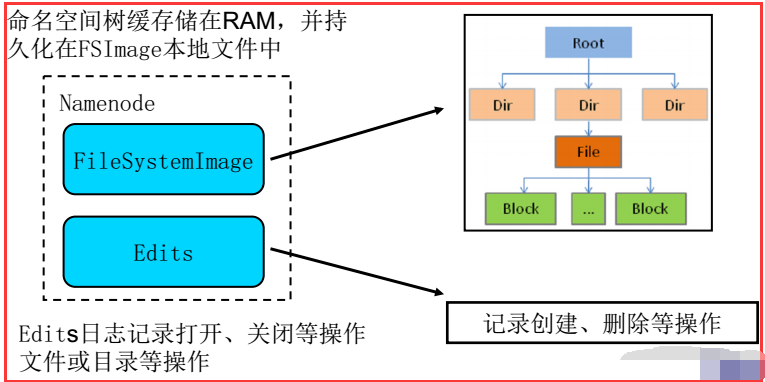
-NN是HDFS主从结构中主节点上运行的主要进程,它负责管理从节点DN。NN维护着整个文件系统的文件目录树,文件目录的元信息和文件的数据块索引。
这些信息以两种信息保存在本文文件系统中,一种是文件系统镜像(文件名字fsimage),另一种是fsimage的编辑日志(文件名字edits)。
-fsimage中保存着某一特定时刻HDFS的目录树、元信息和文件数据块的索引等信息,后续的对这些信息的改动,则保存在编辑日志中,它们一起提供了一个完整的NN的第一关系。
-通过NN,Client还可以了解到数据块所在的DN的信息。需要注意的是,NN中关于DN的信息是不会保存到NN的本地文件系统的,也就是上面提到的fsimage和edits中。
NN每次启动时,都会通过每个DN的上报来动态的建立这些信息。这些信息也就构成了NN第二关系。
-NN还能通过DN获取HDFS整体运行状态的一些信息,比如系统的可用空间,已经使用的空间,各个DN的当前状态等。
2)作用
维护着文件系统数中所有文件和目录的元数据
协调客户端对文件的访问
2.4、数据节点(从节点:DataNode)
1)概述
DN是HDFS中硬盘IO最忙碌的部分:将HDFS的数据块写到Linux本地文件系统中,或者从这些数据块中读取数据。DN作为从节点,会不断的向NN发送心跳。
初始化时,每个DN将当前节点的数据块上报给NN。NN也会接收来自NN的指令,比如创建、移动或者删除本地的数据块,并且将本地的更新上报给NN。
2)作用
接受客户端或NameNode的调度
存储和检索数据块
在NameNode的统一调度下进行数据块的创建、删除和复制
定期向NameNode发送自身存储的数据块列表
2.5、SecondaryNameNode
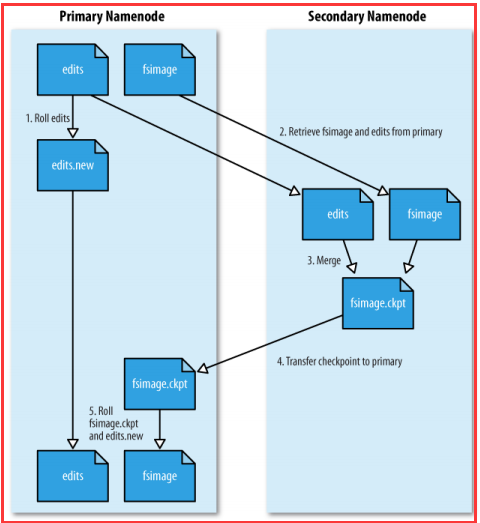
1)定期合并edits和fsImage(如果没有配置SecondaryNameNode由NameNode自己完成)
Secondary NameNode是用于定期合并fsimage和edits的。与NN一样,每个集群都有一个SNN,在大规模部署的条件下,一般SNN也独自占用一台服务器。
SNN按照集群配置的时间建个,不停的获取HDFS某一个时间点的fsimage和edits,合并它们得到一个新的fsimage。该fsimage上传到NN后会替换NN的老的fsimage。
2)防止edits日志文件过大
从上面可以看出,SNN会配合NN,为NN的第一关系提供了一个简单的CheckPoint机制,并避免出现edits过大,导致NN启动时间过长的问题。
3)提供那个NameNode的fsImage文件的检查点,以实现NameNode故障恢复
2.6、总结NameNode和DataNode
-HDFS集群有两种节点类型,Namenodes和Datanodes,它们工作于master-worker模式。一个namenode是master,一组datanodes是workers。namenode管理整个文件系统的namespace。
它维护一棵文件树和所有文件/目录的元信息。这些信息在namenode的本地磁盘上存成两个文件,一个是该namespace的镜像,另一个是编辑日志(edit log)。
namenode也知道每个文件的每个块都存在哪个datanode上了,但这个信息不会被持久化下来,因为每次启动时,这个信息会被重新生成。
-客户端程序通过访问namenode和datanodes来访问HDFS文件系统。但是用户代码根本不知道namenode和datanodes的存在,就像访问POSIX一样(Portable Operating System Interface:便携计算机系统接口)。
Datanodes是干苦力活的。当被客户端或namenode命令时,它存储和检索文件块(blocks)。它还会定期向namenode汇报它们存储的文件块列表。
-没有namenode,整个文件系统就没法用了。如果把namenode移除,整个文件系统里的文件就都丢失了,因为没办法知道如何重新组装存在各个datanodes里的文件块。
因此有必要保证namenode足够可靠,Hadoop提供了两种机制保证namenode里的数据安全。
-第一个机制是备份namenode上的持久化信息。可以配置hadoop,让namenode写持久化信息时写到多个地方,并且这些写操作是串行的并且是原子操作。通常的做法是写到本地磁盘一份,同时写到远程NFS上。
-另一个机制是配一个secondary namenode。虽然名字上叫namenode,但secondary namenode根本不做namenode的工作,它就是定期把namenode上的namespace镜像和编辑日志(edit log)合并到自己身上,以避免编辑日志过大。
secondary namenode通常是一台单独的机器,因为合并工作需要大量的CPU和内存资源。因为它的状态迟于namenode,所以,当namenode发生事故时,肯定是会有数据丢失的。
通常的做法是把namenode在NFS上的metadata文件拷贝到secondary namenode,然后启动这个secondary namenode,让它成为namenode。
四、单点故障(单点失效)问题
4.1、单点故障问题
如果NameNode失效,那么客户端或MapReduce作业均无法读写查看文件
4.2、解决方案
1)启动一个拥有文件系统元数据的新NameNode(这个一般不采用,因为复制元数据非常耗时间)
2)配置一对活动-备用(Active-Sandby)NameNode,活动NameNode失效时,备用NameNode立即接管,用户不会有明显中断感觉。
共享编辑日志文件(借助NFS、zookeeper等)
DataNode同时向两个NameNode汇报数据块信息
客户端采用特定机制处理 NameNode失效问题,该机制对用户透明
五、细说HDFS高可用性(HA:High-Availability)
1)前面在(2. Namenodes和Datanodes)提到的通过备份namenode上的持久化信息,或者通过secondary namenode的方式,只能解决数据不丢失,但是不能提供HA(高可用性),
namenode仍然是“单点失败”(SPOF:single point of failure)。如果namenode死掉了,所有的客户端都不能访问HDFS文件系统里的文件了,不能读写也不能列出文件列表。
六、HDFS的shell(命令行客户端)操作
6.1、HDFS的shell操作
2)运行一个文件系统命令在Hadoop集群支持的文件系统中
6.2、HDFS DFS命令详解
检查需要处理的数据(假定数据已经存放在hdfs的/user/hadoop⽬录下)
$> hadoop fs -ls /user/hadoop
看到测试数据⽬录weather_test,完整数据⽬录weather,专利数据⽬录patent即可,若没有则请从服务器下载并上传⾃⼰的⽬录下
1)建⽴⽬录(在hdfs的/user/xxx⽬录下操作)
$> hdfs dfs -mkdir input

2)查看⽂件或⽬录
$> hdfs dfs -ls

3)⽂件上传(将本地⽂件local_file上传到hdfs的/user/xxx⽬录下)
$> hdfs dfs -put local_file input
4)下载⽂件或⽬录到本地当前⽬录下
$> hdfs dfs -get input .
5)浏览hdfs中的⽂件
$> hdfs dfs -cat input/local_file
6)删除⽂件或者⽬录
$> hdfs dfs -rm input/local_file
7)在hdfs中复制⽂件或⽬录
$> hdfs dfs -cp input/local_file input/local_file.bak
8)修改权限

9)查看命令帮助
$> hdfs dfs -help [cmd]
6.3、HDFS管理命令
1)系统⽬录检查
$> hdfs fsck /user/xxx系统⽬录详细检测
$> hdfs fsck /user/xxx -files -blocks -locations -racks
2)检测DataNode报告
$> hdfs dfsadmin -report
3)权限管理
$> hdfs fs -chmod 666 /user/xxx
4)hdfs空间⽬录配额设置
$> hdfs dfsadmin -setSpaceQuota [N] /user/xxx
5)hdfs空间⽬录配额清除
$> hdfs dfsadmin -clrSpaceQuota /user/xxx
6)查看⽬录配额设置
$> hdfs fs -count -q /user/xxx
7)删除DataNode
$> hdfs dfsadmin -refreshNodes
总结:
注意HDFS中的文件系统也是和linux文件系统一样的。既然是文件系统也有根目录和家目录,在HDFS中“/”代表的就是根目录,而“/user”等于linux中的“/usr”下一级目录代表的就是用户了。
但是HDFS没有这个用户,所以就有了虚拟用户,也就是你当前HDFS的Linux系统当前用户就会默认为它的虚拟用户。当我们有一个zyh用户时,所以你就可以创建一个/user/zyh/下面的目录,就代表着家目录。
-END-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号