《闲扯Redis二》String数据类型之底层解析
原文出处:http://www.yund.tech/zdetail.html?type=1&id=585ee331353551a44b29a9e9a09a1570
作者: jstarseven
一、前言
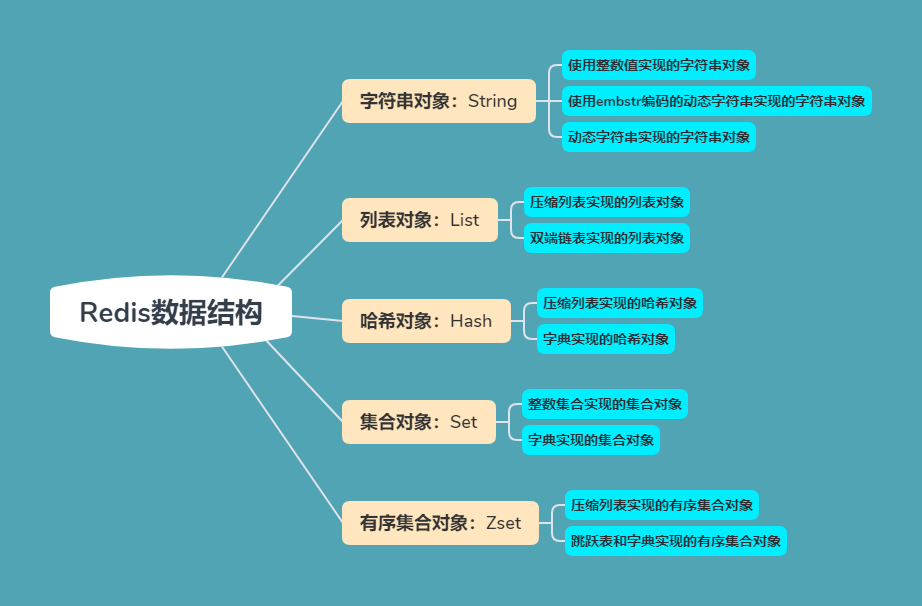
Redis 提供了5种数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合),理解每种数据类型的特点对于redis的开发和运维非常重要。
二、疑问与解析
结构图上显示,String类型有三种实现方式:
- 使用整数值实现的字符串对象
- 使用 embstr 编码的动态字符串实现的字符串对象
- 动态字符串实现的字符串对象
疑问:embstr 是什么意思,动态字符串又是什么意思?字符串对象到底什么结构?三种实现方式有什么区别呢?

不急,咱们一步一步的往下看:
1、Redis中定义的对象的结构体
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型 4bits
unsigned type:4;
// 编码方式 4bits
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock) 24bits
unsigned lru:22;
// 引用计数 Redis里面的数据可以通过引用计数进行共享 32bits
int refcount;
// 指向对象的值 64-bit
void *ptr;
} robj;// 16bytes
注释:type表示该对象的类型,即上面 [String,List,Hash,Set,Zset] 中的一个,但为了提高存储效率与程序执行效率,每种对象的底层数据结构实现都可能不止一种,encoding 表示对象底层所使用的编码。
2、Redis对象底层八种数据结构
REDIS_ENCODING_INT(long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
3、embstr与动态字符串
embstr :是专门用于保存短字符串的一种优化编码方式,跟正常的字符编码相比,字符编码会调用两次内存分配函数来分别创建 redisObject 和 sdshdr 结构(动态字符串结构),而 embstr 编码则通过调用一次内存分配函数来分配一块连续的内存空间,空间中包含 redisObject 和 sdshdr(动态字符串)两个结构,两者在同一个内存块中。从 Redis 3.0 版本开始,字符串引入了 embstr 编码方式,长度小于 OBJ_ENCODING_EMBSTR_SIZE_LIMIT(39) 的字符串将以EMBSTR方式存储。
注意: 在Redis 3.2 之后,就不是以 39 为分界线,而是以 44 为分界线,主要与 Redis 中内存分配使用的是 jemalloc 有关。( jemalloc 分配内存的时候是按照 8、16、32、64 作为 chunk 的单位进行分配的。为了保证采用这种编码方式的字符串能被 jemalloc 分配在同一个 chunk 中,该字符串长度不能超过64,故字符串长度限制
OBJ_ENCODING_EMBSTR_SIZE_LIMIT = 64 - sizeof('0')为1 - sizeof(robj) 为16 - sizeof(struct sdshdr)为8 = 39)
动态字符串 :Redis 自己构建的一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis 的默认字符串表示。先简单了解概念,后面看详细解析
4、带着疑问来细品下面一段话
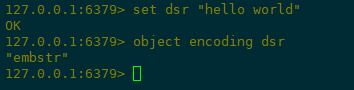
字符串的编码可以是 int,raw 或者 embstr。如果一个字符串内容可转为 long,那么该字符串会被转化为 long 类型,对象 ptr 指向该 long,并且对象类型也用 int 类型表示。普通的字符串有两种 embstr 和 raw。如果字符串对象的长度小于 39 字节,就用 embstr,否则用 raw。
也就是说,Redis 会根据当前值的类型和长度决定使用内部编码实现:恍然大悟
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39个字节的字符串
5、实践验证
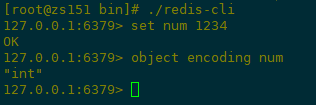
命令:object encoding key ,获取数据底层的数据结构
1)整数类型示例如下:
2)短字符串示例如下:
3)长字符串示例如下:

疑问:至此,我们知道了embstr、字符串对象, 但是动态字符串的结构还是没说清楚啊,你是不是在逗我?
靓仔疑问,再一次出现,别急,继续往下看
三、动态字符串
众所周知,Redis 是用 C 语言写的,但是对于 Redis 的字符串,却不是 C 语言中的字符串(即以空字符 ’\0’ 结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis 的默认字符串表示。
1、动态字符串结构分析
SDS 定义:
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度 4byte
int len;
//记录 buf 数组中未使用字节的数量 4byte
int free;
//字节数组,用于保存字符串 字节\0结尾的字符串占用了1byte
char buf[];
}
用 SDS 保存字符串 “Redis” 具体结构如下图
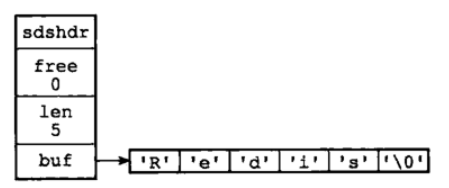
对于 SDS 数据类型的定义:
- len 保存了SDS保存字符串的长度
- buf[] 数组用来保存字符串的每个元素
- free 记录了 buf 数组中未使用的字节数量
上面的定义相对于 C 语言对于字符串的定义,多出了 len 属性以及 free 属性。为什么不直接使用 C 语言字符串实现,而是要使用 SDS 呢?有什么特别的优势呢?
2、SDS结构与C语言字符串结构比较分析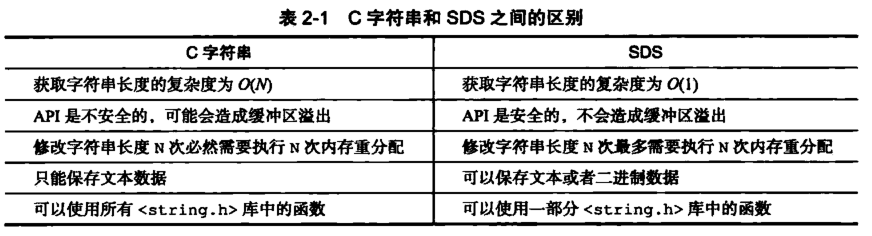
1)获取字符串长度复杂度
sdshdr 中由于 len 属性的存在,获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1),而对于 C 语言来说,获取字符串的长度通常是遍历字符串计数来实现的,时间复杂度为 O(n)。
2)API安全性与缓冲区溢出
缓冲区溢出(buffer overflow):是这样的一种异常,当程序将数据写入缓冲区时,会超过缓冲区的边界,并覆盖相邻的内存位置。在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出,如

s1 = 'Redis',s2 = 'MongoDB',当执行strcat(s1, " Cluster")时,未给 s1 分配足够内存空间,s1 的数据将溢出到 s2 所在的内存空间,导致 s2 保存的内容被意外地修改。

由于 SDS 记录了自身长度,同时在修改时,API 会按照如下步骤进行:
(1)先检查SDS的空间是否满足修改所需的要求;
(2)如果不满足要求的话,API 会自动将 SDS 的空间扩展至执行修改所需的大小(realloc);
(3)然后才执行实际的修改操作;
所以SDS不会造成缓冲区溢出情况
3)字符串的内存重分配次数
C 语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存。
SDS 实现了空间预分配和惰性释放两种策略:
(1)空间预分配:当 SDS 的 API 对一个 SDS 进行修改,并且需要对 SDS 进行空间扩展的时候,程序不仅会为 SDS 分配修改所必须的空间,还会为 SDS 分配额外的未使用空间,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
(2)惰性释放:当 SDS 的 API 需要对 SDS 保存的字符串进行缩短时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来使用,如
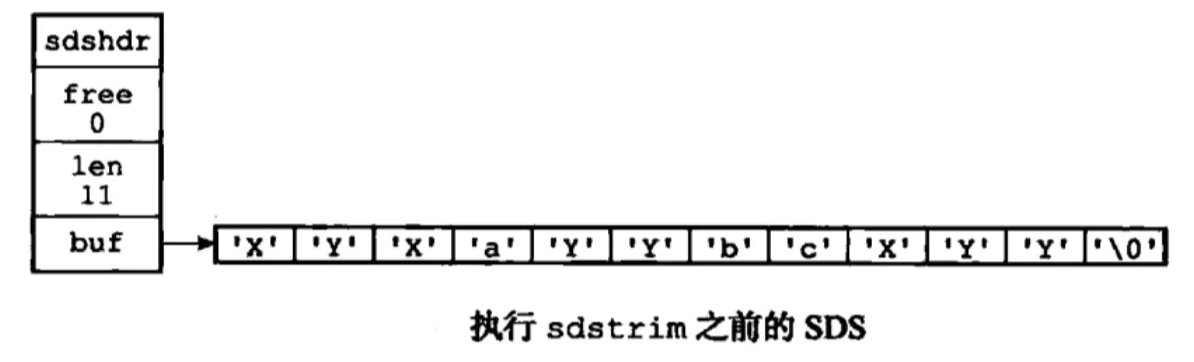
sdstrim(s, "XY"); // 移除 SDS 字符串中的所有 'X' 和 'Y'
结果
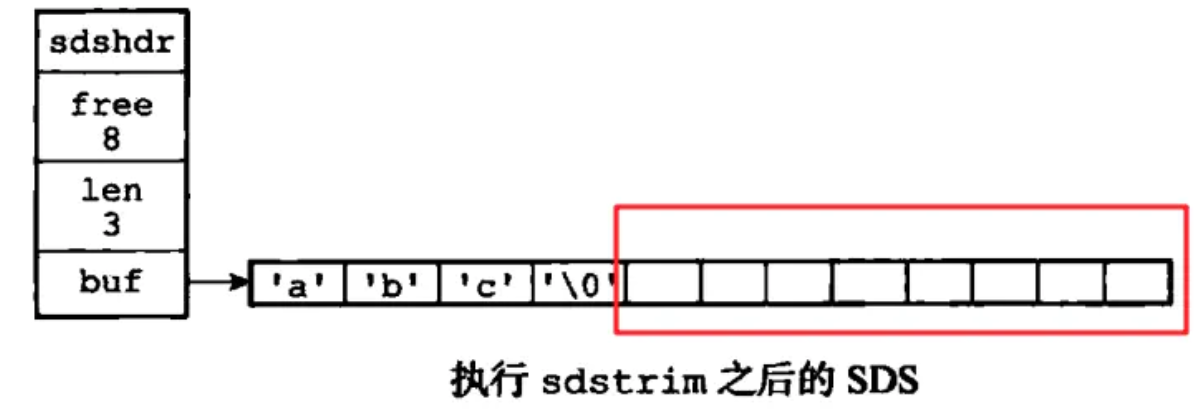
4)二进制数据安全
二进制安全(binary-safe):指能处理任意的二进制数据,包括非 ASCII 和 null 字节。
C 字符串以空字符 '\0',作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串'\0',导致程序读入的空字符会被误认为是字符串的结尾,因此C字符串无法正确存取二进制数据;
SDS 的 API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串'\0'来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束,
因此 Redis 不仅可以保存文本数据,还可以保存任意格式的二进制数据。
5)C字符串函数兼容
SDS 的buf数组会以'\0'结尾,这样可以重用 C 语言库<string.h> 中的一部分函数,避免了不必要的代码重复。
四、要点总结
String 类型对象三种实现方式,int,embstr,raw
字符串内容可转为 long,采用 int 类型,否则长度<39(3.2版本前39,3.2版本后分界线44) 用 embstr,其他用 raw
SDS 是Redis自己构建的一种简单动态字符串的抽象类型,并将 SDS 作为 Redis 的默认字符串表示
SDS 与 C 语言字符串结构相比,具有五大优势



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-03-28 《七哥说道》第九章:骚年,请接好你的锅