《Java 底层原理》Java 字节码详解
前言
我们在开发中会遇到一些Java的执行超出我们的想象,但是又不知道他为什么会这样执行,这个时候我们就需要能够知道他编译后Class文件是什么样子的,并且理解字节码的含义。
Java字节码的原理
进制
class文件就是字节码文件,直接是打不开,打开也是乱码,需要解析才能看明白里面的内容。
现在存在很多语言都是允许在Jvm上,比如Kotlin。 他们其实就是通过编译也编译成Jvm认识的.class 文件即可。
大端和小端
大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:
地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式:是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,
高地址部分权值高,低地址部分权值低。
字节码文件内容组成结构
Java class文件的内容结构

下面解析一下一个不太好理解的结构。
1. 魔数:用于判断这个文件是不是class合格的文件。
2. 次版本号和主板本号:主板本号加次版本号用于判断这个class文件是否能被这个版本的Jvm 解析, 比如jdk8的class就不能被java7版本的Jvm解析。
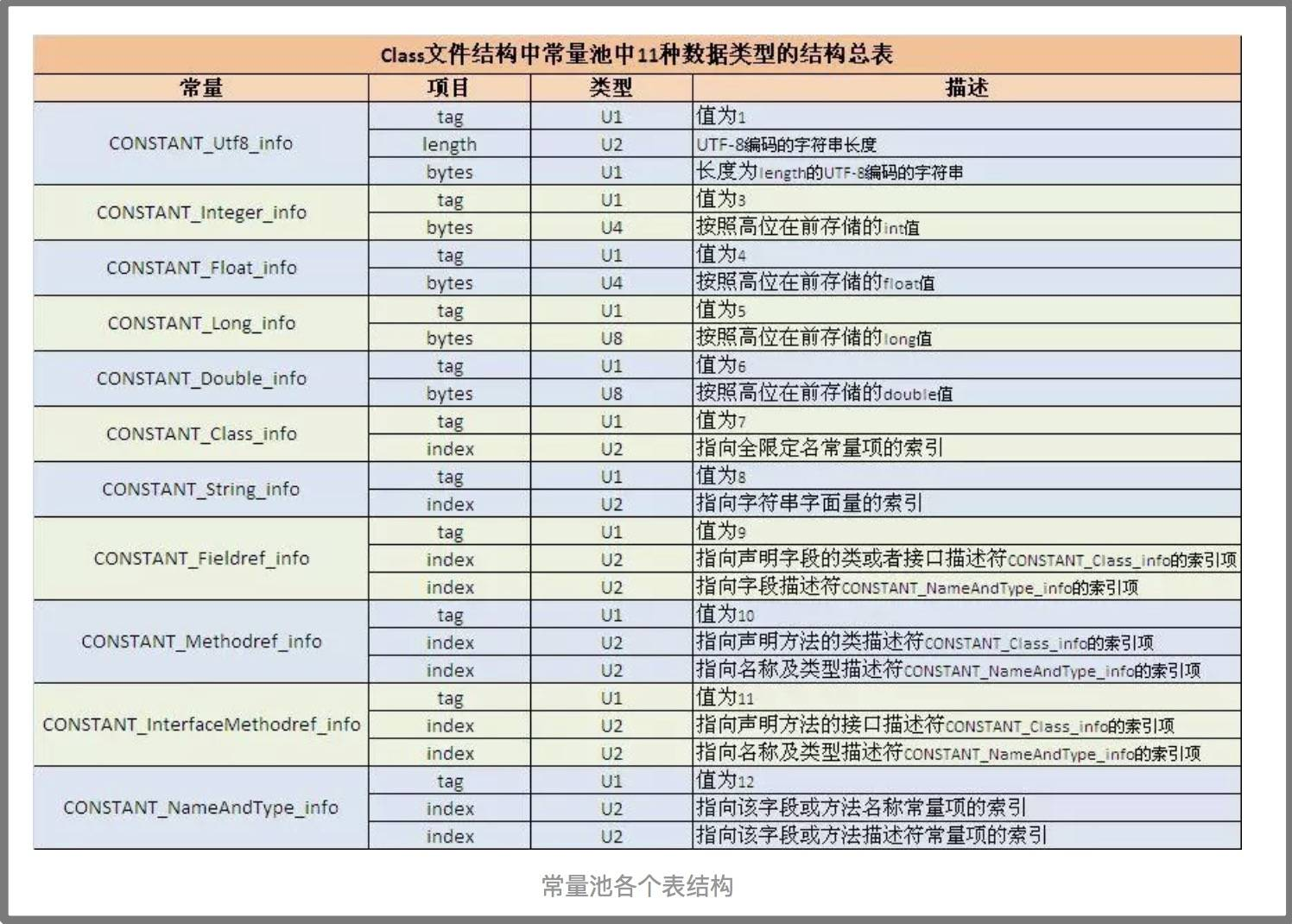
3. 常量池个数,最小是1,真实的常量池个数是2个字节计算出来的数量 - 1。
下面是常量池的字节码结构(u1 就是一个字节,u2 就是两个字节,类推):
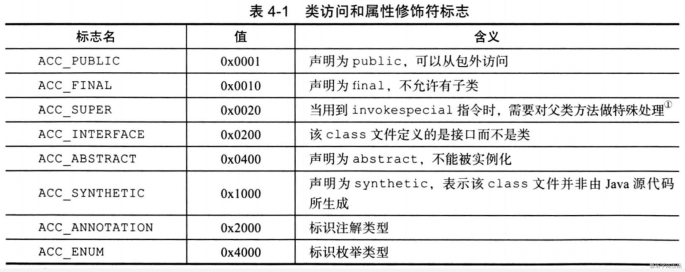
4. 类的访问控制权限
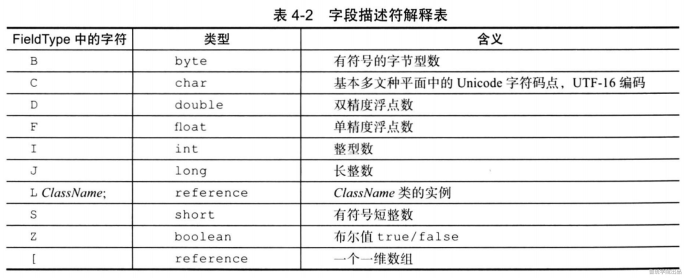
filed_info: {
u2 access_flags; -- 属性的访问类型和修饰符
u2 name_index; -- 成员变量的名字,指向常量池的地址
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
6. 方法的字节码格式:
method_info {
u2 access_flags; -- 方法的访问属性和修饰符
u2 name_index; -- 方法的名字,指向常量池的地址
u2 descriptor_index; -- 描述符字符串,指向常量池地址,mian方法的描述符([java/lang/String;)v
u2 attributes_count; -- 对应下面的code_attribute
attribute_info attributes[attributes_count];
}
一般一个类除了你定义的方法外还会存在两个方法,clinit 和 init 处理你的静态代码和默认构造函数。
方法字节码:还包含:
code_attribute { -- Code_attribute包含某个方法、实例初始化方法、类或接口初始化方法的Java虚拟机指令及相关辅助信息
u2 attribute_name_index; -- 指向常量池,名称
u4 attribute_length; -- 后面全部的总长度
u2 max_stack; -- 用来给出当前方法的操作数栈在方法执行的任何时间点的最大深度
u2 max_locals; -- 用来给出分配在当前方法引用的局部变量表中的局部变量个数
u4 code_length; --给出当前方法code[]数组的字节数
u1 code[code_length]; -- 给出了实现当前方法的Java虚拟机代码的实际字节内容(这些数字代码实际对应一些Java虚拟机的指令)
u2 exception_table_lentgh; -- 异常的信息个数
{
u2 start_pc; -- 这两项的值表明了异常处理器在code[]中的有效范围,即异常处理器x应满足:start_pc≤x≤end_pc
u2 end_pc; -- start_pc必须在code[]中取值,end_pc要么在code[]中取值,要么等于code_length的值
u2 handler_pc; -- 表示一个异常处理器的起点
u2 catch_type; -- 表示当前异常处理器需要捕捉的异常类型。为0,则都调用该异常处理器,可用来实现finally。
} exception_table[exception_table_lentgh];
u2 attribute_count; -- 表示该方法的其它附加属性,
attribute_info attributes[attributes_count]; -- LineNumberTable、LocalVariableTable
}
Java方法所在行信息:
LineNumberTable_attribute{ --被调试器用来确定源文件中由给定的行号所表示的内容,对应于Java虚拟机code[] 数组的哪部分 u2 attribute_name_index; u4 attribute_length; u2 line_number_table_length; { u2 start_pc; u2 line_number; -- 该值必须与源文件中对应的行号相匹配 } line_number_table[line_number_table_length]; }
局部变量表信息:
LocalVariableTable_attribute{ u2 attribute_name_index; u4 attribute_length; u2 local_variable_table_length; { u2 start_pc; u2 length; u2 name_index; u2 descriptor_index; --用来表示源程序中局部变量类型的字段描述符 u2 index; } local_variable_table[local_variable_table_length]; }
7.类属性字节码格式:
attribute_info: {
u2 attribute_name_index;
u1 attribute_length;
u1 info[attribute_length];
}
字节码文件解析
我们一起看一下Java编译后的class文件:
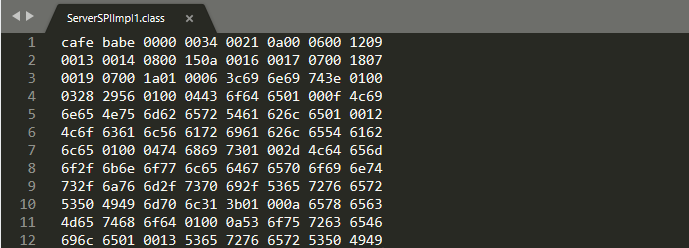
这个是按照16进制显示的,没有按照任何编码的方式进行解析过的原信息。
我们按照上面字节码文件内容组成结构,来解析一下这个字节码文件
魔数:cafe babe 就表示这个是class 文件,Jvm才识别。
次版本号:0000
主版本号:0034
常量池数量:0021 就是2*16 + 1 33个常量池,但是需要减一,得到32个常量池。
常量池信息:前一个字节是tag 表示常量池的类型: oa 等于10 从常量池结构图可以找到时 constent_Methodref_info 这个类型,后面读取4个字节 00 0600 12;
00 06 表示constent_class_info的索引项;00 12 表示constent_nameAndType_info 名称和类型描述符的索引项,一次解析32个常量池。
特殊说明: 01类型的常量池,需要根据length 的长度动态解析。 比如 tag : 01 length : 0006 字符串:3c69 6e69 743e。
类的控制访问权限:0021 表示:0020加0001组合,说明是...和public 。
类名:0005 间接引用常量池第5个常量池
父类名:0006 间接引用常量池第6个常量池
接口数量:0001 实现一个接口。
接口数组:0007 指向常量池 第7个常量池,如果接口数量为零则不出现。
成员变量数量:0000 表示没有成员变量。
成员变量数组:如果成员变量数量为零则不占用字节。
方法数量:0002 两个方法,
方法数组:0001:修饰词pubilc;0008:方法名,指向常量池;0009 :描述符,指向常量池 ;0001:code_attributes的数量;
开始解析code_attribute 000a:code_attribute名称,指向常量池;0000 002f :attribute的长度47;0001:max_stack 操作数栈;0001:max_locals 局部变量个数;0000 0005 :code的长度; 2ab7 0001 b1 :code的内容就是操作虚拟机的指令信息; 00 00 :异常信息没有;00 02:表是其他附加信息有两个。
开始解析LineNumberTable_attribute :00 0b:指向常量池,就是指的lineNumberTable;00 0000 06:指的是这个信息的长度;00 01 :line_number_table_length;
00 00:start_pc ; 00 03 :Java这个方法的代码行号。
开始解析LocalVariableTable_attribute 00 0c:额外信息的名字,指向常量池;00 0000 0c:该信息长度;00 01:variable_table 信息的长度;00 00:start_pc;
00 05:长度;000d:指向常量池,局部变量描述符this;00 0e:指向常量池,类信息描述符;
解析方法字节码的过程中init 方法解析完成后,中间出现0000 无法解析,我猜是clinit 方法的解析,但是因为我们写所以使用0000 表示了。
类属性数量:
类属性数组:0001:第一次属性; 0010:指向常量池; 0000:不知道; 0002:第二个属性; 0011:指向常量池。
到此字节码文件全部解析完毕, 中间有一点瑕疵,后续学习中改进。
总结
字节码学习,让我们了解Java底层的实现有巨大的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号