
09 2022 档案
摘要:路径 C:\Windows\System32\drivers\etc\hosts 注意 HDFS可视化界面上如果要下载某一个,必须配置主机和ip的映射关系
阅读全文
摘要:上传,解压 tar -zxvf kafka-eagle-bin-3.0.1.tar.gz cd kafka-eagle-bin-3.0.1 tar -zxvf efak-web-3.0.1-bin.tar.gz mv efak-web-3.0.1 /opt/app/ 配置文件system-confi
阅读全文
摘要:import java.util.Properties import org.apache.spark.SparkConf import org.apache.spark.sql.{SaveMode, SparkSession} object DayFlow { def main(args: Arr
阅读全文
摘要:fileToHdfs.conf文件 #sources别名:r1 a1.sources = r1 #sink别名:k1 a1.sinks = k1 #channel别名:c1 a1.channels = c1 # 定义flume的source数据源 文件 a1.sources.r1.type = ex
阅读全文
摘要:package camera import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession // 摄像异常状态的功能代码 object CameraAbnormality { def main(args: Arr
阅读全文
摘要:pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
摘要:日期模拟 import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import java.util.Random; public class DataUtil { public stat
阅读全文
摘要:读流程 1) HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。 2) 接着Client通过刚才获取到的HRegionSe
阅读全文
摘要:hbase安装完成之后,给我们提供了一个命令行客户端,hbase shell 命名空间有关的命令:namespace组 增删改查 create_namespace "demo" # 创建一个demo的命名空间 drop_namespace "demo" # 删除一个demo的命名空间 list_na
阅读全文
摘要:1. 概述 HBase是基于Hadoop的一个非关系型数据库(NoSQL数据库),HBase存储底层也是基于HDFS存储的。HBase和Hive很像,Hive是数据仓库 2. HBase中的基本概念 NameSpace:类似于关系型数据库的Database,每个命名空间下有多个表 Table:表名
阅读全文
摘要:不需要设置master在哪个节点上,只要在配置了HA模式的Spark集群上,任何一台机器都可以启动Master 需要先启动zookeeper zkServer.sh start 三台节点 [root@node1 conf]# pwd /opt/app/spark-2.3.1/conf [root@n
阅读全文
摘要:1. 上传zookeeper解压: tar -zxvf zookeeper-3.4.5.tar.gz 2. 修改配置文件[三台节点] [node123]# cd /opt/app/data/zookeeper-3.4.5/conf/ [node123]# mv zoo_sample.cfg zoo.
阅读全文
摘要:[123]zkServer.sh start [node123]# tar -xvf kafka_2.11-0.8.2.1.tgz [node123]# cd kafka_2.11-0.8.2.1/config [node123]# vi server.properties { broker.id=
阅读全文
摘要:集群 | node1 | node2 | node3 | | | | | | NameNode | NameNode | | | JournalNode | JournalNode | JournalNode | | DataNode | DataNode | DataNode | | ZK | Z
阅读全文
摘要:Zookeeper集群的正常部署,并启动[三个节点] zkServer.sh start Hadoop集群的正常部署并启动[三个节点] start-dfs.sh start-yarn.sh HBASE高可用搭建 hbase-env.sh export JAVA_HOME=/opt/app/jdk1.
阅读全文
摘要:进程介绍 1. Zkfc(ZKFailoverController)作用: 切换NN状态; 对NN进行心跳保持(监听),当发现NN active异常,会通知Zookeeper,然后ZK重新选举一个新的NN接管,切换成NN active状态; 2. JournalNode NameNode之间共享数据
阅读全文
摘要:背景: 电商网站用户在网站的每次行为都会以日志数据的形式加以记录到日志文件中,其中用户的行为数据日志格式如下:1,2268318,pv,1511544070 黑名单用户的定义规则如下: 如果某一件商品被同一用户在1分钟之内点击超过10次,那么此时这个用户就是当前商品的黑名单用户,我们需要将黑名单用户
阅读全文
摘要: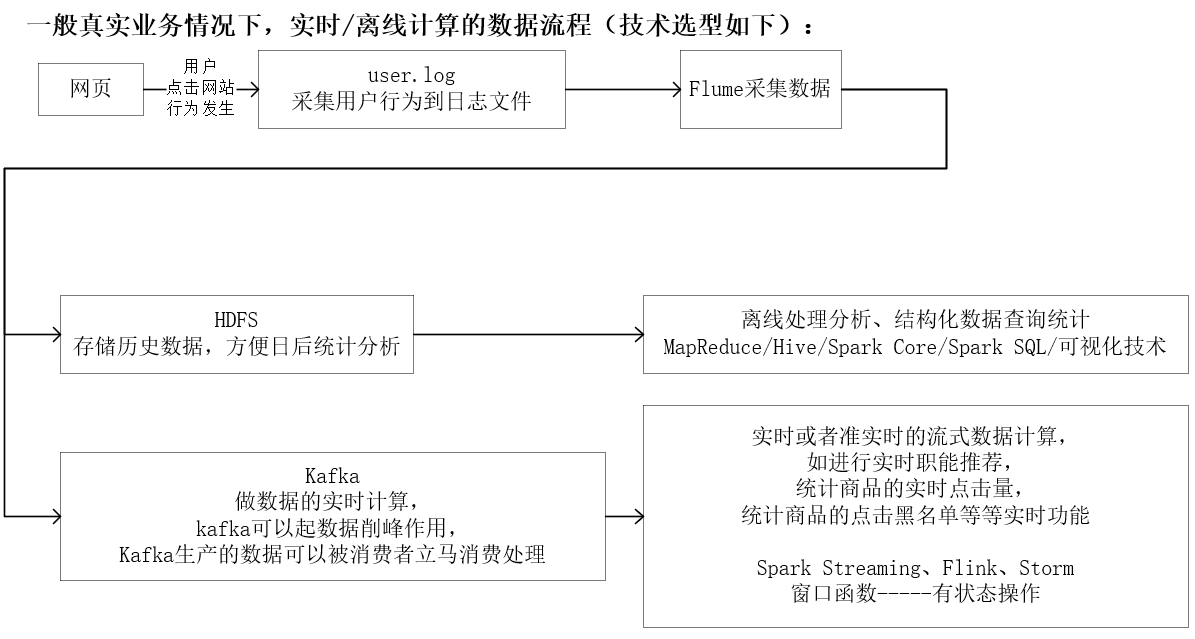
阅读全文
摘要:Spark Streaming只能充当Kafka的消费者 Spark Steaming整合Kafka数据,读取Kafka数据有两种方式 1、Receiver(使用Spark中接受器去处理Kafka的数据)方法 连接zookeeper集群读取数据 仅作了解(被淘汰) 2、Direct方法--直连kaf
阅读全文
摘要:引入pom依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
摘要:1. Kafka充当Flume的source数据源,此时也就意味着Flume需要采集Kafka的数据,Flume相当于是kafka的一个消费者 .conf文件(KafkaToConsole.conf) #sources别名:r1 a1.sources = r1 #sink别名:k1 a1.sinks
阅读全文
摘要:案例要求 /** * 要求将控制台输入的每一行数据发送到Kafka中进行存储 * 输入的每一行数据形式如下 * s001 zs 20 男 * s002 ls 21 女 * 要求将数据发送到我们的kafka的student主题中 同时要求发送的数据以学生编号为key,以学生信息为value形式进行数据
阅读全文
摘要:1. 开启进程 [node123]systemctl stop firewalld [node123]zkServer.sh start [node123]kafka-server-start.sh /opt/app/kafka-0.11.0.0/config/server.properties &
阅读全文
摘要:1. 开启进程 [node123]systemctl stop firewalld [node123]zkServer.sh start [node123]kafka-server-start.sh /opt/app/kafka-0.11.0.0/config/server.properties &
阅读全文
摘要:1. 开启进程 [node123]systemctl stop firewalld [node123]zkServer.sh start [node123]kafka-server-start.sh /opt/app/kafka-0.11.0.0/config/server.properties &
阅读全文
摘要:1. 开启进程 [node123]systemctl stop firewalld [node123]zkServer.sh start [node123]kafka-server-start.sh /opt/app/kafka-0.11.0.0/config/server.properties &
阅读全文
摘要:1. 开启进程 [node123]systemctl stop firewalld [node123]zkServer.sh start [node123]kafka-server-start.sh /opt/app/kafka-0.11.0.0/config/server.properties &
阅读全文
摘要:修改文件 [root@node1 ~]# vi /opt/app/kafka-0.11.0.0/config/server.properties advertised.listeners=PLAINTEXT://192.168.200.111:9092 [root@node2 ~]# vi /opt
阅读全文
摘要:kafka当中,生产者和消费者是有很多不同形式的 |kafka形式|使用场景| | | | |生产者和消费者有kafka自带的|生产者生产的数据是我们在控制台输入的数据| |我们也可以通过Java API自己编写生产者和消费者|自定义生产者生产的数据类型| |kafka也可以结合一些其他技术框架Fl
阅读全文
摘要:1. kafka是apache开源的消息队列 2. 消息队列有什么好处? 解耦:在消费者和生产者两端均设置一个相同的接口,两边都实现接口。 防止消费者因为生产者数据量太大,导致访问数据库的次数大大增加,而导致系统崩溃。 削峰,峰值处理能力 顺序保证,每个topic内部是有序的 缓冲:消息队列通过一个
阅读全文
摘要:步骤 创建maven项目 引入zookeeper编程依赖 <dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</ve
阅读全文
摘要:1. 启动zk客户端 zkCli.sh 2. 节点的命令 创建节点命令 create [-s] [-e] 节点路径 节点内容 -s和-e是一个可选项,可以加也可以不加 -s代表的是创建的字节点需不需要带序号,如果加上-s的话,创建的子节点会自动在节点后拼接一个编号 -e代表的是否创建一个临时节点,如
阅读全文
摘要:命令行方式 与主题有关的命令 需要连接上zookeeper集群操作(主题的名字以及分区数据、副本数等属于元数据,元数据是在zookeeper中存储) 查看kafka服务器中有哪些主题 kafka-topics.sh --zookeeper node1:2181 --list 创建一个主题 kafka
阅读全文
摘要:1:查看防火状态 systemctl status firewalld service iptables status 2:暂时关闭防火墙 systemctl stop firewalld service iptables stop 3:永久关闭防火墙 systemctl disable firew
阅读全文
摘要:package SparkSQL.fun.project import org.apache.spark.SparkConf import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregate
阅读全文
摘要:要求:统计每一个商品的四种行为出现次数 案例 package SparkSQL.fun.project import org.apache.spark.SparkConf import org.apache.spark.sql.expressions.{MutableAggregationBuffe
阅读全文
摘要:package SparkSQL.fun.registerfum import org.apache.spark.SparkConf import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggre
阅读全文
摘要:package SparkSQL.fun.registerfum import org.apache.spark.SparkConf import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggre
阅读全文
摘要:package SparkSQL.fun.registerfum import org.apache.spark.SparkConf import org.apache.spark.sql.{Dataset, SparkSession} import scala.beans.BeanProperty
阅读全文
摘要:package SparkSQL.fun import org.apache.spark.SparkConf import org.apache.spark.sql.{Dataset, SparkSession} object PartitionCode { def main(args: Array
阅读全文
摘要:参数 path:路径/login host:www.baidu.com query:username=zs protocol:http协议 package SparkSQL.fun import org.apache.spark.SparkConf import org.apache.spark.s
阅读全文
摘要:package SparkSQL.fun import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession /** * _1 _2 * zs 60-70-90 * ls 70-80-90 * 求zs和ls的总成绩 平
阅读全文
摘要:启动方式 zkCli.sh 通过简单的命令行代码操作zk文件系统 1. ls /路径:查找某一个节点下的子节点 2. get /路径:查询某一个节点的数据值
阅读全文
摘要:1. 第一次启动zk集群 第一次启动的时候,每一个server会根据myid的大小进行投票选举,如果有半数以上的server投票选择了同一个节点,那么这个节点就会成为leader,剩余的节点全部成为follower. 会根据启动顺序和myid选择leader领导者,只有在启动中有半数以上的节点选择了
阅读全文
摘要:zookeeper文件系统组成 zookeeper本质上是文件系统+通知机制组成的 zookeeper文件系统说明 树形的文件系统,在树形文件系统当中,每一个节点就是存储数据的位置,节点同时兼顾了文件和文件夹的功能。 每个节点默认只能存储1MB的数据 虽然说zookeeper中自带了一个文件系统,但
阅读全文
摘要:查看 // 默认是前10条 print(num) 保存数据 一批次产生一个文件 package SparkStreaming.action import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStr
阅读全文
摘要:window 画图理解 说明 countByWindow 对每个滑动窗口的数据执行count操作 reduceByWindow 对每个滑动窗口的数据执行reduce操作 reduceByKeyAndWindow 对每个滑动窗口的数据执行reduceByKey操作 countByValueAndWin
阅读全文
摘要:将之前批次的状态保存, package SparkStreaming.trans import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.stream
阅读全文
摘要:转换算子1 map,flatMap RDD支持的转换算子DStream大部分都是支持的 map、flatMap、filter、distinct、union、join、reduceByKey...... RDD中部分行动算子DStream会当作转换算子使用,算子的执行逻辑是一样的 package Sp
阅读全文
