08 2022 档案
摘要:推送式 将flume采集的数据主动推送给Spark程序,容易导致Spark程序接受数据出问题,推送式整合是基于avro端口下沉地方式完成 引入SparkStreaming和Flume整合的依赖 <dependency> <groupId>org.apache.spark</groupId> <art
阅读全文
摘要:sparkstreaming创建有两种方式 1. 借助SparkConf对象创建 val conf = new SparkConf().setAppName("streamingContext").setMaster("local[4]") /** * streamingcontext第一种创建方式
阅读全文
摘要:端口 // 地址,端口号,级别(将数据存储在所设置的级别中,这里设置级别为spark的内存) val ds: DStream[String] = ssc.socketTextStream("node1", 44444, StorageLevel.MEMORY_ONLY) 读取HDFS中的数据 imp
阅读全文
摘要:安装nc yum install -y nc 说明 -l, --listen Bind and listen for incoming connections -k, --keep-open Accept multiple connections in listen mode 使用 nc -lk 端
阅读全文
摘要:||DataFrame|Dataset| | | | | |创建方式|**1.根据集合或者RDD的隐式函数toDF(列名)创建(需要引入SparkSession的隐式转换函数)2.SparkSession的createDataFrame函数3.外部结构化文件4.外部关系型数据库5.**Hive数据仓
阅读全文
摘要:说明 使用Dataframe相关算子进行转换的来 都需要引入sparksession的隐式转换内容 map算子 将原有的Dataset的每一行数据进行转换 得到一个新的数据类型 就是新的Dataset的类型 flatMap算子 将原有的Dataset的每一行数据进行压扁操作 得到一个集合数据类型 集
阅读全文
摘要:1. 注意 1. 通过外部存储文件创建Dataset,dataset只支持纯文本文件。 2. 虽然说Dataset不支持其他格式的结构化文件,但是可以把结构化文件创建成DataFrame,然后把DataFrame转换Dataset。 3. textFile算子创建出来的Dataset是一个字符串类型
阅读全文
摘要:说明 定义: 底层用到了函数的柯里化,需要传递两个值。 第二个值是一个隐式参数,需要定义一个隐式变量给隐式参数传递值。 隐式变量不需要我们定义 在SparkSession中全部给我们定义好了。 隐式变量是一个编码器Encoder变量 我们只需要导入即可 import session.implicit
阅读全文
摘要:object CreateDatasetByToDs { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("demo01").setMaster("local[*]") val session
阅读全文
摘要:## 修改hdfs-site.xml <property> <name>hive.metastore.warehouse.dir</name> <value>hdfs://node1:9000/user/hive/warehouse</value> <description>location of
阅读全文
摘要:val conf = new SparkConf().setAppName("action").setMaster("local[*]") val session = SparkSession.builder().config(conf).getOrCreate() val seq: Seq[(St
阅读全文
摘要:mapreduce依赖 <properties> <hadoop.version>2.8.5</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifa
阅读全文
摘要:核心语句val rdd1 = dataFrame.rdd package SparkSQL.DataFreamCreate.dataframetordd import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import
阅读全文
摘要:val sparkConf = new SparkConf().setMaster("local[2]").setAppName("tran") val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate() val
阅读全文
摘要:val sparkConf = new SparkConf().setMaster("local[2]").setAppName("tran") val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate() val
阅读全文
摘要:SQL方式 需要将DataFrame注册成为一张临时表,并给临时表起名字,通过SQL语句查询分析DataFrame中数据 局部临时表、全局临时表 [注意]: --1 如果我们注册的是全局表,查询全局表的时候,必须在表名前加上一个数据库的名字global_temp val frame = sessio
阅读全文
摘要:问题描述 一旦使用Spark SQL连接过Hive之后,无法使用Hive自带的命令行工具操作Hive了, 而且HiveServer2服务无法开启了,操作Hive报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop
阅读全文
摘要:默认情况下SparkSession不支持读取Hive中的数据,也不支持操作HQL语法, 如果要读取Hive中的数据,需要开启Hive的支持, 构建sparkSession的时候调用一个函数enableHiveSupport() val sparkConf = new SparkConf().setM
阅读全文
摘要:说明: /* 需要引入依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.18</version> </dependency> */ 代码: objec
阅读全文
摘要:options的多种模式 Option可选操作项 .option("mode", "FAILFAST") // 读取模式 读取模式的常用值有 permissive:当遇到损坏的记录时,将其所有字段设置为 null, dropMalformed:删除格式不正确的行 failFast:遇到格式不正确的数
阅读全文
摘要:题目: /** * 统计每个省份的用户访问量,最终要求将不同省份用户访问量存放到不同的分区中 分区存放规则如下 * 省份是以包含 山 0 * 如果省份包含 海 1 * 其他省份 2 */ 代码: package sparkcorerddexample import org.apache.spark.
阅读全文
摘要:题目描述: /** * 清洗完成的数据中包含一个用户的响应状态码,获取每一种状态码对应的访问量 * 1、读取清洗完成的数据成为RDD[String] * 2、可以把上一步得到的RDD通过map算子转换成一个键值对类型的RDD,以状态码为key 以不同用户的访问日志为value的数据 * 3、键值对类
阅读全文
摘要:题目描述 /** * 用户的行为日志数据清洗过滤 * 网站的独立访客数:一个唯一的IP地址就是一个独立访客 * 1、将用户行为日志数据中的IP地址字段获取到返回一个只包含IP地址的RDD * 2、RDD中重复的IP去重 * 3、RDD中的累加值 */ 案例 object A2DataAnaly {
阅读全文
摘要:从集合中借助createDataFrame函数创建DataFrame createDataFrame(Seq[T]) 列名会自动生成 案例: val dataFrame: DataFrame = session.createDataFrame(Array( ("zs", 20, "男"), ("ls
阅读全文
摘要:方式一:Scala集合创建DataFrame import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} object CreateSparkSession { def main(ar
阅读全文
摘要:创建项目方式和前面一样 pom依赖不一样 无需导入spark_core包,因为spark_sql中包含了spark_core pom.xml文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.or
阅读全文
摘要:1. SparkSQL支持的数据源 Hive Scala内存中数据--集合 支持从RDD读取数据作SQL操作 支持从外部存储文件读取数据json,csv,普通结构文本文件 支持从关系型数据库读取数据处理(MySQL,SQL Server,Oracle) 2. SparkSQL入口 SQLContex
阅读全文
摘要:RDD: 以Person为类型参数,但是Spark框架本身不了解Person类的内部结构。 DataFrame: DataFrame每一行的类型固定为Row, 每一列的值没法直接访问,只有通过解析才能获取各个字段的值。 DataSet: DataFrame也可以叫DataSet[Row],每一行类型
阅读全文
摘要:
阅读全文
摘要:1. 创建RDD数据集 1. 从现有的Scala集合创建RDD数据集 parallelize(Seq, numSlices): 定义: Seq:Array或者List numSlices:代表创建的RDD的分区数,如果没传递,有一个默认值,默认分区就是spark.default.parallelis
阅读全文
摘要:1. 要求 1. 过去用户的行为日志数据中响应状态码大于等于400的数据 2. 并且需要查看一下合法的数据有多少条,不合法的数据有多少条 3. 将处理完成的结果保存到HDFS分布式文件存储系统上 2. 代码:使用自带累加器 /* 180.153.11.130 - - 2018-03-18 11:42
阅读全文
摘要:广播变量有个要求,广播变量是只读的,分区中只能获取广播变量的值,无法更改广播变量的值 优势:节省了磁盘io,数据量越大,效果越明显 使用:直接通过广播变量的.value函数获取广播变量的值 案例 package videovar import org.apache.spark.rdd.RDD imp
阅读全文
摘要:【注意】: 如果要使用Spark自带的Long类型的累加器,直接sc.longAccumulator()获取使用即可,底层累加器会自动注册 但是如果我们想要使用自定义累加器,必须通过SparkContext的register(累加器对象名)显示注册才能使用,否则累加器不生效 累加器对于分区,只写不读
阅读全文
摘要:HighWordCountAccumulator.scala package accumulator import org.apache.spark.util.AccumulatorV2 import scala.collection.mutable /* 继承AccumulatorV2类, 传递两
阅读全文
摘要:1.累加器 object AccCode { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sum") val sc = new Sp
阅读全文
摘要:分区器只有键值对类型的RDD才可以使用分区器去定义分区规则,非键值对类型RDD也有分区,但是数值类型的rdd是均匀分区的,不可把控的 1. HashPartitioner 定义:HashPartitioner 按照key值的hashcode的不同 分到不同分区里面 弊端:可能会造成数据倾斜问题(每一
阅读全文
摘要:1. countByKey 定义:countByKey():scala.collection.Map(K,Long)按照key值计算每一个key出现的总次数 案例: val rdd:RDD[(String,Int)] = sc.makeRDD(Array(("zs",60),("zs",70),("
阅读全文
摘要:定义:combineByKey(createCombiner,mergePart,mergerbine ) combineByKey需要传递三个参数(函数) 1、createCombiner函数 将相同key值的某一个value数据进行一个函数操作,得到一个新的value数据 零值(新的value数
阅读全文
摘要:1. sortByKey 定义:sortByKey([ascending], [numPartitions]) 解释:按照key值对RDD进行排序,返回一个排序完成RDD ascending: boolean(true:升序 false:降序) numPartitions: 分区个数 案例: def
阅读全文
摘要:1. groupByKey 定义:groupByKey([numPartitions])、 解释:只对键值对类型RDD生效,同时返回的是一个新的RDD[(key,Iterator[Value])] 案例: def groupByKeyOper(sc: SparkContext): Unit = {
阅读全文
摘要:1.行动算子介绍 返回的不是一个RDD,而是一个数据值或者集合或者是没有返回 没有行动算子算法,那么无法实现转换算子的执行 2.reduce(fun):T 聚合算子 定义:fun函数类型如下 (T,T)=>T T是RDD的数据集数据的类型 将原先RDD数据集中聚合起来算一个总的结果 sum/coun
阅读全文
摘要:1.map算子 定义: map(fun)函数 解释: 将RDD的每一个元素通过fun函数计算得到一个新的结果,新的结果我们会组合成为一个新的RDD 特别注意:一对一场景下,RDD的每一条数据对应新的RDD的中一条数据 案例: def mapOper(sc: SparkContext): Unit =
阅读全文
摘要:1.启动spark命令 1. start-dfs.sh 2. start-yarn.sh 3. start-spark-all.sh 4. start-history-server.sh 5. spark-shell --master spark://node1:7077
阅读全文
摘要:1. project.flow nodes: - name: dataClean type: command config: command: sh /opt/project/dataClean/dataClean.sh - name: dataAnaly type: command depends
阅读全文
摘要:1. 本地 spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/app/spark-2.3.1/examples/jars/spark-examples_2.11-2.3.1.jar 100 2.
阅读全文
摘要:spark关联hadoop的环境 [root@node1 conf]# pwd /opt/app/spark-2.3.1/conf [root@node1 conf]# vi spark-env.sh HADOOP_CONF_DIR=/opt/app/hadoop-2.8.5/etc/hadoop
阅读全文
摘要:||启动方式|访问端口| |--|--|--| |HDFS|start-dfs.sh|NameNode(9000 API操作;50070 web访问端口)| |||DataNode(50010 dn和nn通信的端口;50075(datanode的web访问端口)| |||snn(50090 snn的
阅读全文
摘要:[root@node1 conf]# pwd /opt/app/spark-2.3.1/conf [root@node1 conf]# mv spark-defaults.conf.template spark-defaults.conf [root@node1 conf]# vi spark-de
阅读全文
摘要:spark伪分布式搭建 # 配置环境 [root@node1 spark-2.3.1]# vi /etc/profile { export SPARK_HOME=/opt/app/spark-2.3.1 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sb
阅读全文
摘要:修改配置文件 [root@node1 conf]# pwd /opt/app/azkaban-3.85.0/web-server/conf [root@node1 conf]# ls azkaban.properties azkaban-users.xml global.properties log
阅读全文
摘要:配置 1. 上传.tgz包 2. 解压 tar -zxvf scala-2.11.12.tgz -C /opt/app/ 3. 配置环境 创建scala项目 添加maven
阅读全文
摘要:编写脚本文件 压缩成zip包,上传至azkaban
阅读全文
摘要:下载azkaban后,得通过自己编译得到jar包 注意:编译需要很长时间,这儿直接获取了 在mysql中执行SQL文件 1、把hive的lib目录下的derby驱动jar包拷贝到web-server,exec-server的lib目录 [root@node1 web-server]# cp /opt
阅读全文
摘要:搜索要找到的内容 输入网址进行搜索 采集完成 点击生成采集设置 采集到本地 进行采集数据 导出数据 导出数据到csc文件 导出数据到mysql中 1. 删除一些字段 2. 删除后的字段 3. 在MySQL中创建表 4. 重新采集数据 5. 采集到数据库中 6. 选择数据库连接信息 7. 配置字段映射
阅读全文
摘要:1. 创建空的maven项目 2. 添加web项目 添加web项目后的结构 3. 配置tomcat 4. 导入jar包来运行servlet 5. pom.xml文件编写 <dependencies> <dependency> <groupId>mysql</groupId> <artifactId>
阅读全文
摘要:创建web项目 显示效果图代码 效果图 步骤 <!DOCTYPE html> <html lang="en"> <!-- head标签有两个作用 1、引入界面需要的插件 js插件 2、设置界面内容的样式css以及页面的标题 --> <head> <meta charset="UTF-8"> <tit
阅读全文
摘要:第一次导入数据 [root@node1 dataExport]# cat export.sh #!/bin/bash echo " 导出age_pvs表数据(覆盖写)程序启动 " sqoop export --connect "jdbc:mysql://node1:3306/project?serv
阅读全文
摘要:数据导出,先创建表 create database project charset "utf8"; use project; create table month_pvs( visit_year varchar(20), visit_month varchar(20), pvs int ); cre
阅读全文
摘要:数据分析指标 1. 基于时间维度(①每月用户的访问指标 ②每天用户的访问指标 ③每小时用户的访问指标) 重写数据 2. 基于用户维度(不同年龄段用户的访问量指标) 重写数据 3. 基于地理维度(每个分区下不同省份用户的访问指标) 追加数据 创建时间维度表及导入数据 /* * 统计分析 */ -- 1
阅读全文
摘要:明细宽表的构建及数据加载 -- 明细宽表 相当于在贴源数据表的基础之上,增加了9个字段,时间字段增加6个,请求字段增加了3个 create external table if not exists web_detail( ipaddr string comment "ip address", vis
阅读全文
摘要:动态分区问题的解决 在dataClean.sh中清洗数据前,创建一个动态时间变量 timeStr=`date -d "yesterday" "+%Y%m%d"` 在dataAnaly.sh中执行 yesterday=`date -d "yesterday" "+%Y%d%m"` hive --hiv
阅读全文
摘要:说明 通过编写mapreduce,来清洗数据 清洗的原始数据格式: 180.153.11.130 - - 2018-03-18 11:42:44 "POST https://www.taobao.com/category/d HTTP/1.1" 200 12901 https://www.taoba
阅读全文
摘要:说明 用户点击页面后数据存储到a.log文件中。(本项目省去了这一步,数据已经在a.log中了) 使用java代码将a.log文件中的数据,写入project.log中。 使用flume采集日志,监控project.log文件内容的变化,将新增的用户的数据写出到hdfs上。 a.log中的现成数据
阅读全文
摘要:说明 source: 2 channel: 1 sink: 1 注意: sink type: avro hostname: node port source type: avro bind: node1 port 画图理解 配置文件 服务器1的配置文件 [root@node1 oneother]#
阅读全文
摘要:说明 source: 3 channel: 2 sink: 2 画图理解 配置文件编写 [root@node1 data]# cat portAndDirAndFileToHDFSAndFlumeAndLogger.conf # 给flume采集进程agent起了一个别名 a1 # 定义flume进
阅读全文
摘要:画图理解 配置文件编写 第一个服务器 [root@node1 one]# cat fileToFlume.conf one.sources = r1 one.sinks = k1 one.channels = c1 one.sources.r1.type = exec one.sources.r1.
阅读全文
摘要:说明 source: 2 channel: 2 sink: 2 配置文件 # 给flume采集进程agent起了一个别名 a1 # 定义flume进程中有几个source 以及每一个source的别名 a1.sources = r1 r2 a1.sinks = k1 k2 a1.channels =
阅读全文
摘要:说明 source: netcat sink: hdfs 脚本编写 # 给flume采集进程agent起了一个别名 a1 # 定义flume进程中有几个source 以及每一个source的别名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 定义f
阅读全文
摘要:对应关系 在一个Flume进程中,source、channel、sink的关系是:1个source可以绑定多个channel,一个channel只能绑定1个sink。 source和channel是一对多的关系,sink和channel是一对一的关系。 source spooldir和exec的ta
阅读全文
摘要:说明 数据源:exec,这里命令是tail -F 目的地/下沉地:flume日志 编写脚本 # 给flume采集进程起一个别名 a1 # 定义flume进程中有几个source、sink、channel,以及每一个source的别名 a1.sources = r1 a1.sinks = k1 a1.
阅读全文
摘要:编写脚本 [root@node1 data]# cat dirandportToLogger.conf # 给flume采集进程起一个别名 a1 # 定义flume进程中有几个source、sink、channel,以及每一个source的别名 a1.sources = r1 r2 a1.sinks
阅读全文
摘要:案例说明 source:spooling directory Source 监控指定目录内数据变更 编写脚本 # 给flume采集进程起一个别名 a1 # 定义flume进程中有几个source、sink、channel,>以及每一个source的别名 a1.sources = r1 a1.sink
阅读全文
摘要:案例说明 数据源:netcat source 目的地:logger Sink source:netcat,host,post channel:基于内存的缓冲池 memory sink:logger 配置文件 [root@node1 data]# vim portToLogger.conf [root
阅读全文
摘要:Flume采集数据的工作图 Flume采集数据的工作流程 Flume配置过程 [root@node1 ~]# pwd /opt/software/ [root@node1 software]# tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /opt/app/
阅读全文
摘要: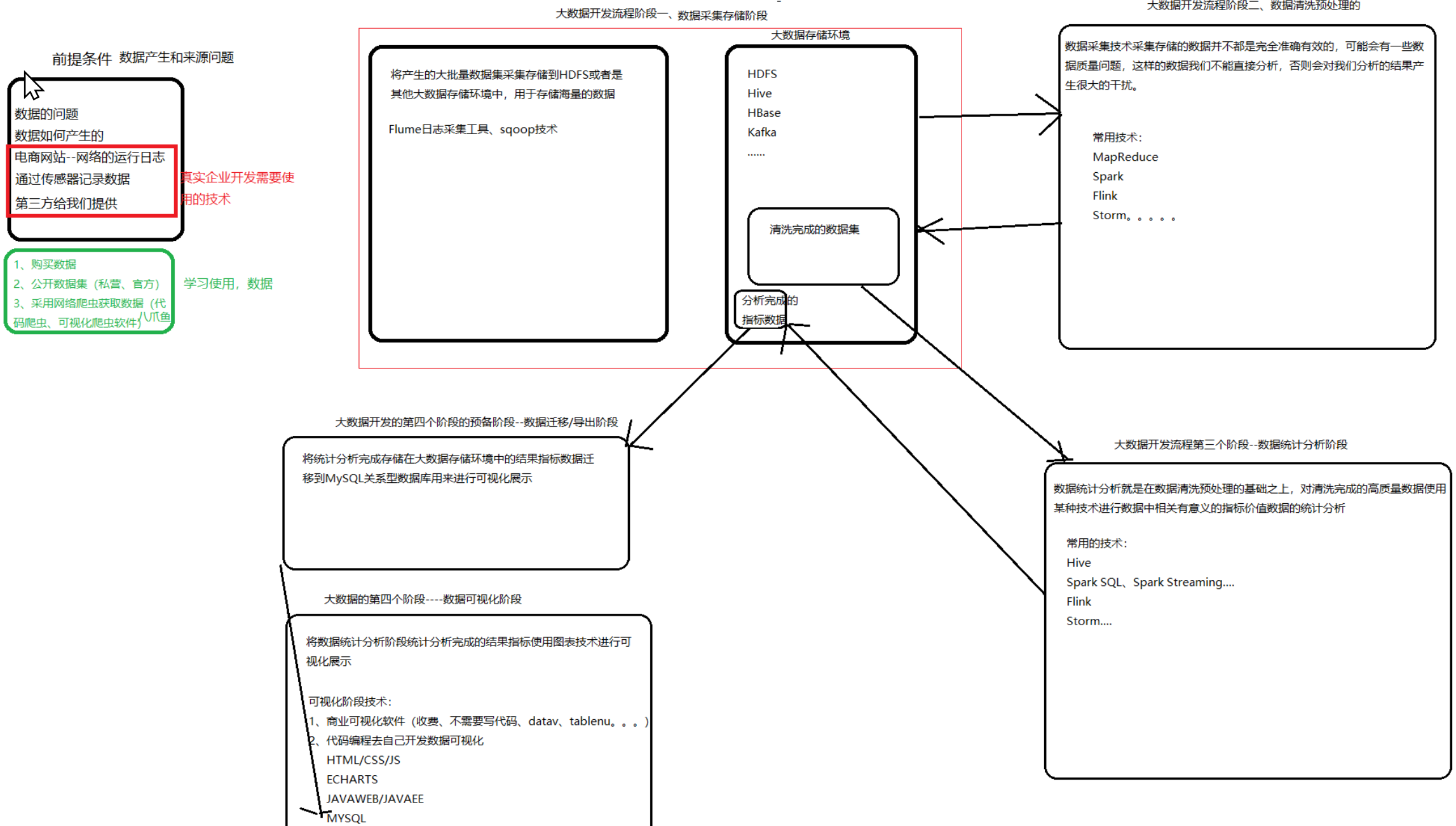
阅读全文
摘要:1. 在mysql中创建表 2. 导入hdfs中 # 将表student导入hdfs中 sqoop import --connect jdbc:mysql://node1:3306/shixun?serverTimezone=UTC --username root --password Jsq123
阅读全文
摘要:配置环境 1. 将jar包上传至/opt/software目录下 2. 解压 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/app/ 3. 改名字 mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.
阅读全文
摘要:pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
摘要:案例要求 java编写 package udtf; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import
阅读全文
摘要:1. 添加maven依赖 一、pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XML
阅读全文
摘要:1. explode炸裂一行的数据 求一个界面的广告数量 page adid page1 1 page1 2 page1 3 page1 4 [root@node1 data]# cat ad.txt page1,1_3_5_9_10_56 page2,30_123_34_7_9_10 page3,
阅读全文
摘要:函数分类 UDF函数:一进一出,length UDAF函数:多进一出,聚合函数:sum、count UDTF函数:一进多出,explode、split 查看函数用法 查看系统自带的函数: show functions; 显示自带的函数的用法: desc functions 函数名; 详细显示自带的函
阅读全文
摘要:hive的执行命令 beeline的使用规则 需要配置hiveserver2 hive的配置文件:hive-site.xml <property> <name>hive.server2.authentication</name> <value>NONE</value> </property> <pr
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号