
Kafka、Flume、SparkStreaming的整合案例(电商网站的黑名单统计)
背景:
电商网站用户在网站的每次行为都会以日志数据的形式加以记录到日志文件中,其中用户的行为数据日志格式如下:1,2268318,pv,1511544070
黑名单用户的定义规则如下:
如果某一件商品被同一用户在1分钟之内点击超过10次,那么此时这个用户就是当前商品的黑名单用户,我们需要将黑名单用户保留下来。
此案例黑名单统计流程,基于实时计算的数据流程(技术选型如下):

用户日志行为数据的获取:
问题:
没有电商网站,无法实现用户点击网站获取到数据的过程,但我们有用户的行为数据,所以通过java程序进行模拟用户的行为,来获取数据

flume采集用户日志行为数据流程
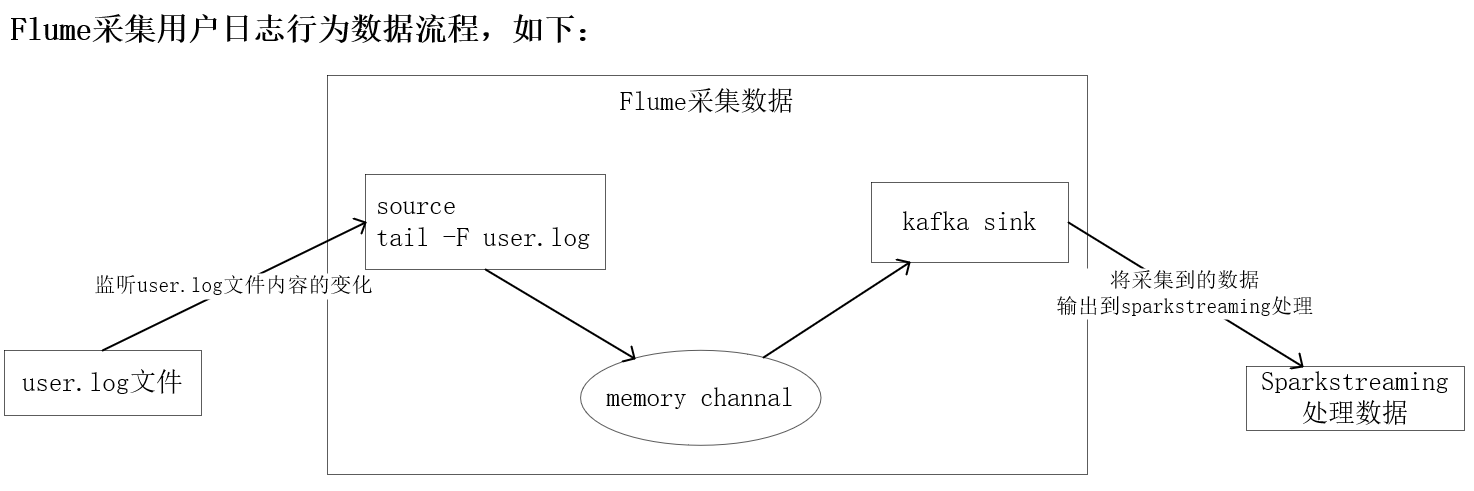
用户日志行为数据获取代码:
import java.io.*; import java.util.Random; public class Simulation { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("/opt/project/b.csv"))); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("/opt/project/user.log", true))); String line = null; Random random = new Random(); while ((line = br.readLine()) != null) { int time = random.nextInt(1000); int count = random.nextInt(10000) + 1; Thread.sleep(time); System.out.println("间隔了"+time+"时间,有"+count+"个用户点击了网站,产生了用户行为日志数据"); for (int i = 0; i < count; i++) { bw.write(line); bw.newLine(); bw.flush(); line = br.readLine(); } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }
flume的config文件
#sources别名:r1 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 定义flume的source数据源 ---exec a1.sources.r1.type = exec # 使用的shell命令 a1.sources.r1.command = tail -F /opt/practice/user.log # 定义flume的channel----memory a1.channels.c1.type = memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity = 5000 # 定义sink----console---logger a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = userlog a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092 a1.sinks.k1.kafka.flumeBatchSize = 200 a1.sinks.k1.kafka.producer.acks = 1 # 整合一个flume进程中channel source sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
使用sparkstreaming进行消费1--key为用户id,value为出现的总次数
import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent object Kafka_SparkStreaming_demo1 { def main(args: Array[String]): Unit = { // 1、创建一个StreamingContext上下文对象 val sparkConf = new SparkConf().setAppName("kafka").setMaster("local[*]") val ssc = new StreamingContext(sparkConf,Seconds(10)) // 2、通过Kafka数据源创建DStream--直连Kafka集群的方式 val topics = Array("userlog") val kafkaParam = Map( "bootstrap.servers" -> "192.168.200.111:9092,192.168.200.112:9092,192.168.200.113:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "spark", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) /** * ds中存放的数据是一个ConsumerRecord消息数据,每一个消息由 * key:null value:1,2333346,2520771,pv,1511561733组成 */ val dStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParam)) /*dStream.foreachRDD((rdd:RDD[ConsumerRecord[String, String]]) => { rdd.foreach((data:ConsumerRecord[String, String]) => { println("sparkstreaming读取处理了一条kafka的数据"+data.key()+data.value()) }) })*/ /** * 统计网站的黑名单用户 * 1、只需要将DStream转换成为以用户id为key 以1为value类型的DStream,然后使用reduceBykeyAndWindow窗口函数计算在1 * 分钟之内每一个用户出现的次数,然后使用filter算子过滤出现次数大于10次的用户 那么此时这个用户就是我们的黑名单用户 * key:null value:1,2333346,2520771,pv,1511561733组成 * 转换如下形式 * key为用户id,value为出现的次数 * key:1 value:1 */ val value: DStream[(String, Long)] = dStream.map((line) => { val str = line.value() val array = str.split(",") (array(0), 1L) }) val value1: DStream[(String, Long)] = value.reduceByKeyAndWindow((a: Long, b: Long)=>{a+b}, Seconds(60), Seconds(60)) // ds3存放的就是一分钟窗口长度内 用户访问量超过10次的用户信息,ds3中数据都是黑名单用户 val value2: DStream[(String, Long)] = value1.filter((tuple2) => { if (tuple2._2 >= 10) { true } else { false } }) value2.print() ssc.start() ssc.awaitTermination() } }
使用sparkstreaming进行消费2--key为商品id,value为出现的总次数,从头至尾
import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka010.{KafkaUtils, LocationStrategies} import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe object Kafka_SparkStreaming_demo2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("demo2").setMaster("local[*]") val ssc = new StreamingContext(conf, Seconds(10)) ssc.checkpoint("I:\\checkpoint") val topics = Array("userlog") val kafkaParam = Map( "bootstrap.servers" -> "192.168.200.111:9092,192.168.200.112:9092,192.168.200.113:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "spark", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) /** * ds中存放的数据是一个ConsumerRecord消息数据,每一个消息由 * key:null value:1,2333346,2520771,pv,1511561733组成 */ val ds:DStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, Subscribe(topics, kafkaParam)) /** * 统计每一个商品出现的次数 * key:商品id value:1L */ val value = ds.map((record) => { val str = record.value() val strings = str.split(",") (strings(1), 1L) }) // updateStateByKey----累加所有批次的数据 val value1 = value.updateStateByKey((array: Seq[Long], total: Option[Long]) => { var num: Long = total.getOrElse(0) for (elem <- array) { num += elem } Option[Long](num) }) value1.print() ssc.start() ssc.awaitTermination() } }
启动
# 开始采集数据 [root@node1 practice]# flume-ng agent -n a1 -f fileToKafka.conf -Dflume.root.logger=INFO,console # 开始模拟生产数据 [root@node1 practice]# javac Simulation.java [root@node1 practice]# java Simulation # 运行java程序
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16669193.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?