spark连接hive后的几个问题
问题描述
一旦使用Spark SQL连接过Hive之后,无法使用Hive自带的命令行工具操作Hive了,
而且HiveServer2服务无法开启了,操作Hive报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
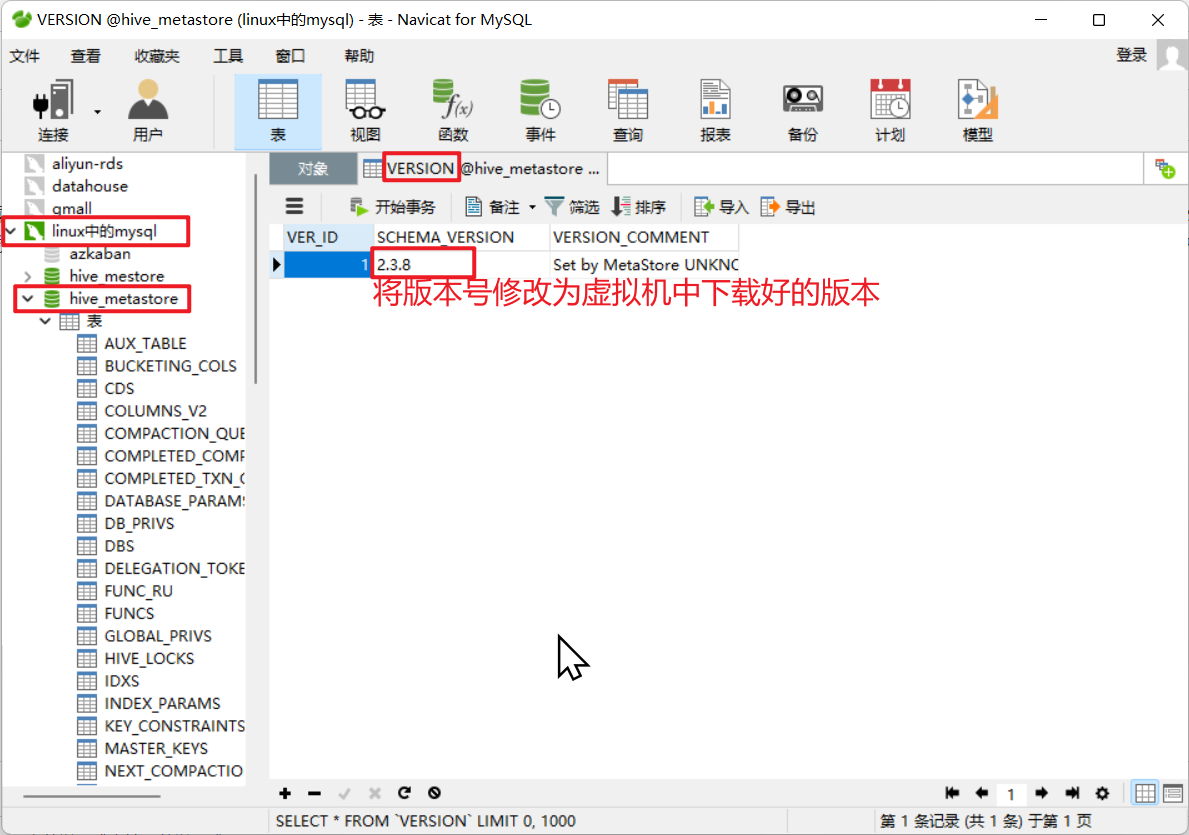
原因是因为Spark SQL连接上Hive元数据库之后,会把Hive的元数据库中的元数据版本号修改为Spark SQL操作Hive的版本1.2.0版本。但是我们的hive是2.3.8版本,元数据库中版本号一旦更改,Hive使用自带命令行或者启动hiveserver2版本对应不上,就无法启动和使用了
问题解决
使用navicat连接工具,将版本号修改为虚拟机中下载好的版本,即可
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16636706.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号