
累加器
1.累加器
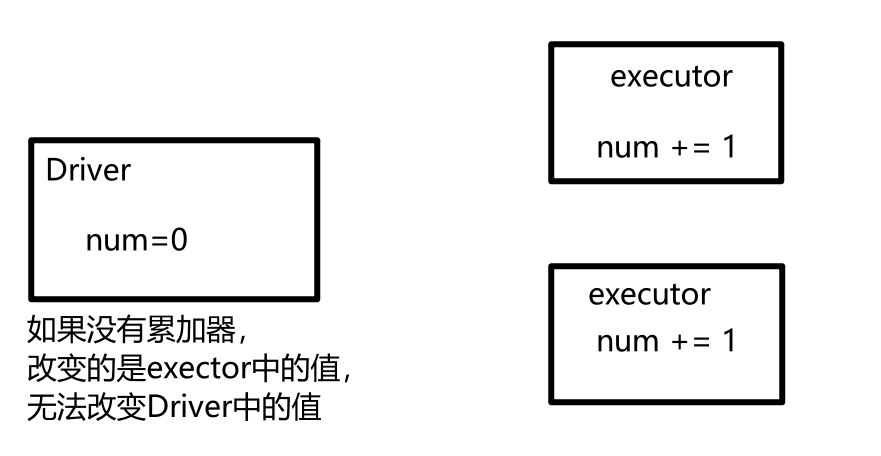
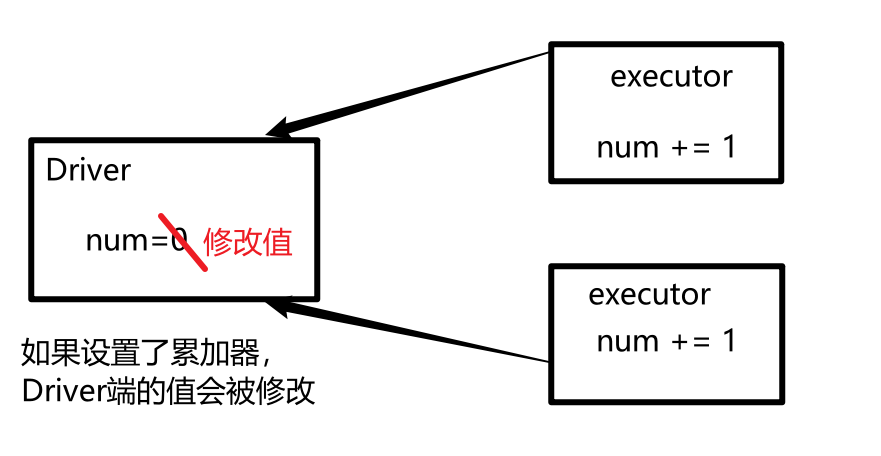
object AccCode {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sum")
val sc = new SparkContext(sparkConf)
val accumulator = sc.longAccumulator("word_seconds")
val rdd:RDD[String] = sc.textFile("hdfs://node1:9000/wc.txt")
val flatmap = rdd.flatMap((line: String) => {
val wordArray = line.split(" ")
accumulator.add(wordArray.length)
wordArray
})
flatmap.collect()
// RDD中一共有 20 个单词
println(s"RDD中一共有 ${accumulator.value} 个单词")
sc.stop()
}
}
2. 自定义累加器
- MyAccumulator.scala
package accumulator
import org.apache.spark.util.AccumulatorV2
/*
继承AccumulatorV2类,
传递两个泛型,第一个泛型代表的是累加器add的时候传递数据类型
第二泛型代表的是累加器最终value给你返回的数据类型
*/
class MyAccumulator extends AccumulatorV2[Int, Int] {
// 自定义的累加器属性 累加器的累加值
var sum: Int = 0
/**
* 判断累加器是否为空的
* @return
*/
override def isZero: Boolean = {
if (sum == 0) {
true
} else {
false
}
}
/**
* 先在每一个分区累加数据
* 将每一个分区累加器的结果复制到driver节点合并,
* 调用copy方法给driver节点传递一个分区累加器
* @return
*/
override def copy(): AccumulatorV2[Int, Int] = {
val myAccumulator = new MyAccumulator()
myAccumulator.sum = sum
myAccumulator
}
/**
* 重置累加器
*/
override def reset(): Unit = {
sum = 0
}
/**
* 每一个分区如果取增加累加器的值
* @param v 累加器输入的类型
*/
override def add(v: Int): Unit = {
sum += v
}
/**
* 核心,每个分区累加器执行完成,
* 最后需要将多个分区累加器的结果合并
* @param other
*/
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
val accumulator = other.asInstanceOf[MyAccumulator]
sum = sum + accumulator.sum
}
/**
* 获取累加的值
* @return
*/
override def value: Int = {
sum
}
}
- AccCode.scala
object AccCode {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("sum")
val sc = new SparkContext(sparkConf)
// val accumulator = sc.longAccumulator("word_seconds")
// 设置自定义累加器
val accumulator = new MyAccumulator()
sc.register(accumulator)
val rdd:RDD[String] = sc.textFile("hdfs://node1:9000/wc.txt")
val flatmap = rdd.flatMap((line: String) => {
val wordArray = line.split(" ")
accumulator.add(wordArray.length)
wordArray
})
flatmap.collect()
// RDD中一共有 20 个单词
println(s"RDD中一共有 ${accumulator.value} 个单词")
sc.stop()
}
}
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16621400.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号