2.清洗数据_项目一
说明
通过编写mapreduce,来清洗数据
清洗的原始数据格式:
180.153.11.130
-
-
2018-03-18 11:42:44
"POST https://www.taobao.com/category/d HTTP/1.1"
200
12901
https://www.taobao.com/category/b
Google Chrome Chromium/Blinkwindows
山西
37.54
112.33
57
清洗完成之后,把字段重新组装 返回我们需要的数据格式
ip,
time,
request_url,
status,
body_bytes,
referer_url,
user_agent,
province,
latitude,
longitude,
age
编写Java代码
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>dataclean</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop.version>2.8.5</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<finalName>dataClean</finalName>
</build>
</project>
编写mapper代码
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// LongWritable:
// Text
// Text: 清洗完成的数据
public class DataCleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
/**
* 1. 获取每一行数据,以空格切割获取每一行日志的字段信息的数据,进行数据清洗
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] array = line.split(" ");
// 1. 判断字段个数是否大于等于16
if (array.length < 16) {
return;
}
// 2. 判断状态码
int status = Integer.parseInt(array[8]);
if (status >= 400) {
return;
}
// 3. 清洗ip 省份 维度 经度不存在的情况
String ipAddr = array[0];
if (ipAddr.contains("-")) {
return;
}
String province = array[array.length - 4];
if (province.contains("-")) {
return;
}
String latitude = array[array.length - 3];
if (latitude.contains("-")) {
return;
}
String longitude = array[array.length - 2];
if (longitude.contains("-")) {
return;
}
String time = array[3] + " " + array[4];
String requestUrl = array[6];
String bodyBytes = array[9];
String refererUrl = array[10];
String userAgent = "";
for (int i = 11; i <= array.length - 5; i++) {
userAgent += array[1];
}
String age = array[array.length - 1];
String result = ipAddr + "," + time + "," + requestUrl + "," + status + "," + bodyBytes + "," + refererUrl + "," + userAgent + "," + province + "," + latitude + "," + longitude + "," + age;
context.write(new Text(result), NullWritable.get());
}
}
编写Driver代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class DataCleanDriver {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node1:9000");
Job job = Job.getInstance();
job.setJarByClass(DataCleanDriver.class);
job.setMapperClass(DataCleanMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
// 为了避免以后处理的数据为所有的数据,只处理当天的数据,使用main方法中的参数即可
// 这里输入路径和输出路径直接定义用户输入
// hadoop -jar xxx.jar 输入路径 输出路径
System.out.println(args[0]);
FileInputFormat.setInputPaths(job, new Path(args[0]));
Path path = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:9000"), conf, "root");
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
在本地测试执行
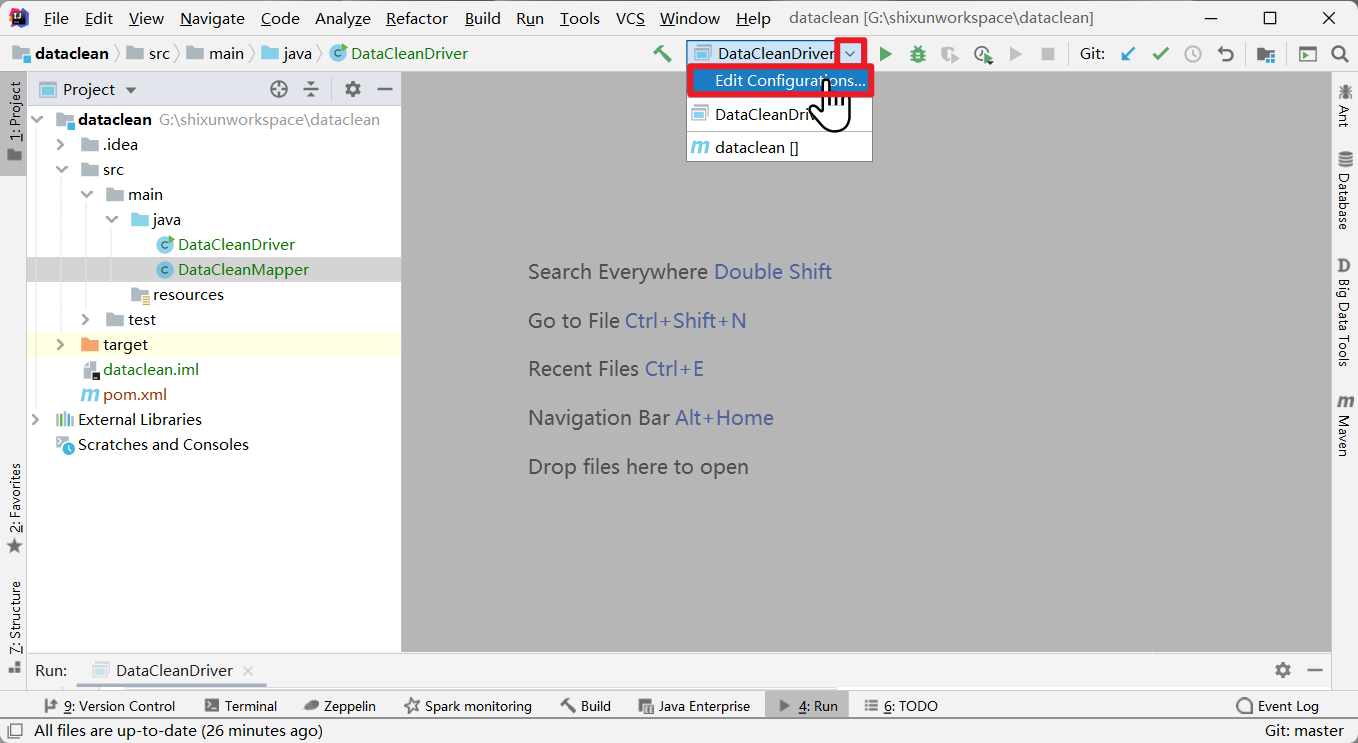
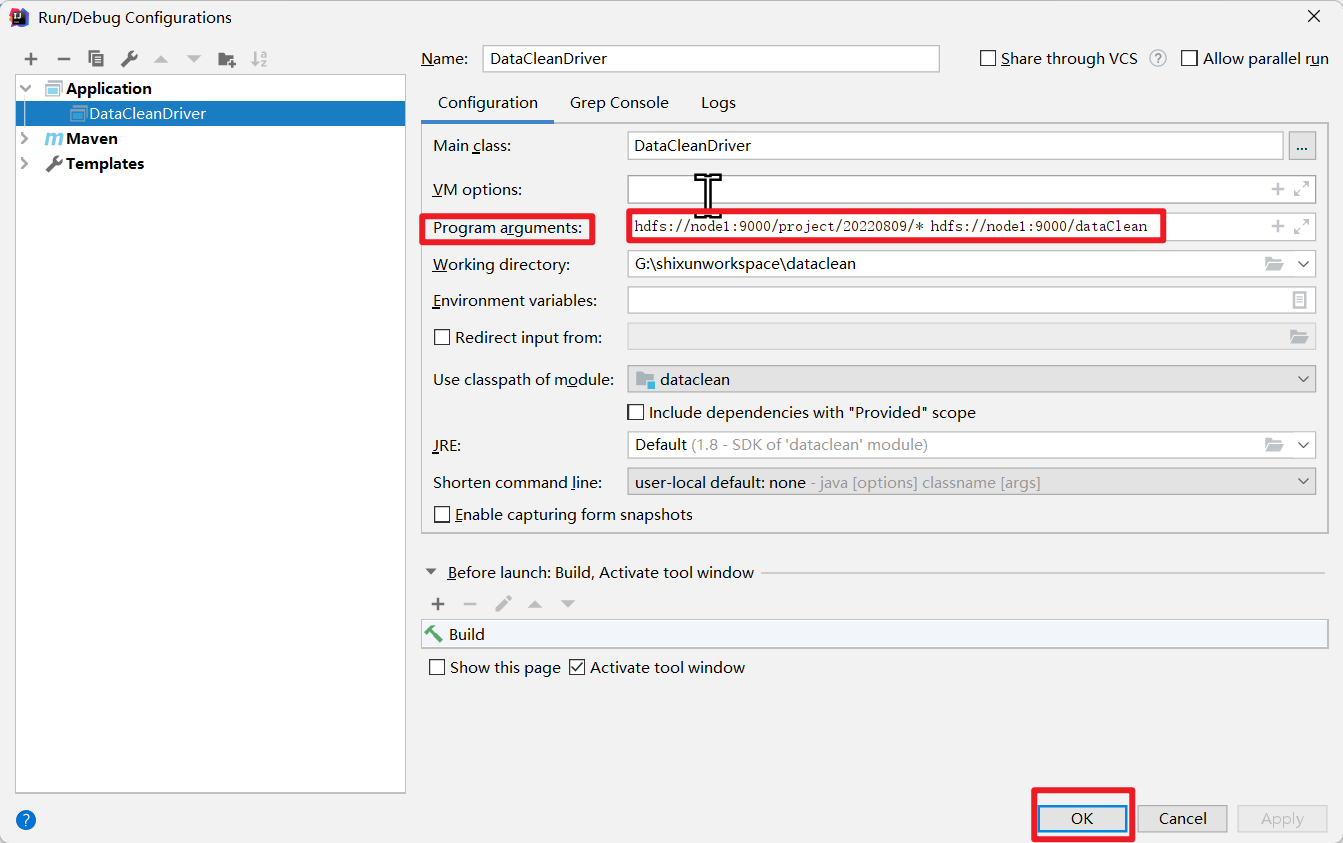
在xshell端通过命令行执行
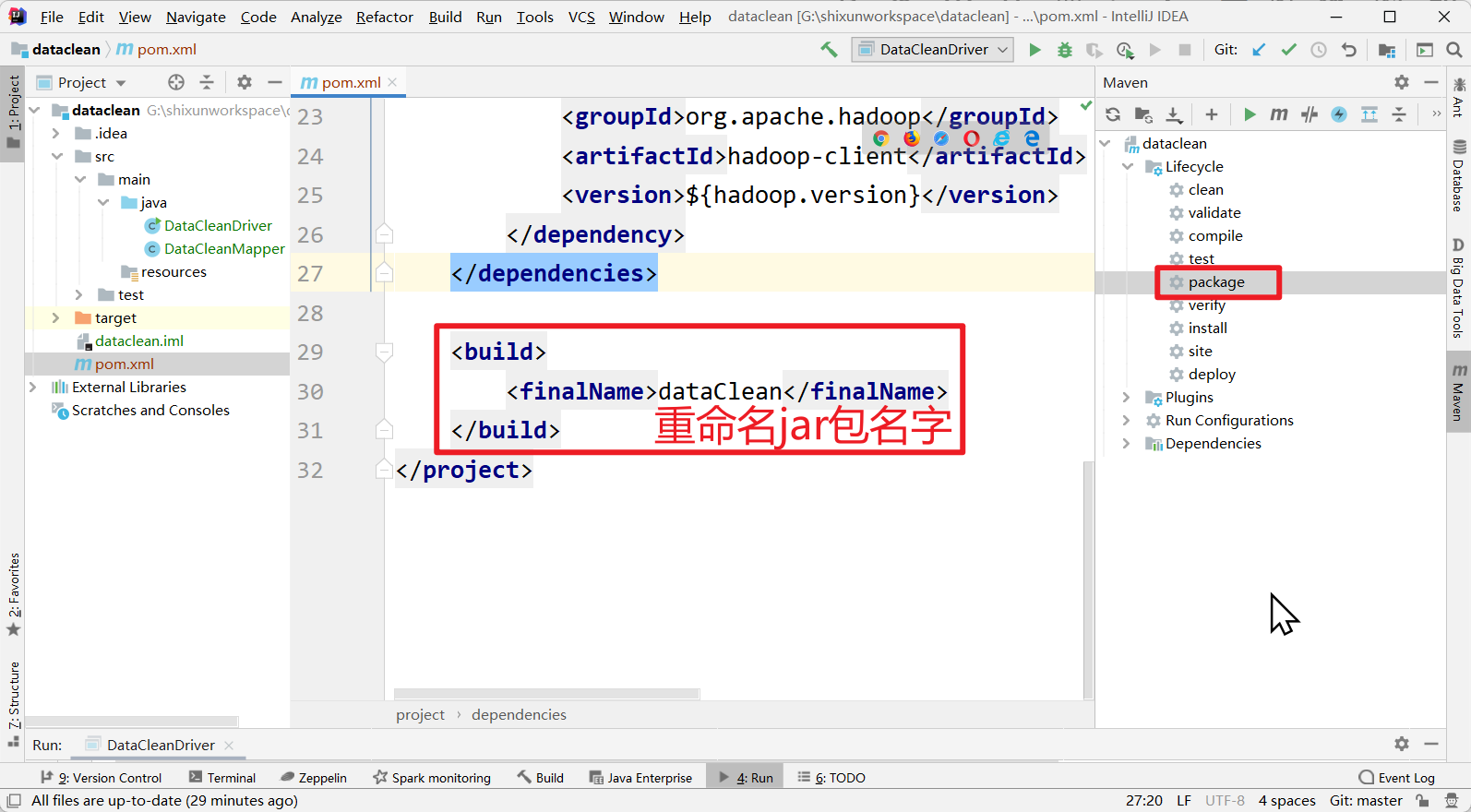
打jar包
上传jar包
执行jar包
hadoop jar /opt/project/dataClean/dataClean.jar DataCleanDriver /project/20220809/* /dataClean
编写shell脚本执行命令,执行脚本即可
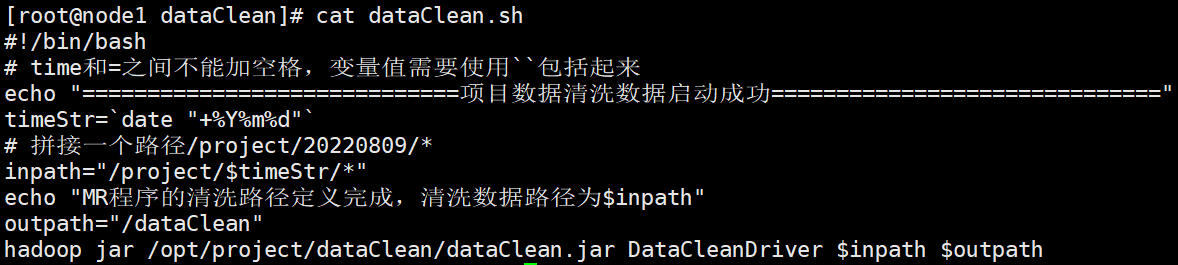
#!/bin/bash
# time和=之间不能加空格,变量值需要使用``包括起来
echo "=============================项目数据清洗数据启动成功=============================="
timeStr=`date "+%Y%m%d"`
# 拼接一个路径/project/20220809/*
inpath="/project/$timeStr/*"
echo "MR程序的清洗路径定义完成,清洗数据路径为$inpath"
outpath="/dataClean"
hadoop jar /opt/project/dataClean/dataClean.jar DataCleanDriver $inpath $outpath
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16565519.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号