案例八:多flume案例
画图理解
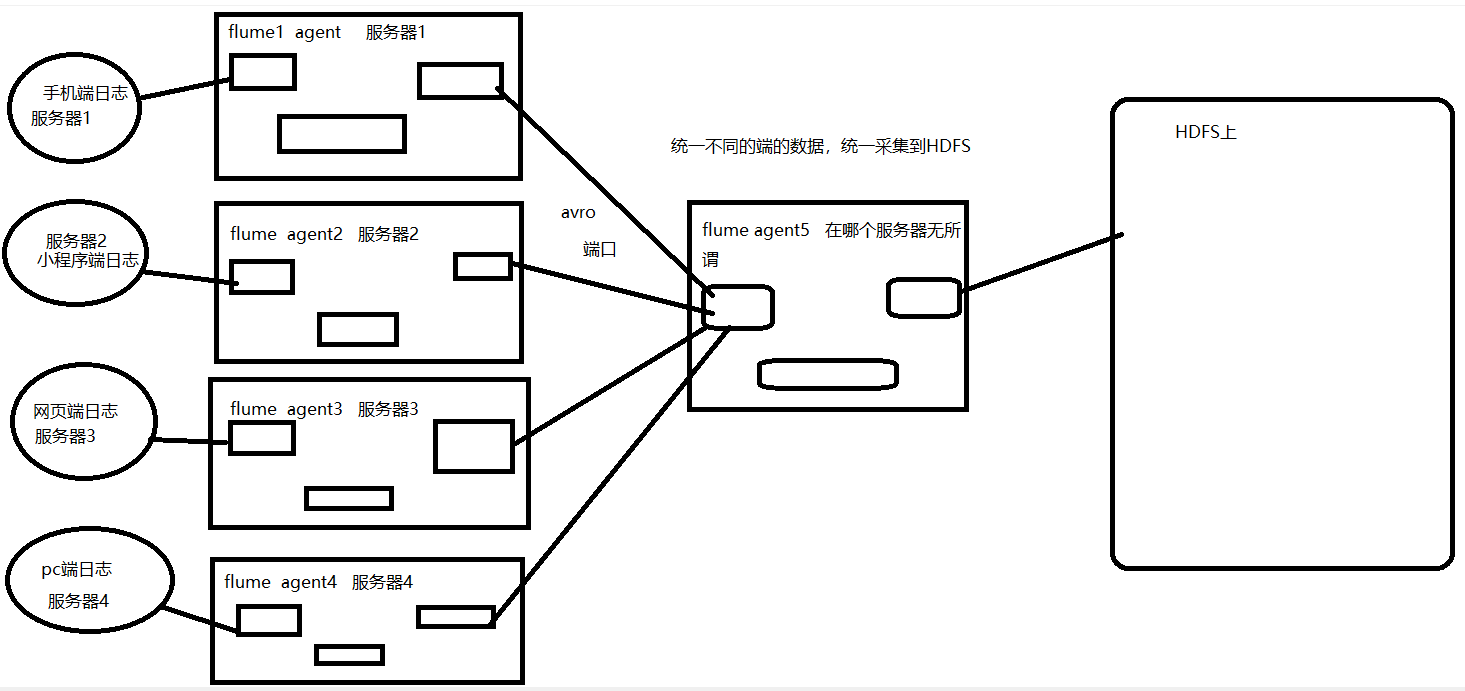
配置文件编写
第一个服务器
[root@node1 one]# cat fileToFlume.conf
one.sources = r1
one.sinks = k1
one.channels = c1
one.sources.r1.type = exec
one.sources.r1.command = tail -F /opt/data/one/one.txt
one.sinks.k1.type = avro
one.sinks.k1.hostname = node1
one.sinks.k1.port = 40000
one.channels.c1.type = memory
one.channels.c1.capacity = 1000
one.channels.c1.transactionCapacity = 100
one.sources.r1.channels = c1
one.sinks.k1.channel = c1
第二个服务器
[root@node1 two]# cat fileToFlume.conf
two.sources = r1
two.sinks = k1
two.channels = c1
two.sources.r1.type = exec
two.sources.r1.command = tail -F /opt/data/two/two.txt
two.sinks.k1.type = avro
two.sinks.k1.hostname = node1
two.sinks.k1.port = 40000
two.channels.c1.type = memory
two.channels.c1.capacity = 1000
two.channels.c1.transactionCapacity = 100
two.sources.r1.channels = c1
two.sinks.k1.channel = c1
聚合服务器
[root@node1 aggre]# cat fileToHdfs.sh
# 给flume采集进程agent起了一个别名 a1
# 定义flume进程中有几个source 以及每一个source的别名
aggre.sources = r1
aggre.sinks = k1
aggre.channels = c1
# 定义flume进程中source连接到数据源信息
aggre.sources.r1.type = avro
aggre.sources.r1.bind = node1
aggre.sources.r1.port = 40000
# sink info
aggre.sinks.k1.type = hdfs
#指定采集的数据存储到HDFS的哪个目录下
aggre.sinks.k1.hdfs.path = hdfs://node1:9000/log/
#上传文件的前缀
aggre.sinks.k1.hdfs.filePrefix = web-
#上传文件的后缀
aggre.sinks.k1.hdfs.fileSuffix = .log
##是否按照时间滚动文件夹
aggre.sinks.k1.hdfs.round = false
##是否使用本地时间戳
aggre.sinks.k1.hdfs.useLocalTimeStamp = true
##积攒多少个Event才flush到HDFS一次
aggre.sinks.k1.hdfs.batchSize = 1000
##设置文件类型,可支持压缩
aggre.sinks.k1.hdfs.fileType = DataStream
##多久生成一个新的文件
aggre.sinks.k1.hdfs.rollInterval = 3600
##设置每个文件的滚动大小
aggre.sinks.k1.hdfs.rollSize = 134217700
##文件的滚动与Event数量无关
aggre.sinks.k1.hdfs.rollCount = 0
##最小冗余数
aggre.sinks.k1.hdfs.minBlockReplicas = 1
aggre.channels.c1.type = memory
aggre.channels.c1.capacity = 1000
aggre.channels.c1.transactionCapacity = 100
aggre.sources.r1.channels = c1
aggre.sinks.k1.channel = c1
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16556660.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号