hadoop中的序列化机制与反序列化机制
定义
- 序列化
就是把内存中的对象,转换成二进制数据,以便于网络传输 - 反序列化
就是将收到的二进制的数据转换成内存中的对象。
java序列化比较笨重,hadoop自己开发了一套序列化机制Writable,比较轻便,好传输
在java中一个对象被序列化后,会附带很多额外的信息,不便于在网络中高效传输
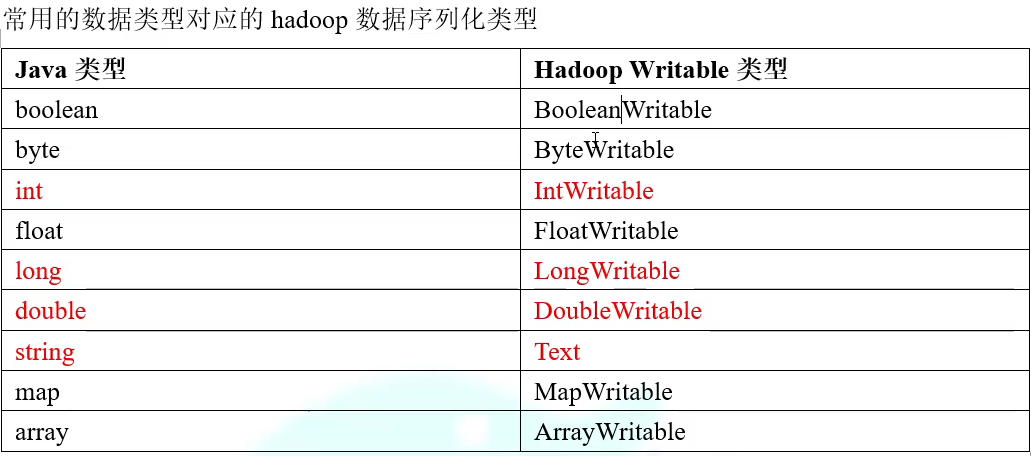
常用的数据序列化类型
自定义一个JavaBean对象充当我们的key-value类型有如下规则:

序列化注意
- Hadoop序列化有要求,如果是我们自定义的JavaBean对象,必须实现writable接口
- JavaBean可以当value也可以当key
如果只当value只需要序列化即可
如果当key必须还要实现比较接口,如果你只当reducer阶段的key不需要比较接口
map阶段输出的数据需要排序,为了让reducer获取数据的时候速度快一点
public class FlowBean implements Writable, Comparable<FlowBean> {
public int compareTo(FlowBean o) {
return 0;
}
}
或者
public class FlowBean implements WritableComparable<FlowBean> {
public int compareTo(FlowBean o) {
return 0;
}
}
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16518229.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号