
复习spark---创建sparksql及跑通读取json
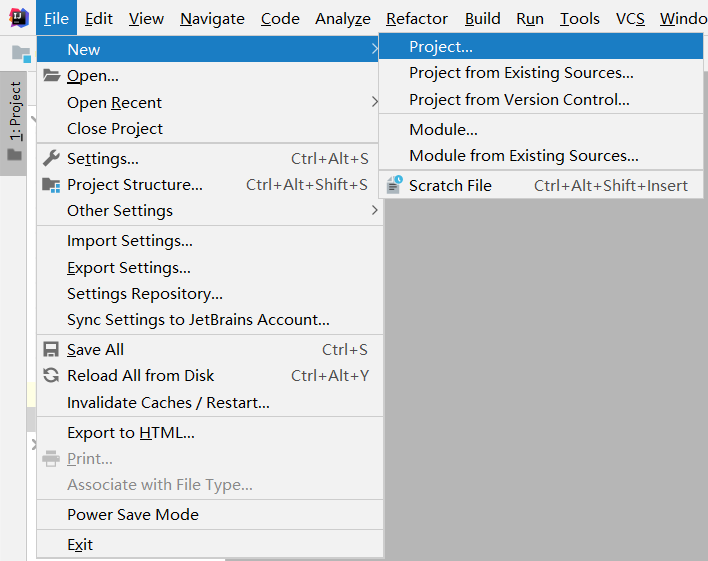
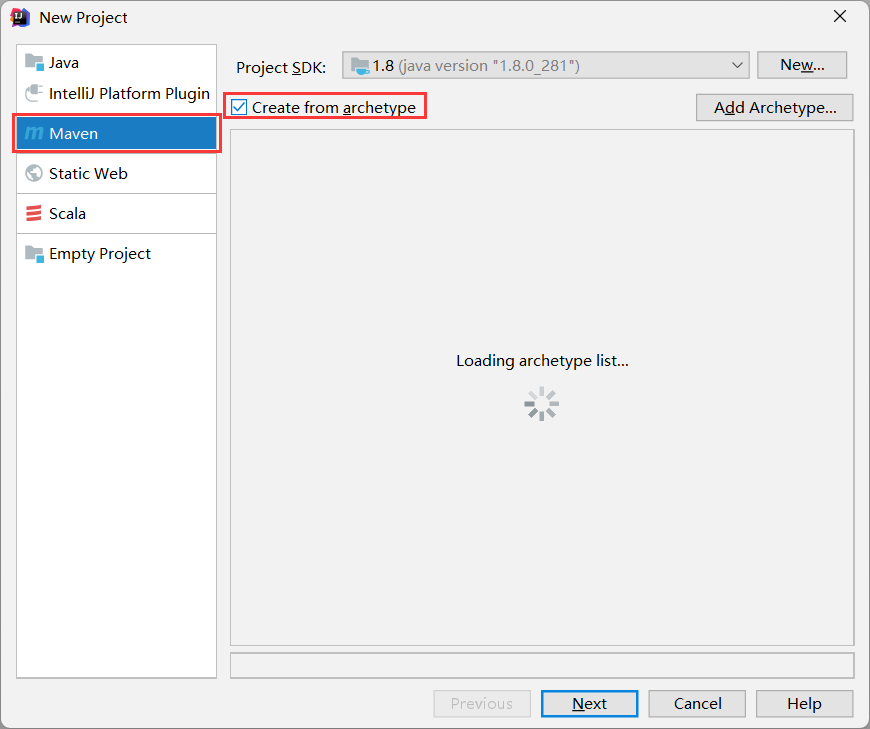
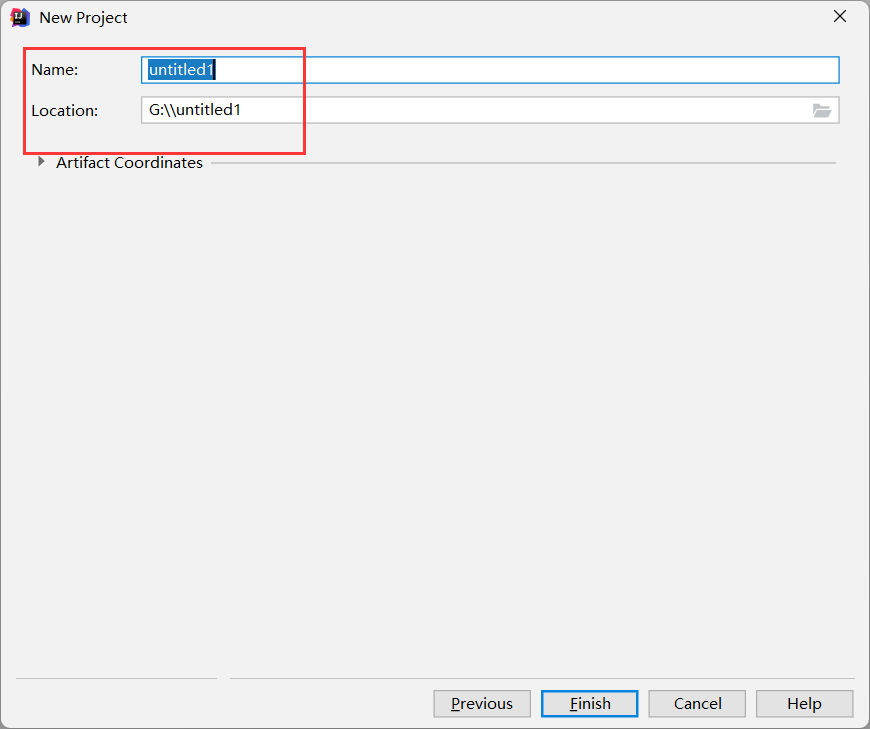
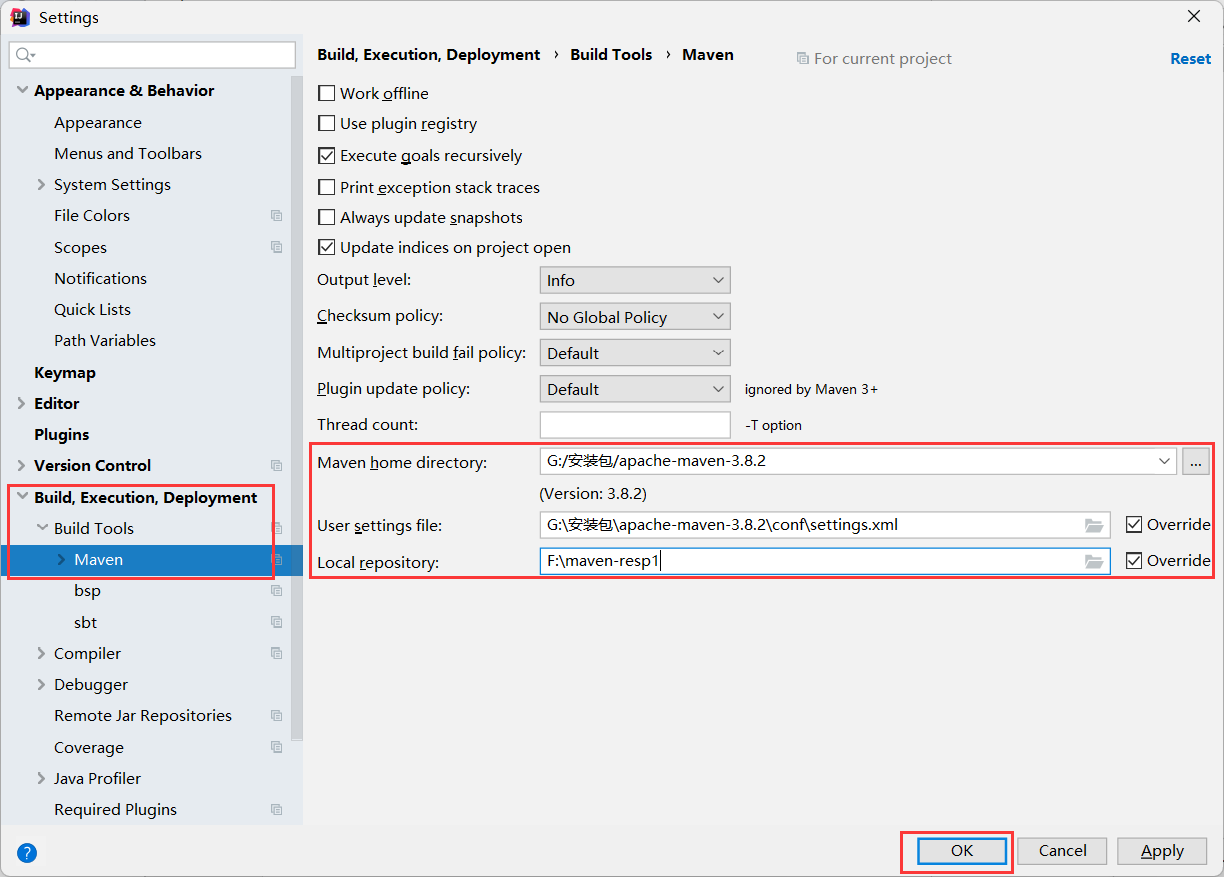
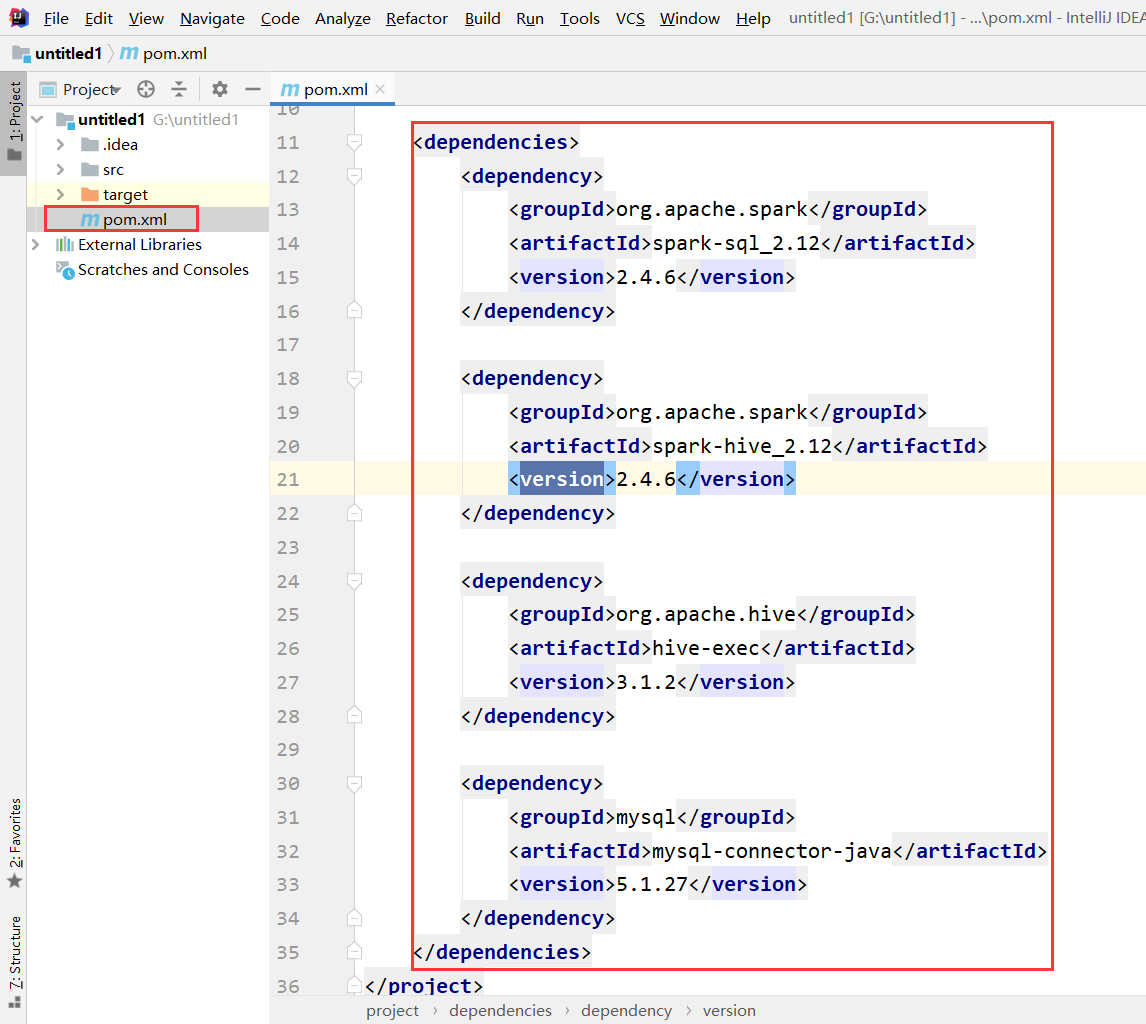
导入依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
</dependencies>
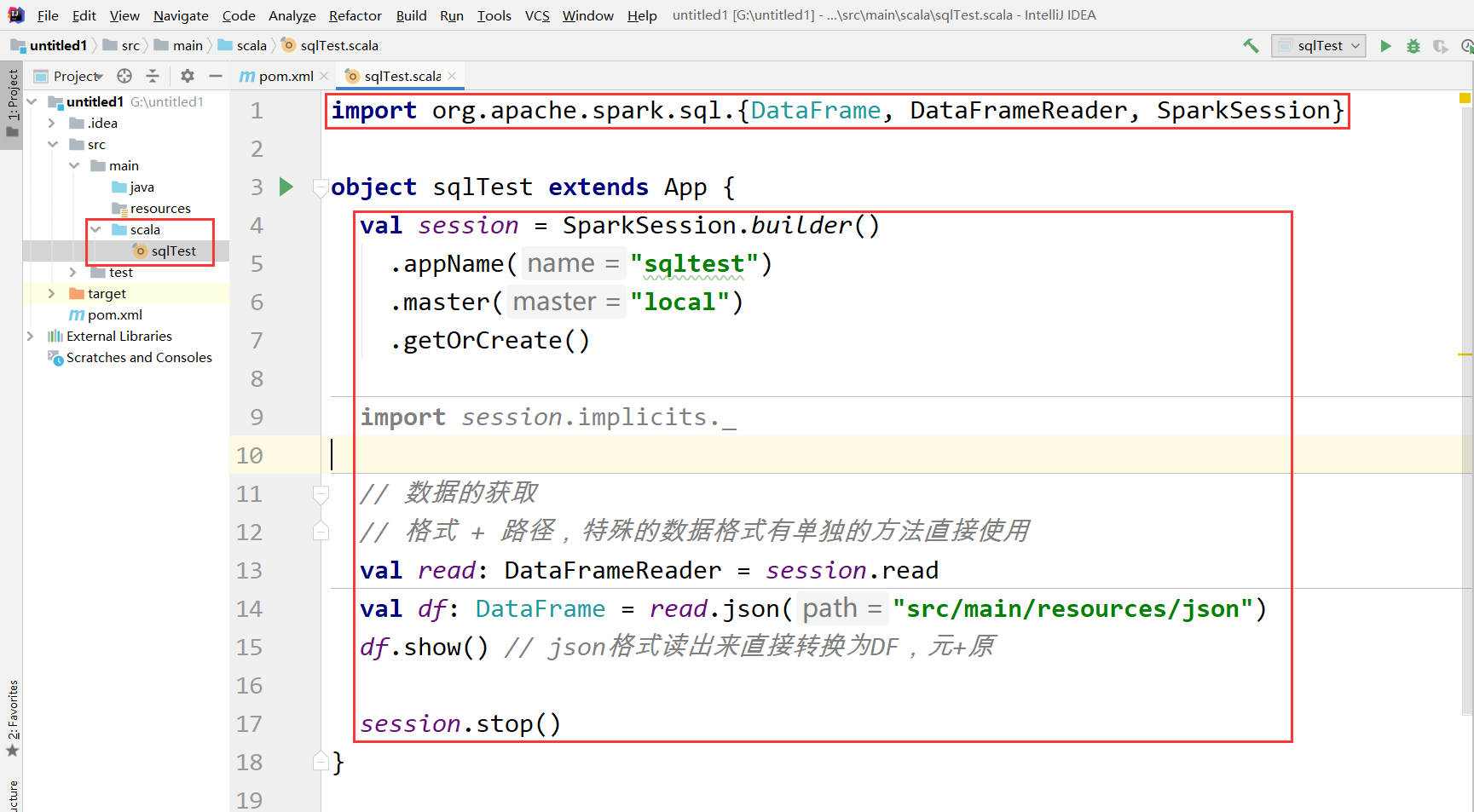
代码
``` import org.apache.spark.sql.{DataFrame, DataFrameReader, SparkSession}object sqlTest extends App {
val session = SparkSession.builder()
.appName("sqltest")
.master("local")
.getOrCreate()
import session.implicits._
// 数据的获取
// 格式 + 路径,特殊的数据格式有单独的方法直接使用
val read: DataFrameReader = session.read
val df: DataFrame = read.json("src/main/resources/json")
df.show() // json格式读出来直接转换为DF,元+原
session.stop()
}
</details>
<details>
<summary>点击查看代码</summary>
{"name":"zhangsan","age":70}
{"name":"lisi"}
{"name":"wangwu","age":18}
{"name":"laoliu","age":28}
{"name":"zhangsan","age":70}
{"name":"lisi"}
{"name":"wangwu","age":18}
{"name":"laoliu","age":28}
{"name":"zhangsan","age":70}
{"name":"lisi"}
</details>本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16144396.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号