知识笔记---sql高级4.索引失效及查询优化
1. 索引失效
(1)全值匹配的情况
(2)最佳左前缀法则:如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列
(3)不在索引列上做任何操作(计算、函数、类型转换),会导致索引失效而转向全表扫描
(4)存储引擎不能使用索引中范围条件右边的列
(5)尽量使用覆盖索引,减少select *
(6)mysql在使用!=的时候无法使用索引会导致全表扫描
(7)is not null也无法使用索引,但是is null是可以使用索引的
(8)like以通配符开头时,mysql索引失效会变成全表扫描
(9)字符串不加单引号索引失效
(10)少用or,用它来连接时索引会失效
(11)where子句中如果出现索引的范围查询会导致order by索引失效
补充
回表
select * from table where name = zhansan;
第一次查询name的B+树,根据name获取到主键id,然后根据id去id的B+树找到记录,这个回表过程会导致IO次数变多。
覆盖索引
select id, name from table where name = zhansan;
在进行检索时,直接根据name去name的B+树获取到id,name两列的值,不需要回表,效率高,应该尽可能多的使用索引覆盖来替代回表,所以有时候,在复杂的sql中,可以考虑将不相关的列都设置为索引列。
最左匹配
有一个表:id,name,age,gender(id是主键,name,age是联合索引)
select * from table where name=? # 符合
select * from table where name=? and age=? # 符合
select * from table where age=? = name=? # 优化器会优化,使其符合最左匹配
select * from table where age=? # 不符合
索引下推
select * from table where name=? and age=?
在没有索引下推之前,先根据name去存储引擎中拉取符合结构的数据,返回到server层,在server层中对age的条件进行过滤
有了索引下推之后,根据name,age两个条件直接从存储引擎中拉去结果,不需要再server层做条件过滤
mysql5.7版本之后默认开启
2. 查询优化
1.小表驱动大表
当A表的数据集小于B表的数据集的时候,用in优于exists
select * from A where id in (select id from B)
等价于
select id from B
select * from A where A.id = B.id
当B表的数据集小于A表的数据集的时候,用exists优于in
select * from A where exists (select 1 from B where B.id = A.id)
等价于
select * from A
select * from B where B.id = A.id
2.order by关键字优化
- MySQL支持二种方式的排序,FileSort和Index。
Index效率高,指MySQL扫描索引本身完成排序。FileSort方式效率较低。 - 尽可能在索引列上完成排序操作,遵照索引键的最佳做前缀
- ORDER BY满足两情况,会使用Index方式排序
ORDER BY 语句使用索引最左前列
使用Where子句与Order BY子句条件列组合满足索引最左前列
设a,b,c为索引
order by能使用索引最左前缀
-ORDER BY a
-ORDER BY a, b
-ORDER BY a, b, c
-ORDER BY a desc, b desc, c desc
如果WHERE使用索引的最左前缀定义为常量,则order by能使用索引
where a = const order by b,c
where a = const and b = const order by c
where a = const and b > const order by b,c
不能使用索引进行排序
order by a asc, b desc, c desc -- 排序不一致
where g = const order by b, c -- 丢失a索引
where a = const order by c -- 丢失b索引
where a = const order by a, d -- d不是索引的一部分
where a in (...) order by b, c -- 对于排序来说,多个相等条件也是范围查询
如果不在索引列上,filesort有两种算法
1.双路排序(又叫回表排序模式)
先根据相应的条件取出相应的排序字段和可以直接定位行数据的行ID,然后在sort buffer中进行排序,排序完后需要再次取回其它需要的字段
举个例子,下面有一段sql:
select * from user where name="自由的辣条" order by age
1.从索引 name 找到第一个满足 name = ‘自由的辣条’ 的主键id
2.根据主键 id 取出整行,把排序字段 age 和主键 id 这两个字段放到 sort buffer(排序缓存) 中
3.从索引 name 取下一个满足 name = ‘自由的辣条’ 记录的主键 id
4.重复 2、3 直到不满足 name = ‘自由的辣条’
5.对sort_buffer中的字段 age 和主键 id 按照字段 age进行排序
6.遍历排序好的 id 和字段 age ,按照 id 的值回到原表中取出 所有字段的值返回给客户端
2.单路排序
是一次性取出满足条件行的所有字段,然后在sort buffer中进行排序
举个例子,下面有一段sql:
select * from user where name="自由的辣条" order by age
1.从索引name找到第一个满足 name = ‘自由的辣条’ 条件的主键 id
2.根据主键 id 取出整行,取出所有字段的值,存入 sort_buffer(排序缓存)中
3.从索引name找到下一个满足 name = ‘自由的辣条’ 条件的主键 id
4.重复步骤 2、3 直到不满足 name = ‘自由的辣条’
5.对 sort_buffer 中的数据按照字段 age 进行排序
6.返回结果给客户端
问题:在sort_buffer中,单路排序比双路排序要多占用很多空间,因为单路排序是把所有字段都取出, 所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取取sort_buffer容量大小,再排……从而多次I/O。本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
优化策略
增大sort_buffer_size参数的设置
增大max_length_for_sort_data参数的设置
3.group by关键字优化
group by实质是先排序后进行分组,遵照索引建的最佳左前缀
当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置
where高于having,能写在where限定的条件就不要去having限定了。
4.关联查询优化
1.保证被驱动表的join字段已经被索引
2.left join 时,选择小表作为驱动表,大表作为被驱动表
3.inner join 时,mysql会自己帮你把小结果集的表选为驱动表
4.子查询尽量不要放在被驱动表,有可能使用不到索引
5.子查询的优化
1.有索引的情况下,用inner join是最好的,其次是in,exists最糟糕
2.无索引的情况下用小表驱动大表,因为join方式需要distinct,没有索引distinct消耗性能较大,所以exists性能最佳,in其次,join性能最差;
3.无索引的情况下,大表驱动小表in 和 exists 的性能应该是接近的,都比较糟糕;
exists稍微好一点, 超不过5%; 但是inner join由于使用了join buffer所以快很多; 如果left join,则最慢;
6.分页查询优化
# 优化前
EXPLAIN SELECT SQL_NO_CACHE * FROM emp
ORDER BY deptno LIMIT 10000,40
# 优化后
EXPLAIN SELECT SQL_NO_CACHE * FROM emp
INNER JOIN
(SELECT id
FROM emp e
ORDER BY deptno
LIMIT 10000,40) a
ON a.id=emp.id
先利用覆盖索引把要取的数据行的主键取到,然后再用这个主键列与数据表做关联(查询的数据量小了)
实践证明:
①order by 后的字段(XXX)有索引
②sql 中有 limit 时, 当 select id 或 XXX字段索引包含字段时 ,显示 using index 当 select 后的字段含有 bouder by 字段索引不包含的字段时,将显示 using filesort
7.去重优化
尽量不要使用distinct关键字去重
group by能去重且利用索引
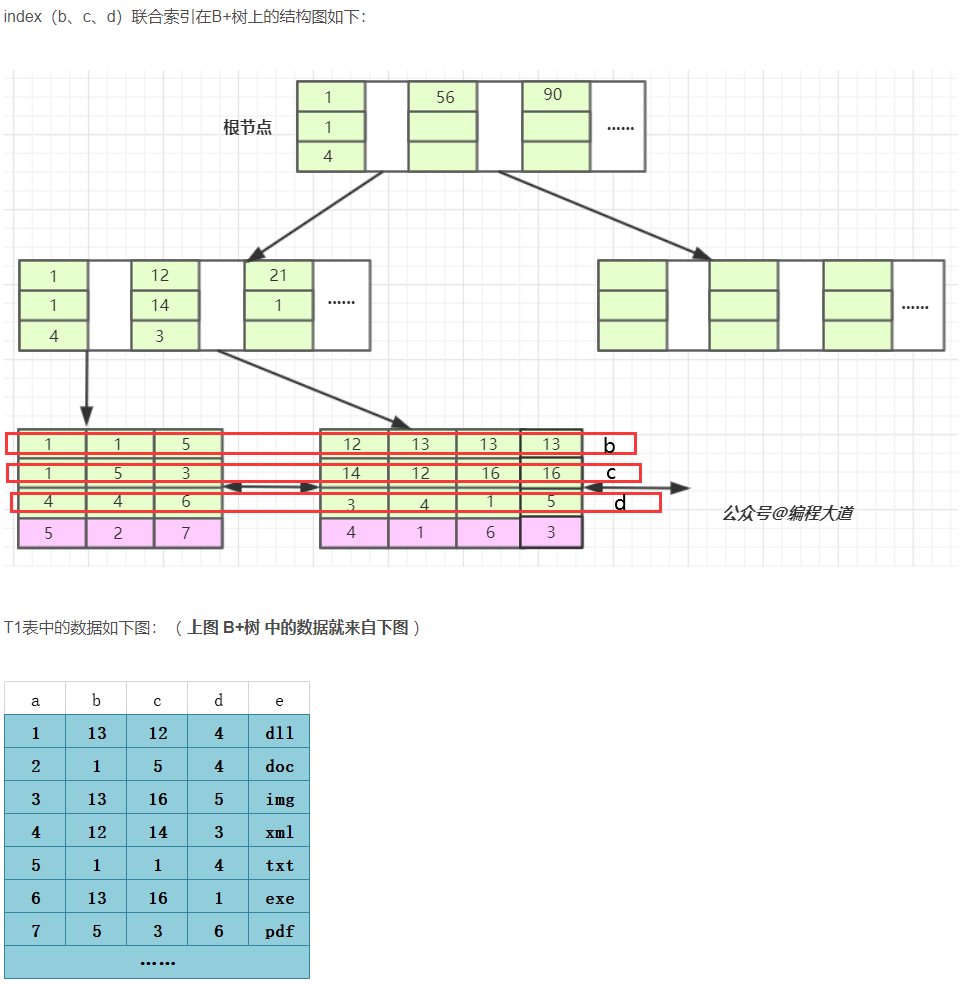
3.关于联合查询补充

本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16084688.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号