
B+树
1.简介
B+树是一颗多路搜索树。
一颗 m 阶的B+树主要特点:
每个结点至多有m个子女
非根结点关键值个数范围: [m/2 - 1, m - 1]
相邻叶子节点是通过指针连起来的,并且是关键字大小排序的。
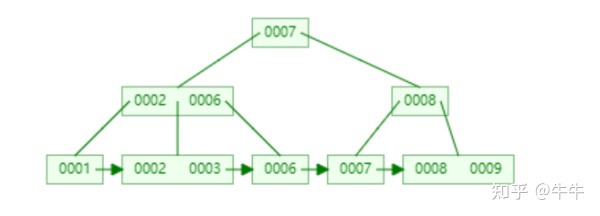
B+树和B树区别:
1. B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
2. B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。
3. B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多个结点中。
2.B+插入

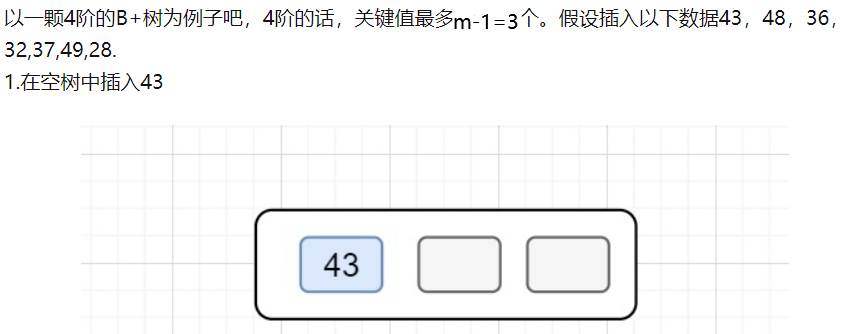
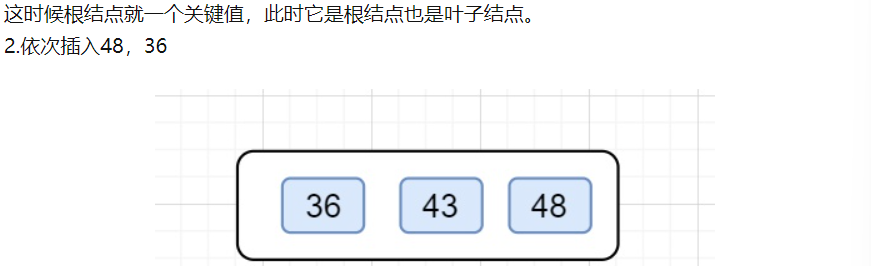
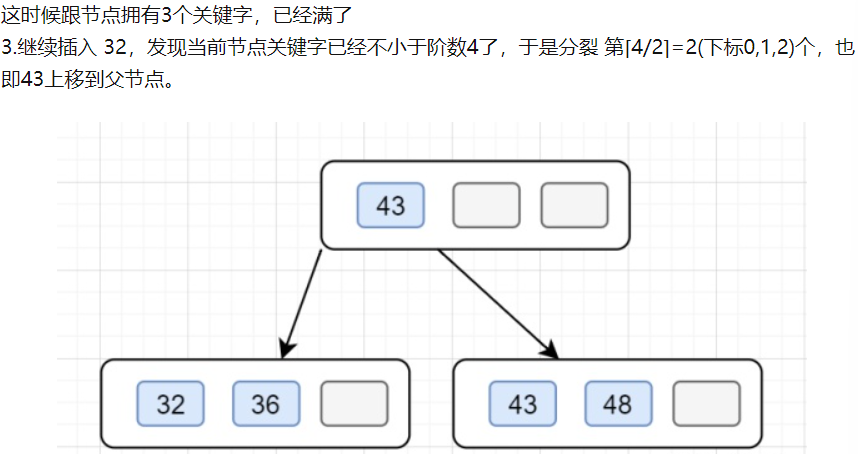
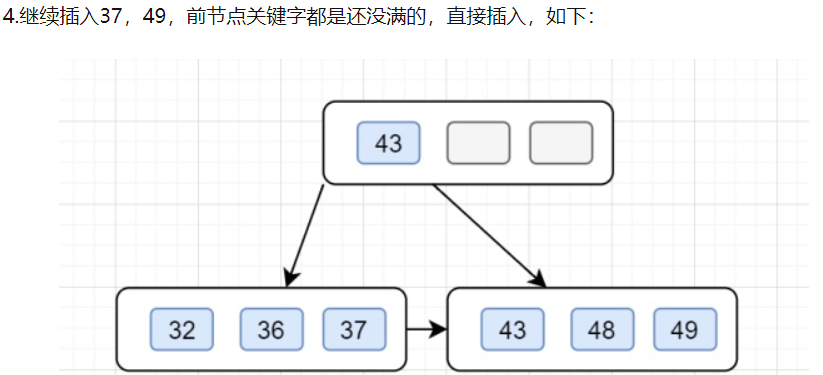
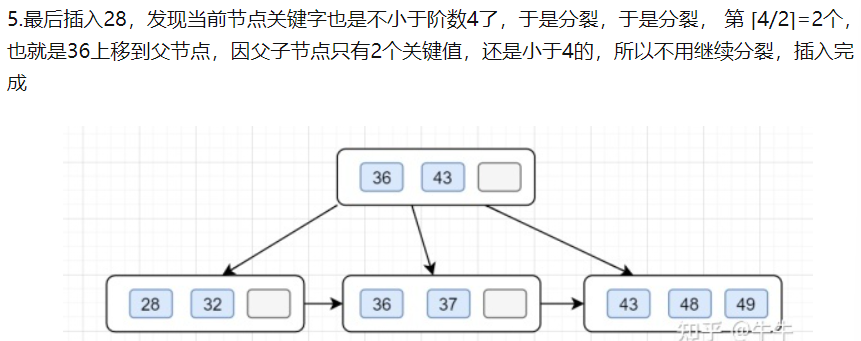
3.B+查找
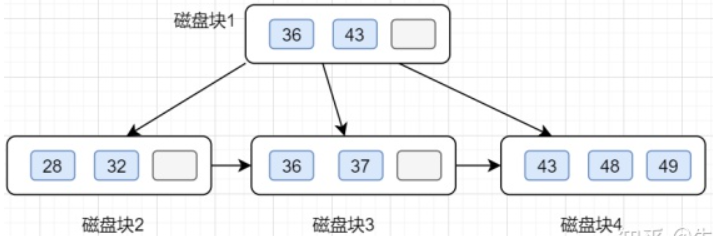
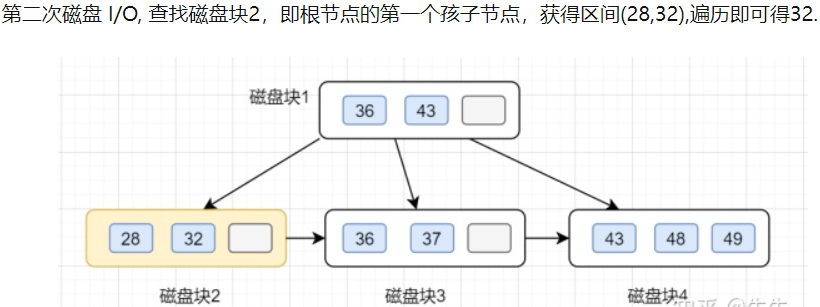
以下面的B+树为例:
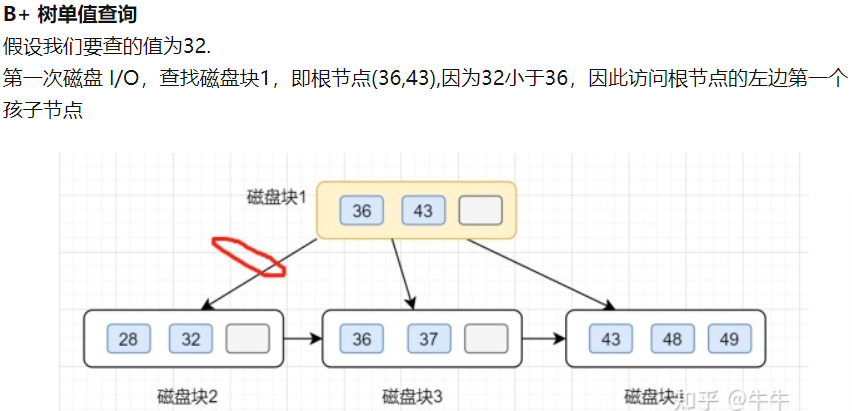
B+树单值查询
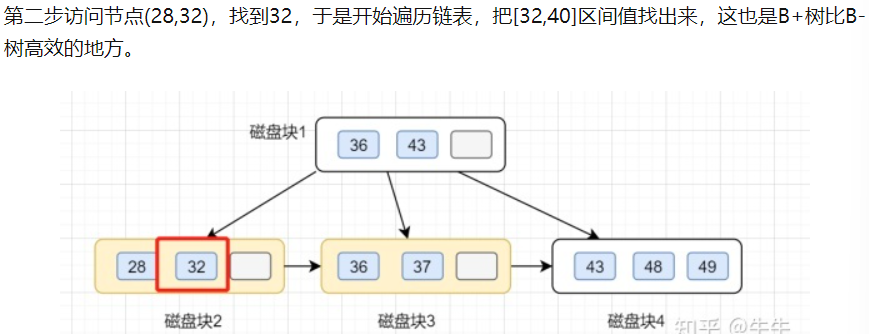
B+树范围查询

4.B+树的删除
几种情况

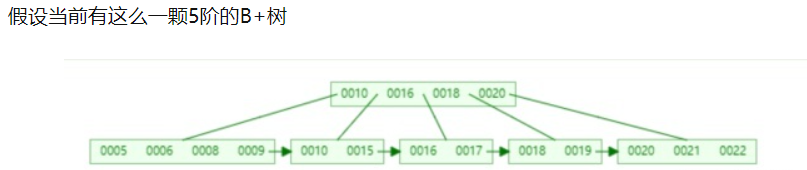
以下面的B+树为例:假设当前有这么一颗5阶的B+树
情况1:如果关键字个数大于⌈m/2⌉,直接删除即可;
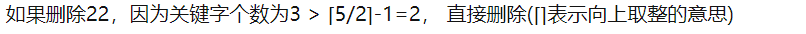
情况2:如果关键字个数大于⌈m/2⌉-1,并且删除的关键字存在于父子节点中,那么需要相应调整父子节点的值
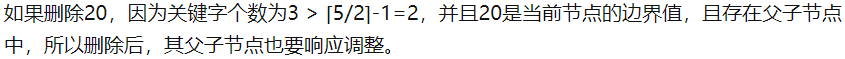


情况3:如果删除该关键字后,关键字个数小于⌈m/2⌉-1,兄弟节点可以借用
以下面5阶的B+树为例
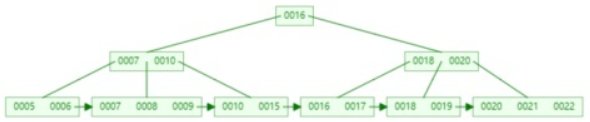

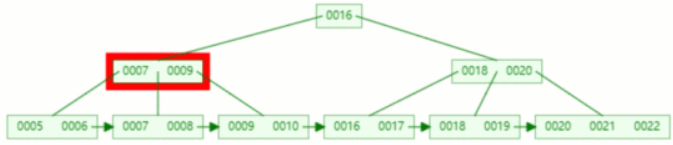
情况4:在删除关键字后,如果导致其结点中关键字个数不足,并且兄弟结点没有得借用的话,需要合并兄弟结点
以下面5阶的B+树为例
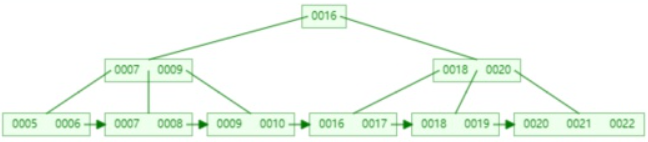



5.经典面试题
1.InnoDB一颗B+树可以存放多少行数据?
2.为什么索引结构默认使用B+树,而不是B-Tree,Hash哈希,二叉树,红黑树?
Hash哈希,只适合等值查询,不适合范围查询。
一般二叉树,可能会特殊化为一个链表,相当于全表扫描。
红黑树,是一种特化的平衡二叉树,MySQL 数据量很大的时候,索引的体积也会很大,内存放不下的而从磁盘读取,树的层次太高的话,读取磁盘的次数就多了。
B-Tree,叶子节点和非叶子节点都保存数据,相同的数据量,B+树更矮壮,也是就说,相同的数据量,B+树数据结构,查询磁盘的次数会更少。
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/16073397.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号