

mapreduce面试题
1.mapreduce核心思想
分而治之,先分后和
- 将一个大的、复杂的工作或任务,拆分成小的任务,并行处理,最终
进行合并 - 适用于大量复杂的、时效性不高的任务处理场景
Map负责数据拆分map:[k1, v1] -> [k2, v2]
Reduce负责数据合并 reduce:[k1, (v1, vn....)] -> [k3, v3]
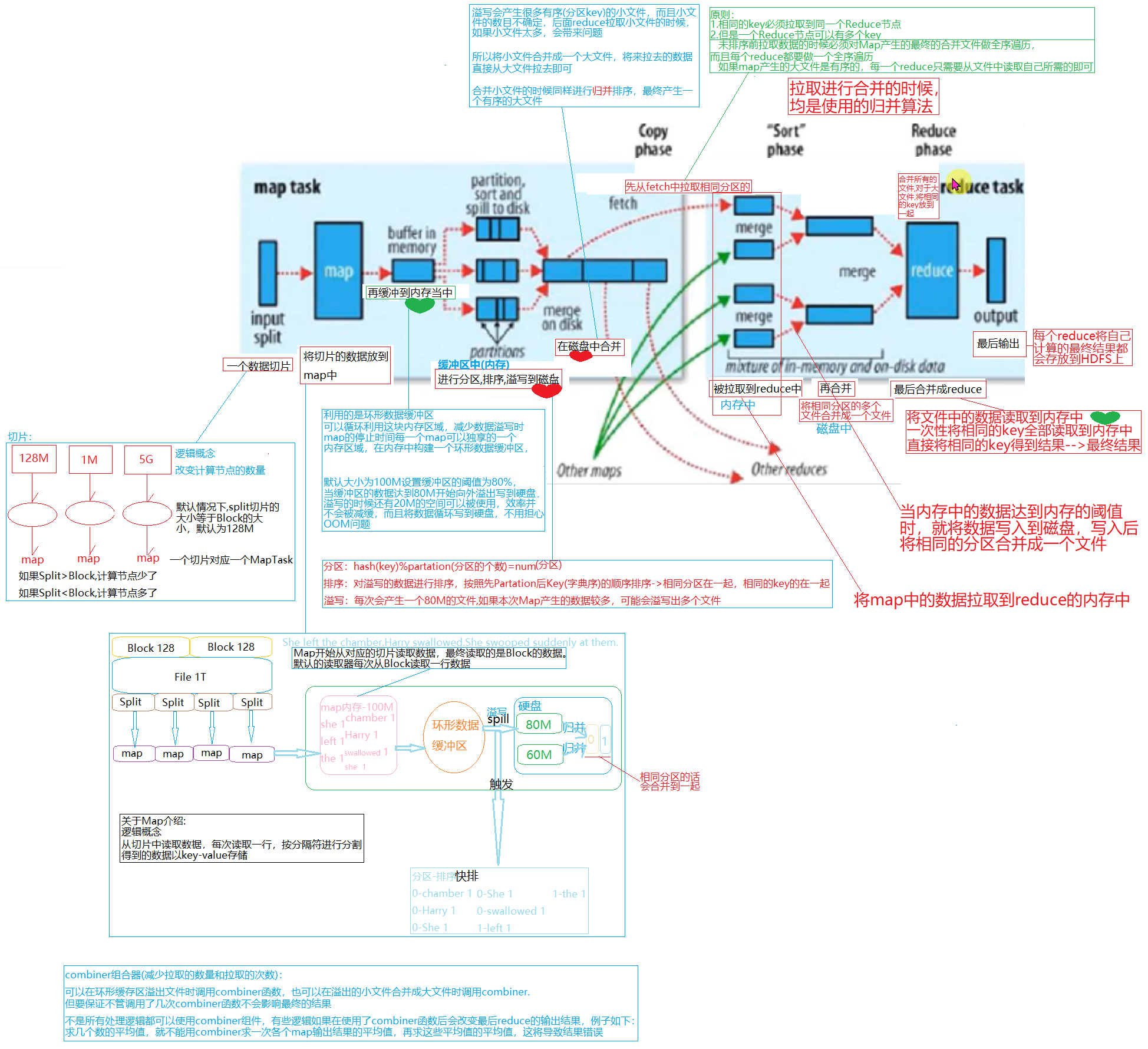
2. shuffle包含哪些步骤
在MR中包括了
(1)collect阶段:将maptask的结果输出到默认大小为100M的环形缓冲区,环形缓冲区保存key/value序列化数据,parition分区信息等。
(2)spill阶段:当环形缓冲区存储的数据达到80%时,就会向磁盘中溢写数据。
在溢写数据之前,会进行排序;如果配置combiner,会对相同的分区和相同的key进行排序。
(3)merge阶段:将所有溢出的临时文件进行一此合并操作,以确保maptask最终只产生一个中间数据文件。
(4)copy阶段:reducetask启动fetcher线程到已经完成Maptask的节点上复制一份属于自己的数据,
这些数据默认保存在自己内存的缓冲区中,当内存的缓冲区达到一定的阈值时,写入磁盘中
(5)merge阶段:在ReduceTask远程复制数据的同时,会在后台启动两个线程(一个是内存到磁盘合并,一个是磁盘到磁盘合并),
对内存到本地的数据文件进行合并
(6)sort阶段:在对数据进行合并的同时,maptask阶段已经对数据的局部进行排序,reducetask只需保证copy数据的最终整体的有效性即可。
3. 如何设置ReduceTask的数量
reducetask的设置:job.setNumReduceTasks(2)
4. combiner组合器
作用
- 减少拉取的数量和拉取的次数
- 可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner
- 但是要保证不管调用了几次combiner函数不会影响最终的结果
- 在map端使用,每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,
以减少在map和reduce节点之间的数据传输量,以提高网络IO性能
什么情况可以使用?什么情况不使用?
- 求平均数的时候不可以使用,因为会改变最终的结果
- 可以在环形缓冲区溢出文件时调用combiner函数(减少拉取的数量),也可以在溢出的小文件合并大文件时调用combiner(减少拉取文件的次数)
5. maptask的数量是可以人为设置的吗?
不可以
6. shuffle阶段的partition分区算法是什么?
对map输出的key取哈希值,hash%reducetask得到分区编号,将key,value放入到对应的分区编号里。
7. Split逻辑切分数据,数据大小是多大?
128M
8. 最优的map效率是什么?
尽量减少环形缓冲区写入写出数据的次数(减少磁盘IO的使用次数)
9. 最优的reduce是什么?
- 尽量减少环形缓冲区写入写出的次数
- 减少磁盘IO的写入写出次数
10. 从内存角度介绍Map的输出到Reduce的输入的过程?
1. Map输出数据到内存
Map输出数据写入到环形缓冲区中,环形缓冲区默认大小为100M,当内存缓冲区达到80%的阈值时,环形缓冲区进行溢写。
在溢写的同时,环形缓冲区仍然有20M未被使用,Map仍然可以往环形缓冲区中写入数据。
当写出的数据个数达到一定量的时候,默认达到4个,对数据进行合并
2. Reduce在Map拷贝数据
Map输出结果写入本地,reduce主动发出copy的进程到Map端拷贝数据。
reduce获取大量数据后,将数据写入内存中,当达到内存的阈值时进行写出。
当写出的个数达到一定的量时,进行合并,最终发送给reduce.
11. 在MapReduce阶段,有哪些优化的点?
- 加大环形缓冲区的内存
- 增大缓冲区阈值的大小(考虑剩余的空间是否够系统使用)
- 对输出的进行压缩(压缩-解压的过程会消耗CPU)
- 设置合理的map和reduce个数,合理设置blocksize
- 使用combiner函数
- 避免出现数据倾斜
- 小文件处理优化:事先合并成大文件
12. 集群优化的核心思路是什么?
在网络带宽、磁盘IO是瓶颈的前提下:
能不使用IO网络就不用,在必须使用的前提下,能少用就少用。
所有的只要能够减少网络带宽的开销,只要能够减少磁盘IO的使用次数的配置项,都是集群调优的可选项。
13. MR从读取数据开始到将最终结果写入HDFS经过哪些步骤
14. MR程序运行的时候会有什么比较常见的问题?
- 如作业中大部分都完成了,但是总有几个reduce一直在运行。
原因:
这是因为这几个reduce中的处理数据要远远大于其他的reduce,可能是对键值对任务划分的不均匀造成的数据倾斜。
解决的方法:
可以在分区的时候重新定义分区规则,对于value数据很多的key可以进行划分、均匀打算等处理,
或者是在map端的combiner中进行数据预处理操作。
15. MapReduce的map数量和reduce数量是由什么决定的?
map数量是由任务提交时,传来的切片信息决定的,切片有多少,map数量就有多少
科普:什么是切片?切片的数量怎么决定? 例子:输入路径中有两个文件,a.txt(130M),b.txt(1M),切片是一块128M,但是不会跨越文件,每个文件单独切片, 所以这个路径提交之后获得的切片数量是3,大小分别是128M,2M,1M。
reduce的数量时可以自己设置的
16. 以Word Count为例, 描述下MapReduce的执行过程.

17. 开发job时,是否可以去掉reduce阶段?
可以,设置reduce数为0即可,job.setNumReduceTask=0
18. 分块与分片的区别?
分片是逻辑概念,分片有冗余。
分块是物理概念,是将数据拆分,无冗余。
19. ResourceManager的工作职责?
- 资源调度
- 资源监视
- Application提交
20. NodeManager的工作职责?
主要是节点上的资源管理,启动Container运行task计算,上报资源,
container情况给RM和任务处理情况给AM。
21. 列举MR中可干预的组件
(1)combine:相当于在map端(每个maptask生成的文件)做了一次reduce
(2)partition分区:默认根据key的hash值%reduce的数量,自定义分区时继承Partition类,重写getPartition()分区方法。
自定义分区可以有效的解决数据倾斜问题。
(3)group:分组,继承WritableCompatator类,重写compare()方法,自定义分组(就是定义reduce输入的数据分组规则)
(4)sort:排序,继承WritableComparable类,重写compareTo()方法,根据自定义的排序方法,将reduce的输出结果进行排序。
(5)分片:可调整客户端的blocksize,minSize,maxSize
22. 现块的大小为128M,现在有一文件大小为260M,进行split的时候,会被分成几片?
2片
原因:1.1的冗余
(
每次切片时,都要判断剩下的部分是否大于块的1.1倍,不大于1.1倍就划分成一块切片
260M = 128M(1块) + 132M(1块)
132M < 128*1.1 = 128+12.8 = 140.8
所以将剩余的132M块只划分成1个切片
)
23. 有个需求,要求一条指令可以把所有文件都shuffle到同一个partition中,用MapReduce的话,你怎么写?
在Driver驱动类中设置reduce数量为1,job.setNumReduceTask(1)
24. mapper的方法关键类
- GenericOptionParser:是为Hadoop框架解析命令行参数的工具类
- InputFormat接口:它的实现类包括:FileInputformat,Composable inputformat等,主要用于输入及切割
- Mapper:将输入的键值对映射成中间数据键值对集合。Maps将输入记录转变为中间记录。
- Reducer:根据key将中间数据集合处理合并成更小的数据结果集。
- Partition:对数据按照key进行分区
- OutputCollector:文件的输出
- Combiner:本地聚合,本地化的reduce
25. mapper的方法有什么?setup,map,cleanup,run
- setup方法:用于管理mapper生命周期中的资源,加载一些初始化的工作,每个job执行一次,setup在完成mapper构造,即将开始执行map动作前执行。
- map方法:主要逻辑编写方法。
- cleanup方法:主要做一些收尾工作,如关闭文件或者执行map()后的键值分发等,每个job执行一次,比较适合来算全局最大值之类的任务。
- run方法执行了上面描述的所有过程,先调用setup方法,然后执行map()方法,最后执行cleanup方法
26. 简列几条MapReduce的调优方法?
MapReduce优化方法主要从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
- 数据输入
(1)合并小文件,在执行MR任务前将小文件进行合并,大量的小文件会产生大量的map任务,增大map任务装载次数,而任务的装载比较耗时,从而导致MR运行较慢
(2)采用combinetextinputformat来作为输入,解决输入端大量小文件的场景 - Map阶段
(1)减少溢写次数,通过调整io.sort.mb及sort.spill.percent参数值,增大触发溢写的内存上限,减少溢写次数,从而减少磁盘IO
(2)减少合并次数,通过调整io.sort.factor参数,增大merge的文件数目,减少merge的次数,从而所见MR处理时间
(3)在map之后,不影响业务逻辑的前提下,先进行combine处理,减少IO - Reduce阶段
(1)合理设置map和reduce的数量,两个数量都不能太少或者太多,太少:会导致task等待事件太长,延长处理时间;
太多:会导致map和reduce任务之间竞争资源,造成处理超时等错误。
(2)设置map和reduce共存,调整,show start completedmaps参数,使map运行到一定程度后,reduce也开始运行,从而减少reduce等待时间。
(3)规避使用reduce,因为reduce在用于连接数据集的时候会产生大量的网络消耗。
(4)合理设置reduce端的buffer,可以通过设置参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销;
MapReduce,Reduce.input.buffer.percent的默认为0.0,当值大于0时,会保留在指定比例的内存读buffer中的数据直接拿给reduce使用 - IO传输
(1)采用数据压缩的方式,减少任务的IO时间
(2)使用seq二进制文件
27. Hadoop中有几个进程,各自的作用是什么?
- NameNode,管理文件系统的元数据的存储,记录文件中各个数据块的位置信息,
负责执行有关文件系统的命名空间的操作,如打开,关闭,重命名文件和目录等,
一个HDFS集群只有一个活跃的namenode,可以有其他从元数据节点 - Secondarynamenode,合并namenode的edit logs到fsimage文件中辅助namenode将内存中的元数据信息持久化
- NodeManager,是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点包括与ResourceManager保持通信,
监督Container的生命周期管理,监控每个Container的资源使用(内存,CPU等)情况,追踪节点健康状况,
管理日志和不同应用程序用到的附属服务(auxiliary service) - DataNode,数据存储节点,保存和检索Block(文件块)负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作
- ResourceManager,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,
它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManger)
RM与每个节点的NodeManager(NMs)和每个应用的ApplicationMaster(AMs)一起工作。
28. 简述Hadoop的调度器。
目前Hadoop有三种比较流行的资源管理器:FIFO,Capacity Scheduler,Fair Scheduler。
目前Hadoop2.7默认使用的是Capacity Scheduler容器调度器。
1. FIFO(先入先出调度器)
Hadoop1.x使用的默认调度器就是FIFO。FIFO采用队列方式将一个一个job任务按照时间先后顺序进行服务。
比如排在最前面的job需要若干maptask和若干reducetask,当发现有空闲的服务器节点就分配给这个job,直到job执行完毕。
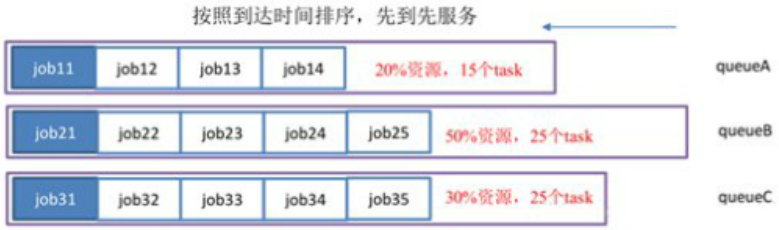
2. Capacity Scheduler(容量调度器)
hadoop2.x使用的默认调度器是Capacity Scheduler
(1)支持多个队列,每个队列可配置一定量的资源,每个采用FIFO的方式调度。
(2)为了防止同一个用户的job任务独占队列中的资源,调度器会对同一用户提交的job任务所占资源进行限制。
(3)分配新的job任务时,首先计算每个队列中正在运行task个数与其队列应该分配的资源量做对比,然后选择比值最小的队列。
(4)其次,按照job任务的优先级和时间顺序,同时要考虑到用户的资源量和内存的限制。对队列中的job任务进行排序执行。
(5)多个队列同时按照任务队列内的先后顺序一次执行。
例如,下图中job11,job21,job31分别在各自队列中顺序比较靠前,三个任务就同时执行。
3. Fair Scheduler(公平调度器)
(1)持多个队列,每个队列可以配置一定资源,每个队列中的job任务公平共享其所在队列的所有资源。
(2)队列中的job任务都是按照优先级分配资源,优先级越高分配的资源越多,但是为了确保公平每个job任务都会分配到资源,
优先级是根据每个job任务的理想获取资源量减去实际获取资源类的差值决定的,差值越大优先级越高。
29. Yarn的job提交流程

1.作业提交
1)client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
2)client向ResourceManager申请一个作业id。
3)ResourceManager给Client返回该job资源的提交路径(HDFS路径)和作业id,每一个作业都有一个唯一的id。
4)Client发送jar包,切片信息和配置文件到指定的资源提交路径。
5)Client提交完资源后,向ResourceManager申请运行MrAppMaster(针对job的ApplicationMaster)。
2.作业初始化
6)当ResourceManager收到Client的请求后,将该job添加到容量调度器(Resource Scheduler)中。
7)某一个空闲的NodeManager领取到该job。
8)该NodeManager创建Container,并产生MrAppMaster。
9)下载Client提交的资源到本地,根据分片信息生成MapTask和ReduceTask。
3.任务分配
10)MrAppMaster向ResourceManager申请运行多个MapTask任务资源。
11)ResourceManager将运行MapTask任务分配给空闲的多个NodeManager,
NodeManager分别领取任务并创建容器(Container)。
4.任务运行
12)MrAppMasterMaster向两个接收任务的NodeManager发送程序启动脚本,
每个接收到任务的NodeManager启动MapTask,MapTask对数据进行数据处理,并分区排序。
13)MrAppMaster等待所有MapTask运行完毕后,向ResourceManager申请容器(Container),运行ReduceTask。
14)程序进行完毕后,MrAppMaster会向ResourceManager申请注销自己。
15)进度和状态更新。YARN中的任务将其进度和状态(包括counter)返回给应用管理器。
客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新,
展示给用户。可以使用YARN WebUI查看任务执行状态。
5.作业完成
除了向应用管理器请求作业进度外,客户端每5分钟都会通过waitForCompletion()来检查作业是否完成。时间间隔可以通过
mapreduce.client.completion.pollinterval来设置。作业完成之后,应用管理器和container会清理工作状态。
作业的信息会被作业历史服务器存储以备之后用户检查。
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/15982493.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通