Hadoop框架高可用配置---HA
1.高可用集群搭建
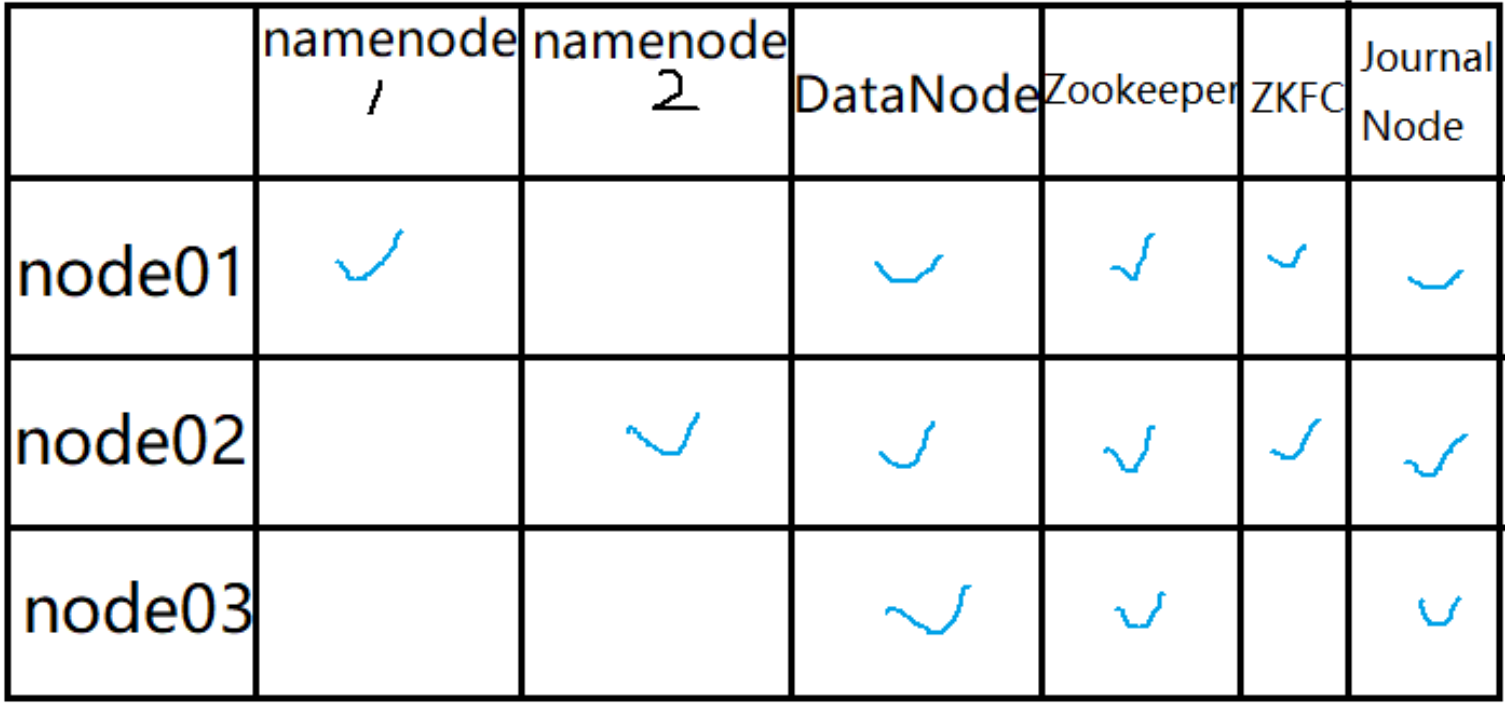
2.准备安装环境
tar -zxvf hadoop-3.1.2.tar.gz
mv hadoop-3.1.2 /opt/
cd /opt/hadoop-3.1.2/etc/hadoop/
3.修改集群环境
vim hadoop-env.sh
# 直接在文件的最后添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_261
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
4.修改配置文件
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://bdp</value> # 集群的名字
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/bdp/hadoop/ha</value> # 存储到linux本地的临时目录
</property>
<property>
<name>hadoop.http.staticuser.user</name> # 登录的用户
<value>root</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> # ha用到的zookeeper的集群地址
<value>node001:2181,node002:2181,node003:2181</value>
</property>
vim hdfs-site.xml
# 关于集群
<property>
<name>dfs.nameservices</name>
<value>bdp</value>
</property>
<property>
<name>dfs.ha.namenodes.bdp</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.bdp.nn1</name>
<value>node001:8020</value> # http连接时的端口和ip地址
</property>
<property>
<name>dfs.namenode.rpc-address.bdp.nn2</name>
<value>node002:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.bdp.nn1</name>
<value>node001:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.bdp.nn2</name>
<value>node002:9870</value>
</property>
# 关于journalnode
<property>
<name>dfs.namenode.shared.edits.dir</name>
# journalnode中namenode存储的路径
<value>qjournal://node001:8485;node002:8485;node003:8485/bdp</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/bdp/hadoop/ha/qjm</value>
</property>
# 故障转移
<property>
<name>dfs.client.failover.proxy.provider.bdp</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> # 启动故障转移的类
<value>sshfence</value>
<value>shell(true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> # 启动故障转移的参数
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
# 启动2个进程
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
[root@node001 hadoop] vim workers
node001
node002
node003
5.拷贝分发软件
# 将配置好的软件分发到其他主机
scp -r /opt/ root@node002:/opt/
scp -r /opt/ root@node003:/opt/
6.修改环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 将环境变量拷贝到其他主机
scp /etc/profile root@node002:/etc/profile
scp /etc/profile root@node003:/etc/profile
# 重新加载三台服务器的环境变量
source /etc/profile
7.首先启动Zookeeper
zkServer.sh start
zkServer.sh status
启动JournalNode
[123]hdfs --daemon start journalnode
格式化NameNode
[root@node001]hdfs namenode -format
# 开启namenode的使用
[root@node001]hdfs --daemon start namenode
[root@node002]hdfs namenode -bootstrapStandby
[root@node001]hdfs zkfc -formatZK
[root@node001]start-dfs.sh
8.测试集群
http://node001:9870
http://node002:9870
[root@node001] hdfs dfs -mkdir -p /lzj
[root@node001] hdfs dfs -put zookeeper-3.4.5.tar.gz /zj/
# 设置块的大小
[root@node001] hdfs dfs -D dfs.blocksize=1048576 -put zookeeper-3.4.5.tar.gz /lzj/
9.关闭集群
[root@node001]# stop-dfs.sh
10.关机拍摄快照
shutdown -h now
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/15975592.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号