kafka
1.异步通信原理
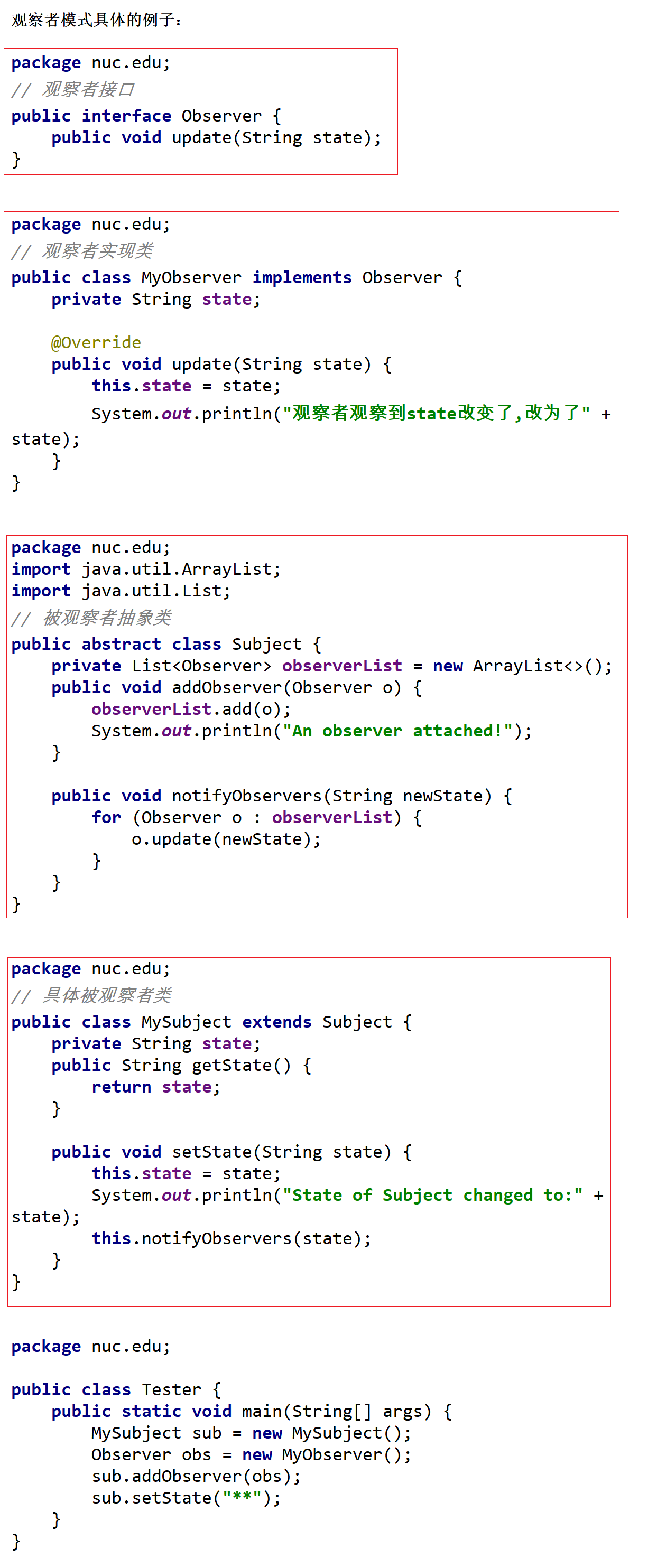
观察者模式
定义对象间一种一对多的依赖关系,每当一个对象(目标对象)改变状态,所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
场景:到货通知
生产者消费者模式
- 传统模式:
- 工人生产出车后,由工人给消费者。
- 耦合性高,当生产者和消费者发生变化时,需要重写业务逻辑。
- 生产者消费者模式
- 通过一个容器解决耦合。生产者和消费者彼此之间不直接通讯,而通过阻塞队列(存储介质)进行通信。
- N个线程进行生产,N个线程进行消费。
- 存储介质中先进先出原则。
- 解耦。支持并发。支持忙闲不均。
- 数据单元
- 关联到业务对象
2.消息系统原理
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注数据,无需关注数据在两个或多个应用间是如何传递的
点对点消息传递
- 消息持久化到一个队列中,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次,消费之后该数据从消息队列里删除。
- 能保证数据处理的顺序。
- 基于推送模型的消息系统,由消息代理记录消费状态。消息代理将消息推送到消费者后,标记这条消息为已经被消费,但无法很好的保证消费的处理语义。
发布订阅消息传递
- 消息被持久化到一个topic中。
- 消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一个数据可以被多个消费者消费,数据被消费后不会立马被删除。
- 消息的生产者称为发布者,消费者称为订阅者。
- Kafka采取拉取模型,由自己控制消费速度,以及消费进度,消费者可以按照任务的偏移量进行消费。
3. Kafka简介
kafka是分布式发布订阅消息系统,处理消费者在网站中的动作流数据.
设计目标
- O(1),处理速度快
- 高吞吐率
- 支持Kafka Server间的消息分区(指topic),及分布式消费,同时保证每个分区内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
- 支持在线水平扩展
优点
- 解耦
在生产者和消费者两端均设置一个相同的接口,两边都实现接口 - 冗余
- 扩展性
解耦了处理过程,只要另外能加处理过程即可. - 灵活性,峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但这样的突发流量并不常见;
如果以能处理这类峰值访问为标准,来投入资源,无疑是巨大的浪费.
使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃. - 可恢复性
系统的一部分组件失效时,不会影响整个系统. - 顺序保证
每个topic内部是有序的 - 缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素.
例如,加载一张图片比应用过滤器花费更少的时间.
消息队列通过一个缓冲层来帮助任务最高效率的执行---写入队列的处理会尽可能的快.该缓冲有助于控制和优化数据经过系统的速度. - 异步通信
允许用户把一个消息放入队列,但并不立即处理掉他.想向队列中放入多少消息就放入多少,然后再需要的时候再去处理他们.
4.Kafka系统架构(重要,背,都很重要)

5.Kafka环境搭建
[123]zkServer.sh start
[root@node001 opt]# tar -xvf kafka_2.11-0.8.2.1.tgz
[root@node001 opt]# rm -rf kafka_2.11-0.8.2.1.tgz
[root@node001 opt]# cd kafka_2.11-0.8.2.1/
[root@node001 kafka_2.11-0.8.2.1]# vim config/server.properties
{
broker.id=0
port=9092
log.dirs=/opt/kafka_2.11-0.8.2.1/kafka-logs
zookeeper.connect=node001:2181,node002:2181, node003:2181
}
[root@node001 /]# vi /etc/profile
{
# 添加
export KAFKA_HOME=/opt/kafka_2.11-0.8.2.1
export PATH=$KAFKA_HOME/bin:$PATH
}
[root@node001 /]# source /etc/profile
[root@node001 /]# scp -r /opt/kafka_2.11-0.8.2.1/ node002:/opt/
[root@node001 /]# scp -r /opt/kafka_2.11-0.8.2.1/ node003:/opt/
[root@node001 /]# scp /etc/profile node002:/etc/
[root@node001 /]# scp /etc/profile node003:/etc/
[root@node001 /]# ssh root@node002 "source /etc/
[root@node001 /]# ssh root@node003 "source /etc/
[root@node002 kafka_2.11-0.8.2.1]# vim config/server.properties
{
broker.id=1
}
[root@node003 kafka_2.11-0.8.2.1]# vim config/server.properties
{
broker.id=2
}
# 启动kafka
[root@node001 config]# kafka-server-start.sh /opt/kafka_2.11-0.8.2.1/config/server.properties
[root@node002 config]# kafka-server-start.sh /opt/kafka_2.11-0.8.2.1/config/server.properties
[root@node003 config]# kafka-server-start.sh /opt/kafka_2.11-0.8.2.1/config/server.properties
# 创建studentlog主题
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181,node002:2181,node003:2181 --create --replication-factor 1 --partitions 6 --topic "studentlog".
# 创建userlog主题
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181,node002:2181,node003:2181 --create --replication-factor 1 --partitions 3 --topic "userlog".
# 创建baidu主题
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181 --create --replication-factor 1 --partitions 6 --topic baidu
Created topic "baidu".
# 删除百度主题
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181 --delete --replication-factor 1 --partitions 6 --topic baidu
# 查看所有主题
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181 --list
baidu - marked for deletion
studentlog.
userlog.
# 查看某一节点的具体信息
[root@node001 ~]# kafka-topics.sh --zookeeper node001:2181 --describe --topic userlog.
# 创建一个生产者
[root@node001 ~]# kafka-console-producer.sh --broker-list node001:9092,node002:9092,node003:9092 --topic userlog.
# 创建一个消费者
[root@node001 ~]# kafka-console-consumer.sh --zookeeper node001:2181,node002:2181,node003:2181 --from-beginning --topic userlog.
flume可以读取单个文件的数据,而kafka是不能做到的。
# 创建一个消费者组
[root@node001 config]# pwd
/opt/kafka_2.11-0.8.2.1/config
[root@node001 config]# vim consumer.properties
{
zookeeper.connect=node001:2181,node002:2181,node003:2181
zookeeper.connection.timeout.ms=6000
group.id=test-consumer-group
}
[root@node001 config]# pwd
/opt/kafka_2.11-0.8.2.1/config
[root@node001 config]# cp consumer.properties consumer01.properties
[root@node001 config]# vim consumer01.properties
{
zookeeper.connect=node001:2181,node002:2181,node003:2181
zookeeper.connection.timeout.ms=6000
group.id=test01
}
# 一个消费者组中的消费者不会消费同一条数据,有offset偏移量,offset在zookeeper中
[root@node001 config]# kafka-console-consumer.sh --zookeeper node001:2181,node002:2181,node003:2181 --topic studentlog. --consumer.config /opt/kafka_2.11-0.8.2.1/config/consumer01.properties
6.Kafka数据检索机制(重要)
topic在物理层面以partition为分组,一个topic可以分成若干个partition.
partition还可以细分为Segment,一个partition物理上由多个Segment组成
- segment的参数有两个:
- log.segment.bytes:单个segment可容纳的最大数据量,默认为1GB
- log.segment.ms:Kafka在commit一个未写满的segment前,所等待的时间(默认为7天)
- LogSegment文件由两部分组成,分别为".index"文件和".log"文件,分别表示为Segment索引文件和数据文件
- partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值
- 数值大小为64位,20位数字字符长度,没有数字用0填充。
- 第一个segment
- 00000000000000000000.index
- 00000000000000000000.log
- .index文件>10G后会分割出一个.index文件来
- .log文件7天之后会分割出一个.log文件来
- 第二个segment,文件命名以第一个segment的最后一条消息的offset组成
- 偏移量的最后一位是文件的名字
- 00000000000000170410.index
- 00000000000000170410.log
- 第三个segment,文件命名以上一个segment的最后一条消息的offset组成
- 00000000000000239430.index
- 00000000000000239436. log
- 消息都具有固定的物理结构,包括:offset(8 bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte),attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。
7.数据的安全性(相当重要)
producer delivery guarantee
0 At least one 消息绝不会丢,但是可能会重复传输
1 At most once 消息可能会丢,但绝不会重复传输
2 Exactly once 每条消息肯定会被传输一次且仅传输一次
Producers可以选择是否为数据的写入接收ack,有以下几种ack的选项:request,required,acks
acks = 0:
Producer在ISR中的Leader已成功收到的数据并得到确认后发送下一条Message.
acks = 1:
这意味着Producer无需等待来自Broker的确认而继续发送下一批消息。
acks = all:
Producer需要等待ISR中的所有Follower都确认接收到数据后才算一次发送完成,可靠性最高。
ISR机制
如何选新leader?
从最接近leader的partition中选。
- 副本
- AR:标识副本的全集
- OSR:离开同步队的副本
- ISR:加入同步队列的副本
- ISR=Leader + 没有落后太多的副本AR = OSR + ISR。
- 我们备份数据就是防止数据丢失,当主节点挂掉时,可以启用备份节点
- producer--push-->leader
- leader--pull-->follower
- Follower每间隔一定时间去Leader拉取数据,来保证数据的同步ISR(in-syncReplica)
- 当主节点挂掉,并不是去Follower选择主,而是从ISR中选择主
- ISR记录的判断标准
- 超过10秒钟没有同步数据,不记录
- replica.lag.time.max.ms=10000主副节点差4000条数据,不记录
- 脏节点选举
- kafka采用—种降级措施来处理:
- 选举第一个恢复的node作为leader提供服务,以它的数据为基准,这个措施被称为脏leader选举
Broker数据存储机制
- 无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据。
- 1.基于时间:log.retention. hours=1681
- 2.基于大小: log.retention. bytes=1073741824
consumer delivery guarantee
- 如果将consumer 设置为autocommit,consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那 Kafka确保了Exactly once.
- 读完消息先commit再处理消息。
- 如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息
- 这就对应于At most once,消息可能会丢,但绝不会重复传输.
- 读完消息先处理再commit。
- 如果在处理完消息之后commit 之前consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了。
- 这就对应于At least once。消息绝不会丢,但是可能会重复传输
- 如果一定要做到Exactly once,就需要协调offset和实际操作的输出。
- 经典的做法是引入两阶段提交。
- Kafka默认保证At least once,并且允许通过设置producer异步提交来实现At most once
数据的消费
-
partiton_num=2,启动一个consumer进程订阅这个topic,对应的,stream_num设为2,也就是说启两个线程并行处理message。
-
如果auto.commit.enable=true,
- 当consumer fetch了—些数据但还没有完全处理掉的时候,
- 刚好到commit interval出发了提交offset操作,接着consumer crash掉了。
- 这时已经fetch的数据还没有处理完成但已经被commit掉,国此没有机会再次被处理,数据丢失。
- 这就对应于At most once,消息可能会丢,但绝不会重复传输.
-
auto.commit.enable=false,
- 假设consumer的两个fetcher各自拿了一条数据,并且由两个线程同时处理,
- 这时线程t1处理完partition1的数据,手动提交offset,这里需要着重说明的是,当手动执行commit的时候,
- 实际上是对这个consumer进程所占有的所有partition进行commit,kafka暂时还没有提供更细粒度的commit方式,
- 也就是说,即使t2没有处理完partition2的数据,offset也被t1提交掉了。
- 如果这时consumer crash掉,t2正在处理的这条数据就丢失了。
- 这就对应于At most once,消息可能会丢,但绝不会重复传输.
-
方法1:(将多线程问题转成单线程)
- 手动commit offset,并针对partition_num启用同样数目的consumer进程,这样就能保证一个consumer进程占有一个partition,commit offset的时候不会影响别的partition的offset。
- 但这个方法比较局限,因为partition和consumer进程的数目必须严格对应
-
方法2:(参考HDFS数据写入流程)
- 手动commit offset,另外在consumer端再将所有fetch到的数据缓存到queue里,当把queue里所有的数据处理完之后,再批量提交offset,这样就能保证只有处理完的数据才被commit。
8.JavaAPI
9.Kafka优化
partition数目
- 一般来说,每个partition能处理的吞吐为几MB/s(仍需要基于根据本地环境测试后获取准确指标),增加更多的partitions意味着:
。更高的并行度与吞吐
。可以扩展更多的(同一个consumer group中的)consumers
。若是集群中有较多的brokers,则可更大程度上利用闲置的brokers。但是会造成Zookeeper的更多选举
。也会在Kafka中打开更多的文件·调整准则
。一般来说,若是集群较小(小于6个brokers),则配置2 x broker数的partition数。在这里主要考虑的是之后的扩展。若是集群扩展了一倍(例如12个),则不用担心会有partition不足的现象发生
。一般来说,若是集群较大(大于12个),则配置1x broker数的partition数。因为这里不需要再考虑集群的扩展情况,与broker数相同的partition数已经足够应付常规场景。若有必要,则再手动调整
。考虑最高峰吞吐需要的并行consumer数,调整partition的数目。若是应用场景需要有20个(同一个consumer group中的) consumer并行消费,则据此设置为20个partition
。考虑producer所需的吞吐,调整partition数目(如果producer的吞吐非常高,或是在接下来两年内都比较高,则增加partition的数目)
Replication factor
·此参数决定的是records复制的数目,建议至少设置为2,一般是3,最高设置为4。·更高的replication factor(假设数目为N)意味着:
。系统更稳定(允许N-1个broker宕机)
。更多的副本(如果acks=all,则会造成较高的延时)
。系统磁盘的使用率会更高(一般若是RF为3,则相对于RF为2时,会占据更多50%的磁盘空间)·调整准则:
。以3为起始(当然至少需要有3个brokers,同时也不建议一个Kafka集群中节点数少于3个节点)
。如果replication性能成为了瓶颈或是一个issue,则建议使用一个性能更好的broker,而不是降低RF的数目。永远不要在生产环境中设置RF为1
10.Flume+Kafka集成
本文来自博客园,作者:jsqup,转载请注明原文链接:https://www.cnblogs.com/jsqup/p/15691583.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号