
随笔分类 - 日报
摘要:路径 C:\Windows\System32\drivers\etc\hosts 注意 HDFS可视化界面上如果要下载某一个,必须配置主机和ip的映射关系
阅读全文
摘要:import java.util.Properties import org.apache.spark.SparkConf import org.apache.spark.sql.{SaveMode, SparkSession} object DayFlow { def main(args: Arr
阅读全文
摘要:fileToHdfs.conf文件 #sources别名:r1 a1.sources = r1 #sink别名:k1 a1.sinks = k1 #channel别名:c1 a1.channels = c1 # 定义flume的source数据源 文件 a1.sources.r1.type = ex
阅读全文
摘要:package camera import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession // 摄像异常状态的功能代码 object CameraAbnormality { def main(args: Arr
阅读全文
摘要:pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
摘要:日期模拟 import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import java.util.Random; public class DataUtil { public stat
阅读全文
摘要:读流程 1) HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。 2) 接着Client通过刚才获取到的HRegionSe
阅读全文
摘要:hbase安装完成之后,给我们提供了一个命令行客户端,hbase shell 命名空间有关的命令:namespace组 增删改查 create_namespace "demo" # 创建一个demo的命名空间 drop_namespace "demo" # 删除一个demo的命名空间 list_na
阅读全文
摘要:1. 概述 HBase是基于Hadoop的一个非关系型数据库(NoSQL数据库),HBase存储底层也是基于HDFS存储的。HBase和Hive很像,Hive是数据仓库 2. HBase中的基本概念 NameSpace:类似于关系型数据库的Database,每个命名空间下有多个表 Table:表名
阅读全文
摘要:不需要设置master在哪个节点上,只要在配置了HA模式的Spark集群上,任何一台机器都可以启动Master 需要先启动zookeeper zkServer.sh start 三台节点 [root@node1 conf]# pwd /opt/app/spark-2.3.1/conf [root@n
阅读全文
摘要:1. 上传zookeeper解压: tar -zxvf zookeeper-3.4.5.tar.gz 2. 修改配置文件[三台节点] [node123]# cd /opt/app/data/zookeeper-3.4.5/conf/ [node123]# mv zoo_sample.cfg zoo.
阅读全文
摘要:[123]zkServer.sh start [node123]# tar -xvf kafka_2.11-0.8.2.1.tgz [node123]# cd kafka_2.11-0.8.2.1/config [node123]# vi server.properties { broker.id=
阅读全文
摘要:集群 | node1 | node2 | node3 | | | | | | NameNode | NameNode | | | JournalNode | JournalNode | JournalNode | | DataNode | DataNode | DataNode | | ZK | Z
阅读全文
摘要:Zookeeper集群的正常部署,并启动[三个节点] zkServer.sh start Hadoop集群的正常部署并启动[三个节点] start-dfs.sh start-yarn.sh HBASE高可用搭建 hbase-env.sh export JAVA_HOME=/opt/app/jdk1.
阅读全文
摘要:进程介绍 1. Zkfc(ZKFailoverController)作用: 切换NN状态; 对NN进行心跳保持(监听),当发现NN active异常,会通知Zookeeper,然后ZK重新选举一个新的NN接管,切换成NN active状态; 2. JournalNode NameNode之间共享数据
阅读全文
摘要:背景: 电商网站用户在网站的每次行为都会以日志数据的形式加以记录到日志文件中,其中用户的行为数据日志格式如下:1,2268318,pv,1511544070 黑名单用户的定义规则如下: 如果某一件商品被同一用户在1分钟之内点击超过10次,那么此时这个用户就是当前商品的黑名单用户,我们需要将黑名单用户
阅读全文
摘要: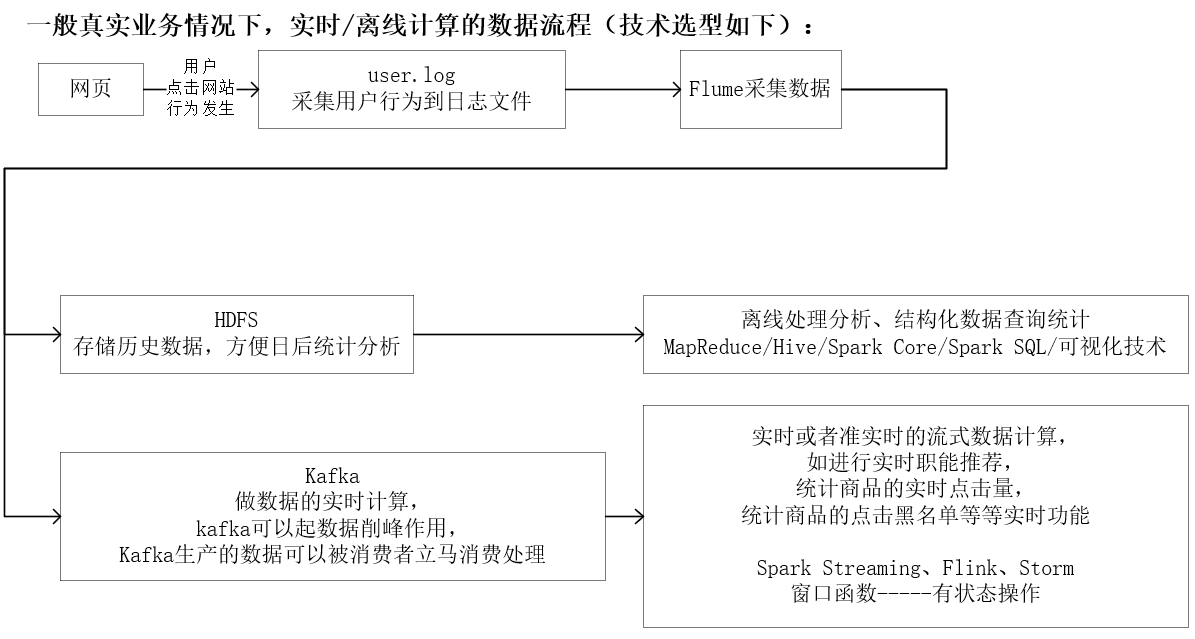
阅读全文
摘要:Spark Streaming只能充当Kafka的消费者 Spark Steaming整合Kafka数据,读取Kafka数据有两种方式 1、Receiver(使用Spark中接受器去处理Kafka的数据)方法 连接zookeeper集群读取数据 仅作了解(被淘汰) 2、Direct方法--直连kaf
阅读全文
摘要:引入pom依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号