

prometheus监控新增node节点
基础信息配置:
| 角色 | ip | port | hostname |
| prometheus server | 172.16.23.120 | 9090 | master |
| node_exporter master | 172.16.23.120 | 9100 | master |
| node_exporter node1 | 172.16.23.121 | 9100 | node1 |
在node1上安装node_exporter并进行相关的配置,这里将在master机器采用ansible进行配置:
[root@master prometheus]# ansible -i /etc/ansible/hosts 172.16.23.121 -m shell -a "hostname" 172.16.23.121 | CHANGED | rc=0 >> node1 [root@master prometheus]# ansible 172.16.23.121 -m shell -a "hostname" 172.16.23.121 | CHANGED | rc=0 >> node1 [root@master prometheus]# ansible 172.16.23.121 -m copy -a "src=/usr/local/node_exporter-1.0.1.linux-amd64.tar.gz dest=/usr/local/node_exporter-1.0.1.linux-amd64.tar.gz" 172.16.23.121 | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "279ec99af23dd18ac319cfb27ee544d88c3c14c9", "dest": "/usr/local/node_exporter-1.0.1.linux-amd64.tar.gz", "gid": 0, "group": "root", "md5sum": "e39f161ae0e7b486b98772c4aeb93805", "mode": "0644", "owner": "root", "secontext": "system_u:object_r:usr_t:s0", "size": 9520728, "src": "/root/.ansible/tmp/ansible-tmp-1600599484.89-31367299931714/source", "state": "file", "uid": 0 } [root@master prometheus]# ansible 172.16.23.121 -m shell -a "ls -l /usr/local/node_exporter-1.0.1.linux-amd64.tar.gz" 172.16.23.121 | CHANGED | rc=0 >> -rw-r--r--. 1 root root 9520728 9月 20 18:58 /usr/local/node_exporter-1.0.1.linux-amd64.tar.gz
[root@master prometheus]# ansible 172.16.23.121 -m shell -a "cd /usr/local/;tar xf node_exporter-1.0.1.linux-amd64.tar.gz;ln -sv node_exporter-1.0.1.linux-amd64 node_exporter"
172.16.23.121 | CHANGED | rc=0 >>
"node_exporter" -> "node_exporter-1.0.1.linux-amd64"
然后进行服务上的一些配置:
[root@master prometheus]# ansible 172.16.23.121 -m copy -a "src=/usr/lib/systemd/system/node_exporter.service dest=/usr/lib/systemd/system/node_exporter.service" 172.16.23.121 | CHANGED => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "changed": true, "checksum": "085e9b628d8e7419bab151285b8aa1c717a40892", "dest": "/usr/lib/systemd/system/node_exporter.service", "gid": 0, "group": "root", "md5sum": "ea66958b12a29bef63e3b52563f1dcbe", "mode": "0644", "owner": "root", "secontext": "system_u:object_r:systemd_unit_file_t:s0", "size": 283, "src": "/root/.ansible/tmp/ansible-tmp-1600599820.88-3938928668863/source", "state": "file", "uid": 0 } [root@master prometheus]# ansible 172.16.23.121 -m shell -a "systemctl enable node_exporter;systemctl start node_exporter;ps -ef|grep node_exporter;lsof -i:9100" 172.16.23.121 | CHANGED | rc=0 >> root 2567 2566 0 19:09 pts/1 00:00:00 /bin/sh -c systemctl enable node_exporter;systemctl start node_exporter;ps -ef|grep node_exporter;lsof -i:9100 root 2592 1 0 19:09 ? 00:00:00 /usr/local/node_exporter/node_exporter --web.listen-address=:9100 --collector.systemd --collector.systemd.unit-whitelist="(ssh|docker|rsyslog|redis-server).service" root 2594 2567 0 19:09 pts/1 00:00:00 grep node_exporter COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME node_expo 2592 root 3u IPv6 27161 0t0 TCP *:jetdirect (LISTEN)
修改prometheus server配置将node1配置添加进去,收集node1数据:
[root@master prometheus]# cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] - job_name: 'linux_node' static_configs: - targets: ['172.16.23.120:9100'] labels: nodename: master role: master - targets: ['172.16.23.121:9100'] labels: nodename: node1 role: node1
然后重启prometheus server端:
# systemctl restart prometheus
然后刷新prometheus控制台:
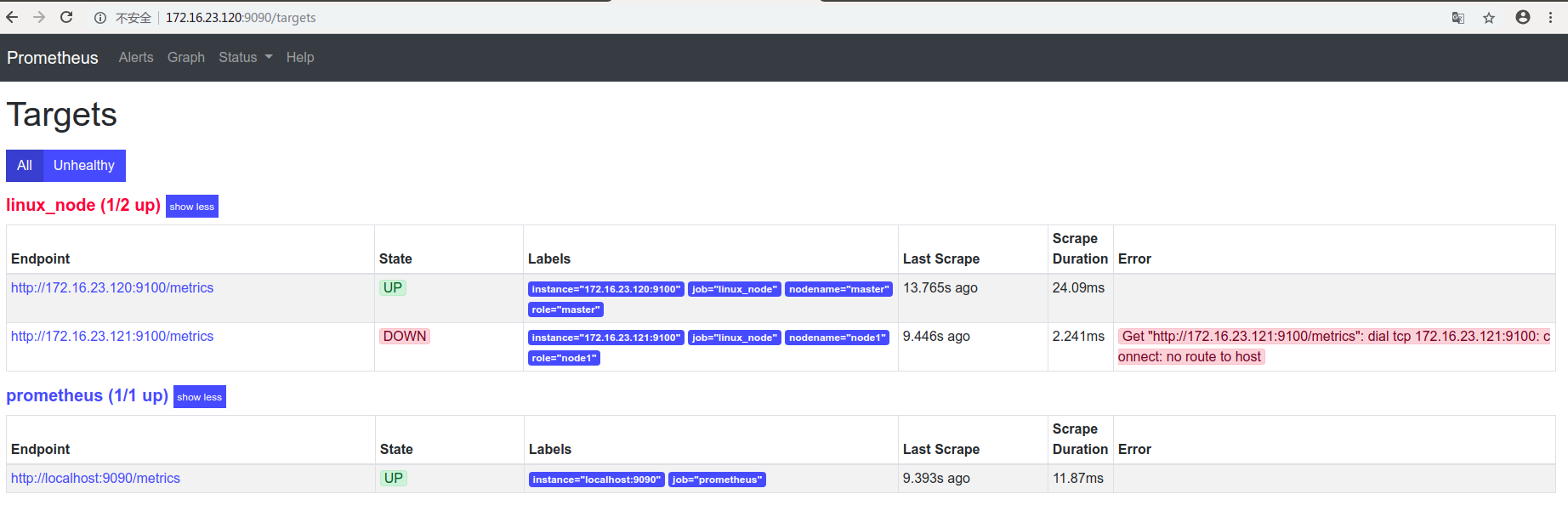
可以看见有报错,由于网络或者其他原因get不到node1的数据,开始排查:
[root@master prometheus]# ping 172.16.23.121 PING 172.16.23.121 (172.16.23.121) 56(84) bytes of data. 64 bytes from 172.16.23.121: icmp_seq=1 ttl=64 time=1.21 ms 64 bytes from 172.16.23.121: icmp_seq=2 ttl=64 time=1.34 ms
网络可以看见是通的,在网页打开http://172.16.23.121:9100/metrics也是访问不到,那么原因就是防火墙问题:
[root@node1 local]# systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 日 2020-09-20 18:37:34 CST; 39min ago Docs: man:firewalld(1) Main PID: 714 (firewalld) CGroup: /system.slice/firewalld.service └─714 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid 9月 20 18:37:31 node1 systemd[1]: Starting firewalld - dynamic firewall daemon... 9月 20 18:37:34 node1 systemd[1]: Started firewalld - dynamic firewall daemon.
于是停掉防火墙,刷新控制台如下:

至此新增node1节点到监控成功,数据采集正常
prometheus配置文件label关键字分析:
上面prometheus控制台中labels这个下面有instance这个key,而在配置文件中却没有,instance这个key默认不设置就是targets的内容,当instance这个key设置了那么就会取设置的值:
- job_name: 'linux_node' static_configs: - targets: ['172.16.23.120:9100'] labels: instance: 172.16.23.120 nodename: master role: master - targets: ['172.16.23.121:9100'] labels: instance: 172.16.23.121 nodename: node1 role: node1
控制台看看效果:

我们还可以根据设置其他labels属性进行定义不同的节点
目前上面都是prometheus server去pull拉取节点的数据metrics收集到tsdb中,当然也可以进行节点push到server端,有两种方式:
1.被监控的节点进行--collector.textfile设置,具体操作如下:
修改node_exporter的启动参数增加--collector.textfile参数:
[root@node1 node_exporter]# cat /usr/lib/systemd/system/node_exporter.service [Unit] Description=node_exporter [Service] ExecStart=/usr/local/node_exporter/node_exporter \ --web.listen-address=:9100 \ --collector.systemd \ --collector.systemd.unit-whitelist="(ssh|docker|rsyslog|redis-server).service" \ --collector.textfile.directory=/usr/local/node_exporter/textfile.collected # 这是修改增加的一行 Restart=on-failure [Install] WantedBy=mutil-user.target
创建上面的目录:
# mkdir /usr/local/node_exporter/textfile.collected
prometheus的数据格式是key value,于是编写一个小脚本:
# cd /usr/local/node_exporter # mkdir scripts # cd scripts/ [root@node1 node_exporter]# cat scripts/login_user_count.sh #!/bin/bash echo "node_login_users `who|wc -l`" > /usr/local/node_exporter/textfile.collected/login_users.prom [root@node1 node_exporter]# crontab -l */1 * * * * /usr/local/node_exporter/scripts/login_user_count.sh
看看本地采集的数据:
[root@node1 scripts]# cat ../textfile.collected/login_users.prom node_login_users 2
重启node_exporter服务:
# systemctl daemon-reload
# systemctl restart node_exporter
查看本地的metrics数据:
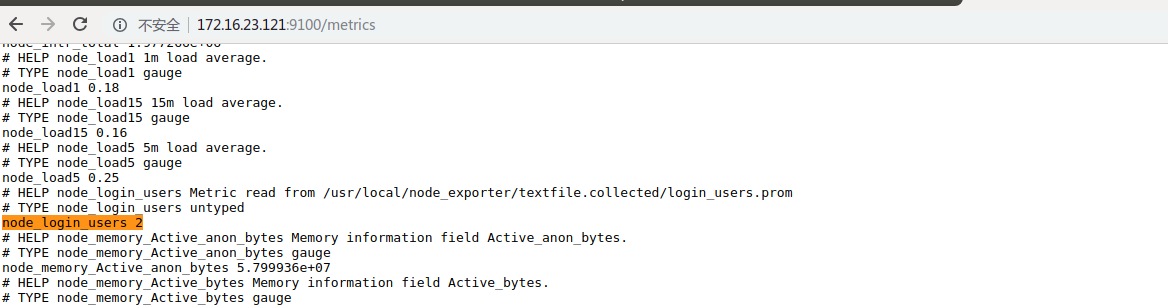
然后从prometheus server端也就是控制台查询数据:
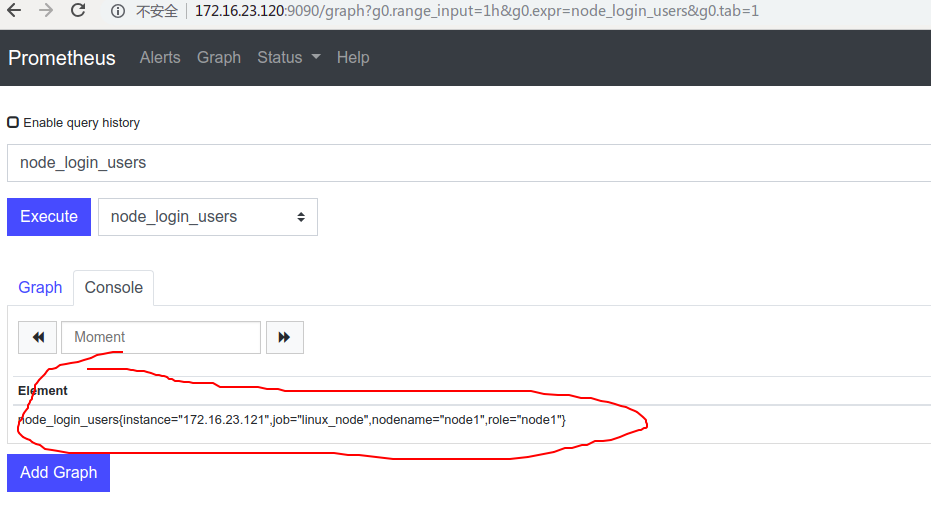
这样被监控的节点就可以主动将本地的metric数据push到server端了
2.新增node2节点,通过自定义label标签push text的数据到prometheus server,操作如下:
2.1安装node_exporter,步骤参考上面,并添加自动参数:--collector.textfile.directory=/usr/local/node_exporter/textfile.collected
2.2编写脚本并配置定时任务:
[root@node2 node_exporter]# cat /usr/local/node_exporter/scripts/login_user_count.sh #!/bin/bash num=$(who|wc -l) echo "ops_bash{hostname=\"node2\"} ${num}" > /usr/local/node_exporter/textfile.collected/ops_bash.prom [root@node2 node_exporter]# crontab -l */1 * * * * /usr/local/node_exporter/scripts/login_user_count.sh
查询本地获取的数据:
[root@node2 node_exporter]# cat /usr/local/node_exporter/textfile.collected/ops_bash.prom ops_bash{hostname="node2"} 2
然后查询本地metric数据:
[root@node2 node_exporter]# curl -s http://172.16.23.122:9100/metrics|grep ops_bash node_textfile_mtime_seconds{file="ops_bash.prom"} 1.600615621e+09 # HELP ops_bash Metric read from /usr/local/node_exporter/textfile.collected/ops_bash.prom # TYPE ops_bash untyped ops_bash{hostname="node2"} 2
2.3node2本地数据正常后,将node2节点配置到prometheus server端,修改配置如下:
- targets: ['172.16.23.122:9100']
2.4重启prometheus服务:
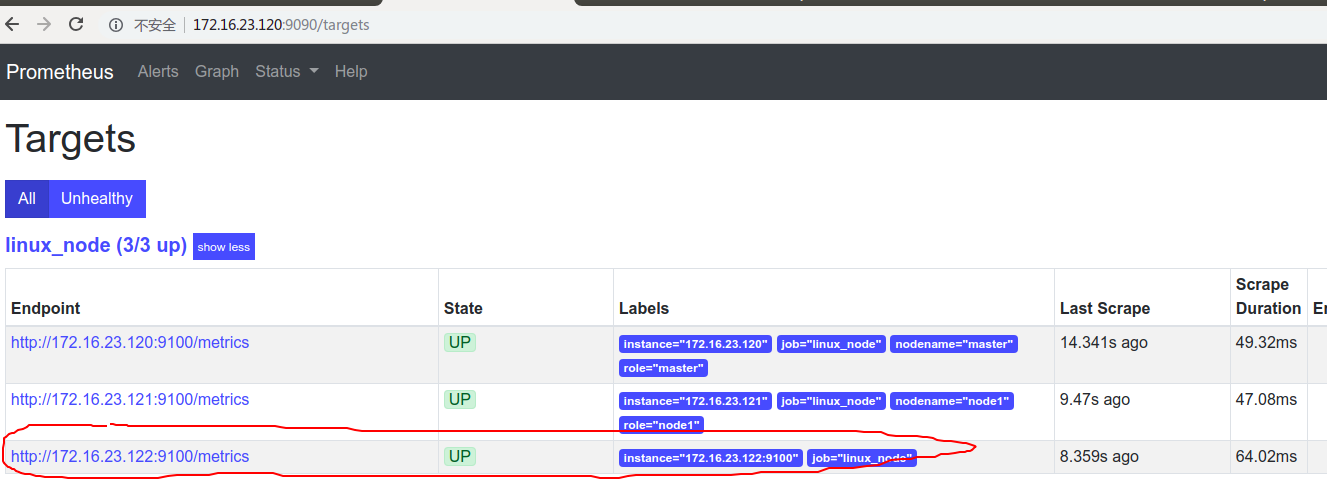
2.5查询promsql:
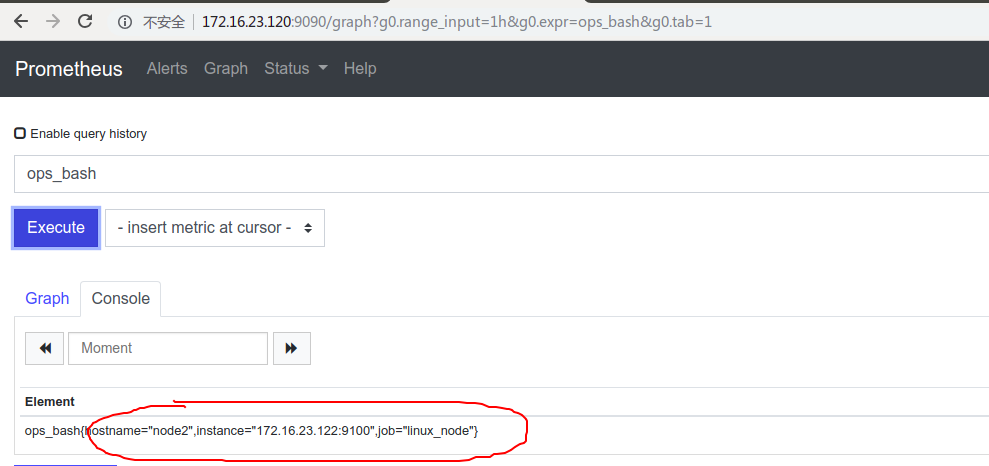
可以看见,除了在prometheus的配置文件可以定义label便签也可以在node节点的prom文件中定义label
[root@node2 node_exporter]# cat textfile.collected/ops_bash.prom ops_bash{hostname="node2"} 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号