基于Scrapy的交互式漫画爬虫
▼ 预览 ▼
| 预览/多选/翻页 | 读剪贴板 |
|---|---|
 |
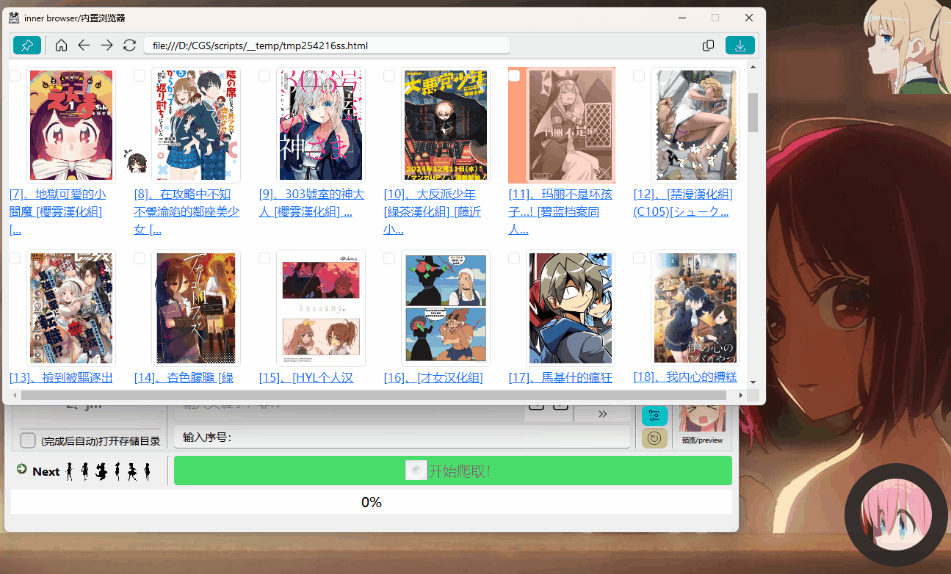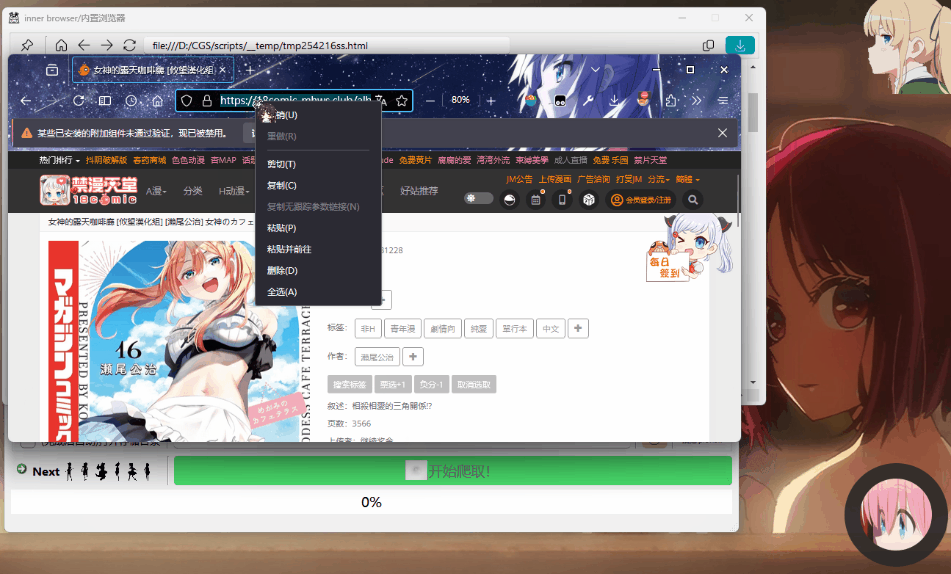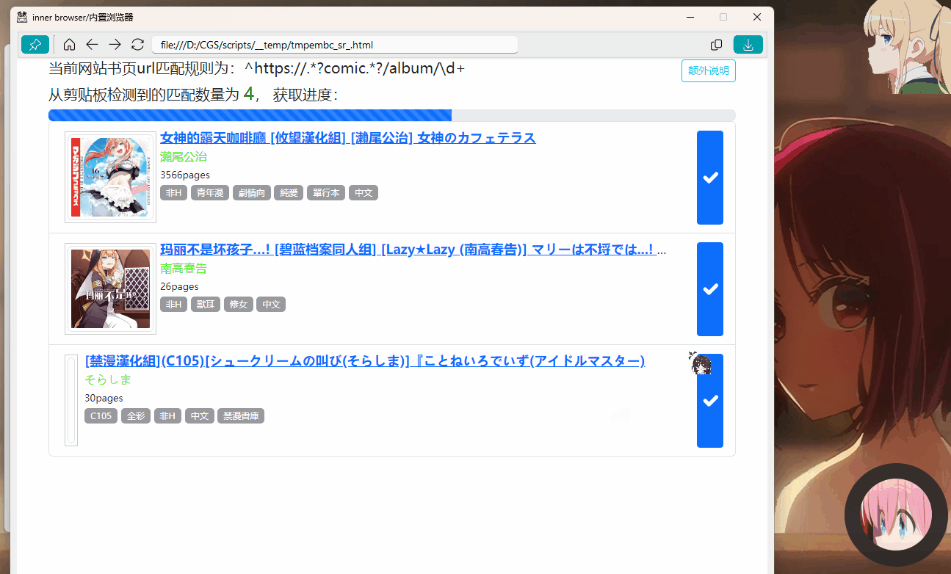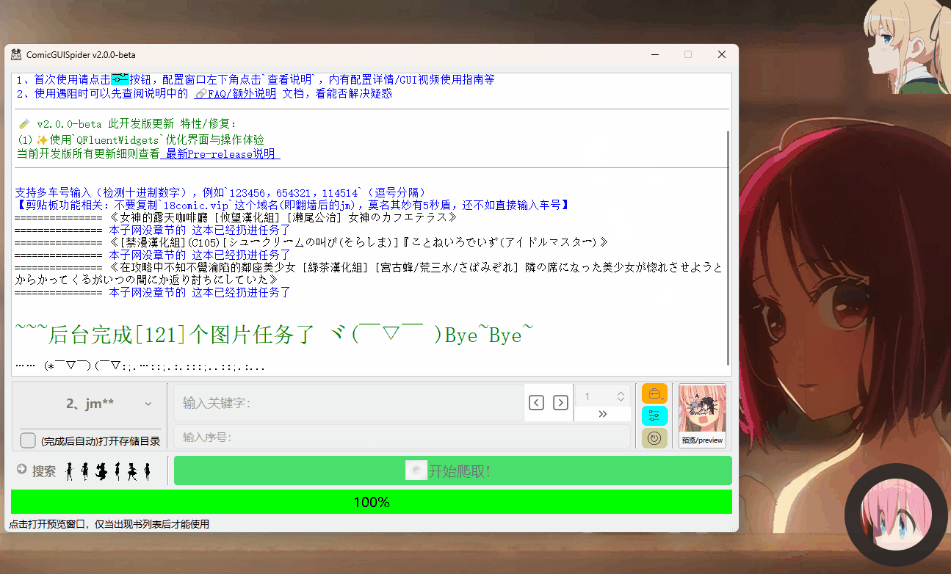 |
前言
下文基本旧的,这篇文章很老了,但是项目翻新并持续维护!
支持拷贝, jmcomic2, wnacg,e绅士等,直接打开 Github项目地址 看吧
该项目始于个人兴趣,本意为给无代码经验的朋友做到能开箱即用
阅读此文需要少量Scrapy,PyQt 知识,全文仅分享交流 摘要思路,如需可阅读源码,欢迎提 issue
一、Scrapy
思路构想
基类封装了框架所需方法,框架基于三级页面 (标题-章节-详情页) 网站,内部方法分岔线基于交互思想
-
GUI传参并开启后台 >> spider开始工作于重写的start_requests >> 在parse等处理resp的方法后挂起等待选择
-
执行顺序为 (1) parse -- frame_book --> (2) parse_section -- frame_section -->(3) yield item frame方法下述讲解
-
pipeline对item作最后的下载,改名等处理,至此spider完成一个生命周期,发送结束信号逻辑交回GUI
下述讲解scrapy的各块工作,pickup有点意思的部分
BaseClassSpider
class BaseComicSpider(scrapy.Spider):
"""改写start_requests"""
step = 'loop'
current_status = {}
print_Q = None
current_Q = None
step_Q = None
bar = None # 此处及以上变量均为交互信号
total = 0 # item 计数,pipeline处讲解
search_url_head = NotImplementedError('需要自定义搜索网址')
mappings = {'': ''} # mappings自定义关键字对应网址
# ……………………
def parse(self, response):
frame_book_results = self.frame_book(response)
yield scrapy.Request(url=title_url, ………………)
def frame_book(self, response) -> dict:
raise NotImplementedError
def elect_res(self, elect: list, frame_results: dict, **kw) -> list:
# 封装方法实现(1)选择elect与(2)frame方法格式化后的显示result ->
# -> 返回[[elected_title1, title1_url], [title2, title2_url]……]的格式数据
pass
# ……………………
def close(self, reason):
# ………处理管道,session等关闭工作
self.print_Q.put('结束信号') # spider生命周期结束
InstanceClassSpider
后台执行的实例,简单的二级页面仅需复写两个frame方法,对应的是扩展的基类2
frame方法功能为定位目标元素位置,实时清洗数据返回给前端显示
class ComicxxxSpider(BaseComicSpider2):
name = 'comicxxx'
allowed_domains = ['m.xxx.com']
search_url_head = 'http://m.xxx.com/search/?keywords='
mappings = {'更新': 'http://m.xxx.com/update/', '排名': 'http://m.xxx.com/rank/'}
def frame_book(self, response):
# ……………………
title = target.xpath(title_xpath).get().strip()
self.print_Q.put(example_b.format(str(x + 1), title)) # 发送前端print信号,流式数据
def frame_section(self, response):
pass # 类上
setting
setting.py自定义部分与部署相关,使用 工具集 的方法读取配置文件构成变量
IMAGES_STORE, log_path, PROXY_CUST, LOG_LEVEL = get_info()
os.makedirs(f'{log_path}', exist_ok=True)
# 日志输出
LOG_FILE = f"{log_path}/scrapy.log"
SPECIAL = ['xxxxx']
pipelines
进度条这个一开始时还不知怎么处理,后来瞄了一下Pipeline类的源码发现downloaded方法算较为接近了
此处两方法都用上了spider = self.spiderinfo.spider 十分好用! 突破点!想破头点着看属性发现的
def file_path(self, request, response=None, info=None):
"""图片下载存储前调用此方法,默认为url的md5后字符串,此处修改成自定义的有序命名"""
title = sub(r'([|.:<>?*"\\/])', '-', request.item.get('title')) # 对非法字符预处理
section = sub(r'([|.:<>?*"\\/])', '-', request.item.get('section'))
page = '第%s页.jpg' % request.item.get('page')
spider = self.spiderinfo.spider # setting.py的一部分参数在此使用
basepath = spider.settings.get('IMAGES_STORE')
path = f"{basepath}\\特殊\\{title}" if spider.name in spider.settings.get(
'SPECIAL') else f"{basepath}\\{title}\\{section}\\"
os.makedirs(path, exist_ok=True)
return os.path.join(path, page)
def image_downloaded(self, response, request, info):
"""继承的ImagesPipeline图片(文件)下载完成方法,下载进度条动态显示的实现就在此处"""
self.now += 1 # (ComicPipeline)self.now即为现时处理量
spider = self.spiderinfo.spider
percent = int((self.now / spider.total) * 100) # spider.total即为item的总任务量
if percent > self.threshold:
percent -= int((percent / self.threshold) * 100) # 进度缓慢化(算法待优化)
spider.bar.put(int(percent)) # 后台处理百分比进度扔回GUI界面
super(ComicPipeline, self).image_downloaded(response=response,request=request, info=info)
其他:Items与Middlewares要点不多,略过
二、GUI (Qt)
主界面及功能

-
按键逻辑:槽函数实现,内部实现一定量的按钮禁用方法引导操作
- 选取网站 按钮与 输入关键字 构成参数,由→搜索 按钮触发工作线程等生成,然后替换成 Next 按钮
- Next 按钮为正常流程 -- 触发解除后台因等待输入造成的主动阻塞 同时传递 输入序号 的值
- Retry 按钮承担后台Spider中parse方法间的逆跳转,以及重启GUI的功能
-
视窗与信息
-
主视窗textbrowser,流式显示主要数据;整体内联其他视窗,略过
-
说明按钮通用说明、底下状态栏通过setStatusTip方法于各操作时提供人性化操作提示
# 节选 def status_tip(index): text = {0: None, 1: 'x网:(1)输入【搜索词】返回搜索结果(2)可输入【更新】【排名】..字如其名', 2: 'xxM网:(1)输入【搜索词】返回搜索结果(2)可输入【更新】【推荐】..字如其名', 3: 'xxx网:(1)输入【搜索词】返回搜索结果(2)可输入【最新】【日排名】【周排名】【月排名】..字如其名'} self.searchinput.setStatusTip(QCoreApplication.translate("MainWindow", text[index])) self.chooseBox.currentIndexChanged.connect(status_tip)- 进度条,关联 pipeline 的信号输出
-
节选 Next 按钮逻辑的 槽函数
def next_schedule(self):
def start_and_search():
self.log.debug('===--→ -*- searching')
self.next_btn.setText('Next')
keyword = self.searchinput.text()[6:].strip()
index = self.chooseBox.currentIndex()
if self.nextclickCnt == 0: # 从section步 回parse步 的话以免重开
self.bThread = WorkThread(self)
def crawl_btn(text):
if len(text) > 5:
self.crawl_btn.setEnabled(self.step_recv()=='parse section')
self.next_btn.setDisabled(self.crawl_btn.isEnabled())
self.chooseinput.textChanged.connect(crawl_btn)
self.p = Process(target=crawl_what, args=(index, self.print_Q, self.bar, self.current_Q, self.step_Q))
self.bThread.print_signal.connect(self.textbrowser_load)
self.bThread.item_count_signal.connect(self.processbar_load)
self.bThread.finishSignal.connect(self.crawl_end)
self.p.start()
self.bThread.start()
self.log.info(f'-*-*- Background thread starting')
self.chooseBox.setDisabled(True)
self.params_send({'keyword':keyword})
self.log.debug(f'website_index:[{index}], keyword [{keyword}] success ')
def _next():
self.log.debug('===--→ nexting')
self.judge_retry() # 非retry的时候先把retry=Flase解锁spider的下一步
choose = judge_input(self.chooseinput.text()[5:].strip())
if self.nextclickCnt == 1:
self.book_choose = choose
# 选0的话这里要爬虫返回书本数量数据
self.book_num = len(self.book_choose)
if self.book_num > 1:
self.log.info('book_num > 1')
self.textBrowser.append(self.warning_(f'警告!!多选书本时不要随意使用 retry<br>'))
self.chooseinput.clear()
# choose逻辑 交由crawl, next,retry3个btn的schedule控制
self.params_send({'choose': choose})
self.log.debug(f'send choose: {choose} success')
self.retrybtn.setEnabled(True)
if self.next_btn.text()!='搜索':
_next()
else:
start_and_search()
self.nextclickCnt += 1
self.searchinput.setEnabled(False)
self.chooseinput.setFocusPolicy(Qt.StrongFocus)
self.step_recv() # 封装的self.step_Q处理方法
self.log.debug(f"===--→ next_schedule end (now step: {self.step})\n")
后台线程
后台爬虫进程创建方法 ,上述UI主线程中Next逻辑的 start_and_search() 调用
def crawl_what(index, print_Q, bar, current_Q, step_Q):
spider_what = {1: 'comic1,
2: 'comic2',
3: 'comic3'}
freeze_support()
process = CrawlerProcess(get_project_settings())
process.crawl(spider_what[index], print_Q=print_Q, bar=bar, current_Q=current_Q, step_Q=step_Q)
process.start()
process.join()
process.stop()
分离UI主线程与工作线程(项目代码中此处可整合爬虫进程一起)
class WorkThread(QThread):
item_count_signal = pyqtSignal(int)
print_signal = pyqtSignal(str)
finishSignal = pyqtSignal(str)
active = True
def __init__(self, gui):
super(WorkThread, self).__init__()
self.gui = gui
def run(self):
while self.active:
self.msleep(8)
if not self.gui.print_Q.empty():
self.msleep(8)
self.print_signal.emit(str(self.gui.print_Q.get()))
if not self.gui.bar.empty():
self.item_count_signal.emit(self.gui.bar.get())
self.msleep(10)
if '完成任务' in self.gui.textBrowser.toPlainText():
self.item_count_signal.emit(100)
self.msleep(20)
break
if self.active:
from ComicSpider.settings import IMAGES_STORE
self.finishSignal.emit(IMAGES_STORE)
辅助工具
资源处理工具
- PYUIC >>> 将.ui界面文件转换成py文件
- pyrcc5 >>> 将编入资源路径后的qrc文件,转换成py文件
三、部署
打包,还用pyinstaller?狗都不用
END
欢迎前往 本项目 release有更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号