
第一章 使用神经网络识别手写数字-1 感知器 Perceptrons
原文:http://neuralnetworksanddeeplearning.com/chap1.html#perceptrons
什么是神经网络?首先,我解释一下一种叫做感知器的人工神经元。感知器是由科学家弗兰克·罗森布拉特(Frank Rosenblatt)在1950年代和1960年代,受到沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)早期工作的启发而开发的。如今,人们已经普遍使用人工网络的其它模型(本书以及神经网络的许多现代著作中),如一种主要使用的被称为sigmoid神经元的神经元模型。我们很快就会讲到sigmoid神经元,但为了弄明白sigmoid神经元为何要那样子定义,先花些时间弄明白感知器是值得的。
那么,感知器是如何工作的呢?请看定义:一个感知器拥有许多数量的二元输入(binary inputs),和一个唯一的二元输出(binary output)

如图,这个感知器拥有三个输入x1,x2,x3。通常来说,它能拥有更多或者更少的输入。罗森布拉特提出一个简单的规则来计算输出,他采用权重w1,w2,w3...一组实数来表示各个输入对输出的重要性。神经元的输出(0或者1)取决于w1*x1+w2*x2+w3*x3+...wn*xn =(Σiwixi)的和是大于或是小于某个阈值,和权重一样,阈值也是一个实数,是这个感知器的一个参数,用更精确的代数式表达为:
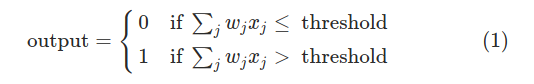
这就是感知器工作原理的全部!
那便是基本的数学模型。你可以把感知器当作是法官,x1、x2……输入当作是证据,法官通过权衡证据(给每个证据乘以一个权重参数)作出合适的决策(输出)。让我给你举个例子,一个不太现实的例子,但很好理解。很快我们也会接触到更多真实的例子。
设想一下周末快到了,并且你听说你的城市将举行一个奶酪节,你喜欢奶酪,并且试图决定是否去参加节日,你可以权衡三个因素来决定是否要去:
1、天气好不好?
2、你的男(女)朋友想不想陪你去?
3、节目地点离公交站近吗?(你没有车子)
我们可以通过3个相应的二进制变量来表示这三个因素x1、x2和x3。x1=0表示天气不好,x1=1表示天气好;x2=0表示对象不想一起去,x2=1表示想,x3=0公车站不近,x3=1为公车站近
现在,假设你实在喜欢奶酪,甚至不论你的对象是否对奶酪节感兴趣,路途多么遥远,你都想去;但是你实在讨厌天气不好,天气不好的话,根本没法参加节日!你可以使用感知器来为决策建模。如设w1=6作为天气的权重,w2=2、w3=2作为其它两个因素的权重,更大的w1表示天气对你更重要,比对象是否加入你、路途远不远重要得多。最后,假设你选择5作为这个感知器的阈值。有了这些选项,这个感知器实现了你想要的决策模型,天气好的时候输出1,天气不好的时候输出0,你对象想不想去,或者附近有没有公共交通,对输出没有影响。
通过改变感知器的权重和阈值,我们可以得到不同的决策模型。比如,将阈值改为3,那么不管天气好不好,只要你对象肯陪你去,并且附近有公交,该感知器都会作出你应该去的决定。换句话说,这是一个不同的决策模型。降低阈值表示你更愿意去参加节日。
显然,感知器并不是一个完整的人类决策模型。这个示例说明的是一个感知器如何通过衡量不同因素来作出决策,而一个复杂的感知器网络作出更加奥妙的决策似乎是合理的。

如上图这个感知器网络,第一列的感知器单元组合,我们称之为第一层——通过权衡输入(inputs)正在作出三个非常简单的决策。第二层的感知器做什么呢?那些感知器正通过衡量第一层的结果来作出决策,这样,第二层中的感知器可以比第一层中的感知器在更复杂,更抽象的级别上做出决策。而第三层的感知器能作出更加复杂的决策,这样,一个多层的感知器网络便能用于复杂的决策。
顺带一提,当我定义感知器的时候,我指的是只有一个输出的感知器。上图的网络中,感知器们看起来有很多个输出,事实上它们依然只有一个输出,多个输出箭头仅仅表示一个感知器的输出被作为用于其它多个感知器的输入,这样比画出一条线条,然后分成多个叉要省事一点。
让我们简化一下感知器的描述方式:条件Σiwixi > threshold看起来太繁琐了,我们修改其中两个符号来简化它。第一是把Σiwixi 写成点乘的形式——w·x≡Σiwixi ,其中w,x是向量,分别代表权重和输入的分量;第二是将权重threshold移到不等式的另外一边变成感知器的偏差(偏置)参数bias(pytorch里的bias就是这个)b≡threshold,使用偏差参数代替阈值,感知器的规则可以改写为:
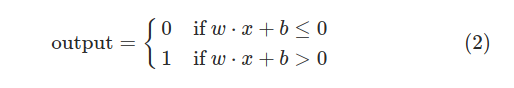
你可以将偏差参数bias当作是感知器输出1的难易程度的量度,或者更笼统地说,bias是感知器被激活的难易程度的量度。一个具有很大偏差参数的感知器,非常容易输出1,但如果是一个很大的负值,那它就很难输出1。显然,引入偏差参数只是我们描述感知器的一个小变化,但是很快我们便能看到,它将带来更进一步的符号简化。因此,本书的其余部分我们不再使用阈值threshold,而是使用偏差bias。
前面我将感知器描述为一种衡量权重决策的方法,它还有其它的用途,是当作基础逻辑门运算来用,如与门AND,或门OR,和与非门NAND。举个例子,假设我们有一个有两个输入的感知器,每个输入的权重为-2,还有一个偏差为3,如下图:
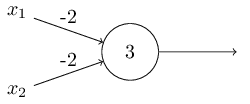
我们可以看到,如果输入00(x1=0,x2=0),输出为1,(-2)*0 + (-2)*0 + 3 = 3 > 0,这里*号为乘法运算,同样的输入01、10输出为1,但是输入11则输出0,(-2)*1 + (-2)*1 + 3 = -1 < 0,故此我们实现了一个与非门。
与非门的例子向我们展示了我们能够使用感知器来做简单的逻辑计算。事实上我们能使用感知器网络来计算一切的逻辑运算。原因是与非门在计算方面是通用的,也就是说,我们可以利用与非门来建立任何计算。比如,我们使用与非门来建立一个2位加法器,x1和x2,把x1和x2按位相加(x1⊕x2),包括当x1、x2都是1的时候需要设置为1的进位器,进位只是将x1、x2按位相乘:
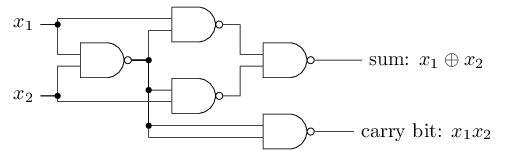
我们将所有的与非门替换成感知器,其中感知器有两个输入,每个输入的权重为-2,偏差值为3,可以得到一个功能等价的感知器网络,注意我将右下角的与非门往左移动了一点点,只是为了画箭头的时候容易一点点:
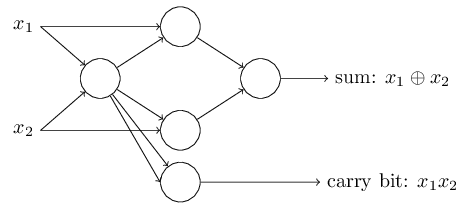
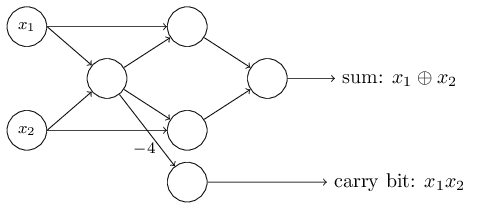
这个感知器网络值得注意的一点是最左边的感知器的输出作为最低端的感知器的输入被使用了2次,当我定义感知器模型的时候我并没有说过是否允许这种“两次输出到同一个地方”的情况。事实上,这并不重要,如果我们不想允许这种情况,那你可以简单地将这两条权重为-2的连接线合成一条权重为-4的,(如果你觉得不明显,你应该停下来自己证明一下,这是等价的)【证明:(x1⊕x2)*(-2) + (x1⊕x2)*(-2)+3 = 2*(-2)*(x1⊕x2)+3 = (-4)*(x1⊕x2) + 3)】有了这个变化,这个网络看起来如下图,标记的权重为-4,其余为-2,偏差值全都为3:
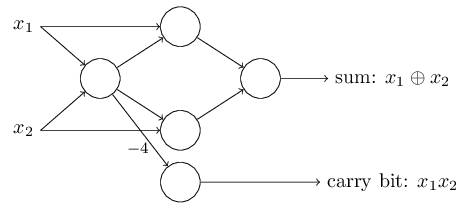
从现在开始,我将会在感知器网络的左边画上输入,像x1,x2一样的浮点型变量。事实上,我们通常都会画上一个额外的层——输入层来代表(原文为encode,我理解为着重代表输入的格式和形状,而不是对它们进行编码)输入数据:
表示方法为,它有一个输出,但是没有输入:
![]()
这是一种简单表示,实际上并不是一个没有输入的感知器。看到这个图形,假设我们确实有一个没有输入端的感知器,而它们的权重应该常为0,所以只要b>0,感知器将输出1,反之输出0。也就是说,这个感知器输出一个固定值,而不是我们想要的值(如x1,这是一个不确定的输入,因此不能把上面那个图形当作是一个没有输入的感知器),最好把这个符号当作根本不是一个感知器,而是一个输出x1,x2……的特殊单元。
这个加法器例子演示了一个感知器网络如何能够用来模拟有着许多与非门的电路,又因为与非门是运算通用的,从而那感知器也是运算通用的。
感知器的计算通用性既鼓舞人心又令人失望,鼓舞人心是因为这告诉我们感知器组成的网络能够像其它运算设备一样强大,但是它又看起来似乎只不过是一种新型的与非门,这不是什么大新闻。
但是!实际情况比这种观点所暗示的要好一点点。事实证明我们能够就此设计一个能够自动调节权重和偏差的人工神经网络的算法。这种调整发生在对外部刺激的响应中,无需程序员的直接干预。这些学习算法让我们能够以与传统逻辑门完全不同的方式使用人工神经元。无需显式布局与非等门的电路,我们的神经网络能够简单地学习解决问题——那些很难直接设计出常规电路的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号