算法一看就懂之「 排序算法 」
之前的文章咱们已经聊过了「 数组和链表 」、「 堆栈 」、「 队列 」和「 递归 」,这些要么是基础的数据结构,要么就是巧妙的编程方法。从今天起咱们来进入真正的算法阶段,看一看“排序算法”。排序算法有很多,如:「冒泡排序」、「插入排序」、「选择排序」、「希尔排序」、「堆排序」、「归并排序」、「快速排序」、「桶排序」、「计数排序」、「基数排序」等等。
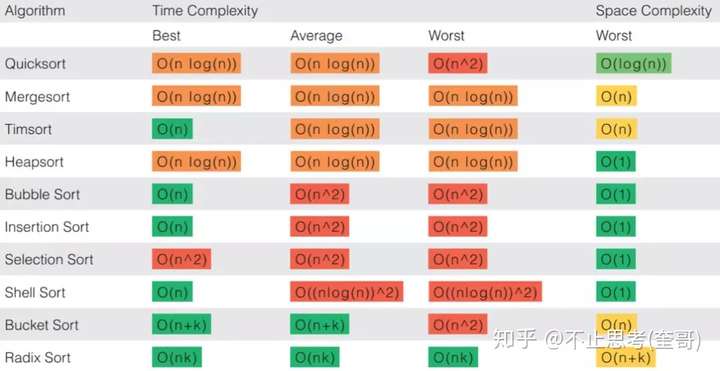
下图是常用排序算法的时间空间复杂度:
排序算法这么多,这里先将排序算法做个简单分类:
- 可以根据待排序的数据量规模分类:
- 内部排序:在排序过程中,待排序的数据能够被全部加载进内存中
- 外部排序:待排序的数据太大,不能全部同时放入内存,排序过程中需要内存与外部存储交换数据
- 可以根据排序的稳定性进行分类:
- 稳定性排序:冒泡排序、插入排序、归并排序
- 不稳定排序:快速排序、选择排序、希尔排序、堆排序
- 可以根据排序时间复杂度分类:
- O(N):桶排序、计数排序、基数排序
- O(NlogN):快速排序、希尔排序、归并排序、堆排序
- O(N*N):冒泡排序、插入排序、选择排序
- 基于算法思想分类:
- 基于分治:快速排序、归并排序
- 基于插入:希尔排序、插入排序
- 基于选择:堆排序、选择排序
- 基于交换:冒泡排序、快速排序
这些分类其实并没有那么严格,大多都是根据排序算法的特性总结的,不需要记住,搞懂了各种排序的特点之后也就自然而然的理解了。
这么多排序算法,我们应该怎么去评估它们呢?
一般而言,评估一个排序算法的质量主要从以下几个角度去看:
- 时间复杂度:
这是衡量算法性能的常规方法,对于排序算法当然也不例外,这也是衡量排序算法最重要的一个指标。在排序算法中常用的操作就是“比较”和“移动”元素,因此我们想优化某个排序算法的时间复杂度就是要减少去“比较”和“移动”元素的次数。
同时,由于需排序的数据不同会导致即使同一个算法也有着完全不同的时间消耗,因此我们还应该进一步分析排序算法的 最好时间复杂度、最坏时间复杂度,以及平均时间复杂度,以做到对排序算法特性的充分了解。 - 空间复杂度:
这个也是评价算法的另一个常规指标。需要分析执行算法所需要的辅助存储空间(原有数据已占用的空间不算)。如果空间复杂度为O(1)则说明执行算法的辅助存储空间为常量级别,很优秀。
对于「冒泡排序」、「插入排序」、「选择排序」等排序算法的空间复杂度都是O(1)。 - 排序的稳定性:
排序的稳定性是一个新的指标,对于排序算法来说非常的重要。
通俗的来讲就是:假如在待排序的数组中有相等的元素,则经过排序之后,这些相等的元素之间的原有顺序不被改变。
例如:待排序数组:1,3,6,5,6,2,9,经过从小到大的排序之后为:1,2,3,5,6,6,9
在原数组里面有2个6,分别位于数组的第二个位置和第四个位置(数组从第0位开始数),在排序后这2个6分为位于数组的第四个位置和第五个位置。注意重点来了,稳定性要求就是指原来那个第二位置的6是在第四个位置的6的前面的,所以排序完成之后,这两个6的相对向后顺序不能有变,因此位于新数组第四个位置的6必须是原来旧数组的第二个位置的那个6,新数组第五个位置的6必须是旧数组时第四个位置的那个6,虽然值一样,但是还是有区别的。你要说有啥区别?那再举个例子吧:
幼儿园一群小孩排队去领零食,刚开始是杂乱无章的排队的,后来老师说按照年龄大小排队,年龄小的排到前面去,这个时候就可以运用排序算法进行年龄的排序了。可是队伍中有2个同学小张和小赵年龄一样的,本来旧队伍的时候小张是排在小赵前面的,但是如果经过排序算法之后,把小张弄到了小赵的后面,这就不合理了,毕竟他们年龄一样,肯定是刚开始谁在前面就保持原样最好了,这就是体现出算法的稳定性的地方了。
对排序的稳定性要求是在实际应用中非常常见。 - 算法的复杂性:
算法本身的复杂度也会影响算法的性能(这里不是指的时间空间复杂度),这里指的算法设计思想的复杂度,后面我们在学习各种算法的时候就很清楚的看得到有的算法非常简单,有的算法设计的就比较复杂了。像「冒泡排序」、「插入排序」、「选择排序」这类都属于简单排序的算法。
以上,就是对数据结构中「 排序算法 」的一些思考,下一篇就从「冒泡排序」开始聊起。
码字不易啊,喜欢的话不妨转发朋友,或点击文章右下角的“在看”吧。😊
本文原创发布于微信公众号「 不止思考 」,欢迎关注。涉及 思维认知、个人成长、架构、大数据、Web技术 等。
作者微信公众号「 bzsikao 」,欢迎关注,交流更多的 互联网认知、工作管理、大数据、Web、区块链技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号